PR-104 "Video-to-Video Synthesis" Review (2018 NIPS)(GAN)
PR-104 "Video-to-Video Synthesis" Review (2018 NIPS)(GAN)

1. 발표 정리
citations : 2021.12.12 기준 608회
공식 논문 링크 NIPS 2018
https://papers.nips.cc/paper/2018/hash/d86ea612dec96096c5e0fcc8dd42ab6d-Abstract.html
Video-to-Video Synthesis
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
papers.nips.cc
Presentation Slide
https://www.slideshare.net/TaesuKim3/pr12-20180916-videotovideosynthesistaesu
PR12-104 Video-to-Video Synthesis
Paper review: "Video-to-video synthesis" by Ting-Chun Wang et al (NIPS2018) Presented at Tensorflow-KR paper review forum (#PR12) by Taesu Kim Paper link: ht…
www.slideshare.net
Contents
Vid2Vid 본 논문은 Pix2Pix (PR-065)에 기반을 둔 방법
Semantic map 영상을 구현 영상으로 Video를 생성하는 것이 목표
Edge-to-Face 합성 영상 생성
Multiple Output for Edge-to-Face 합성 영상 생성
Pose-to-Body Results 결과를 생성하기도 함
2018 Pix2PixHD (PR-065)
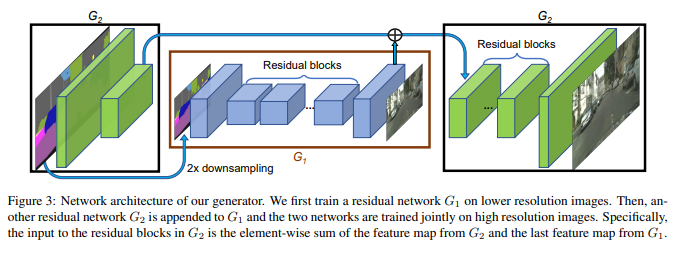
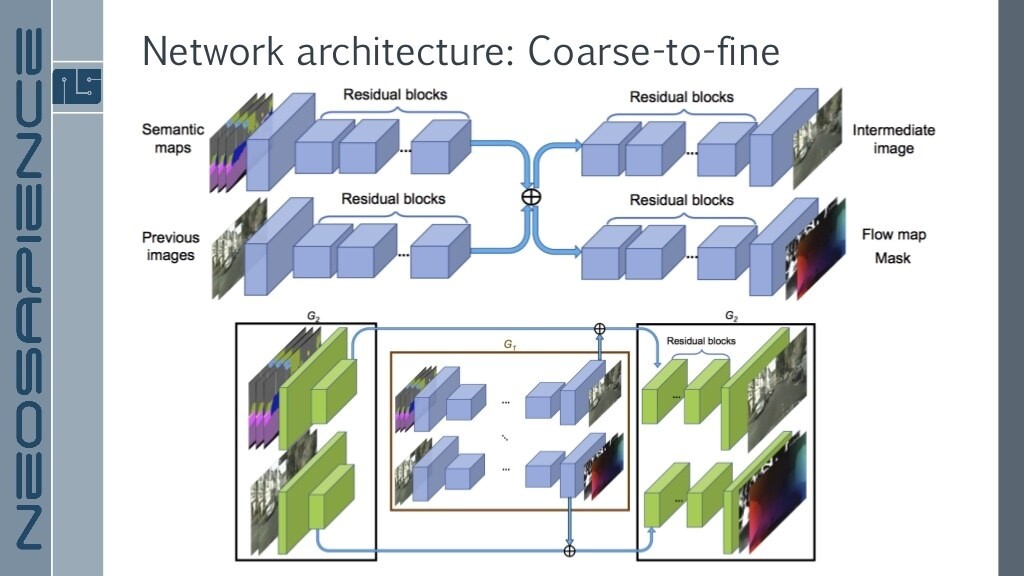
Pix2PixHD와 비슷한 구조를 가지는 Vid2Vid
frame에 대한 처리를 어떻게 할 것인지
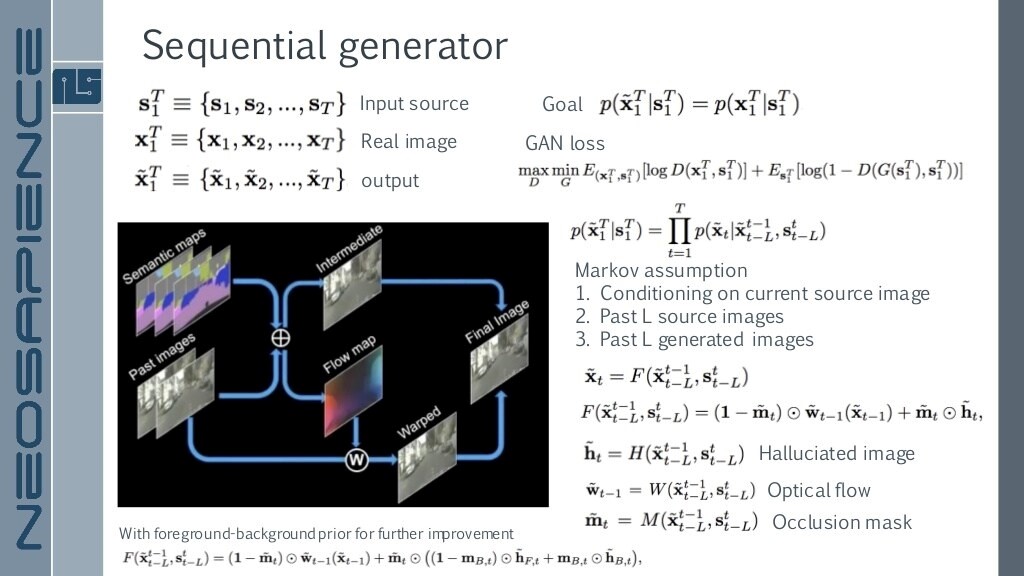
Goal : $$p(\tilde{x}_1^T | s_1^T) = p(x_1^T | s_1^T)$$
segmentation 값이 주어졌을 때 input의 값과 output의 값이 같도록 하는 것이 목표
Markov Assumption
(수식이 핵심인데 해석을 이해하기가 어렵네요.....)
현재와 과거의 것을 가지고 이미지 생성
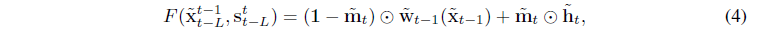
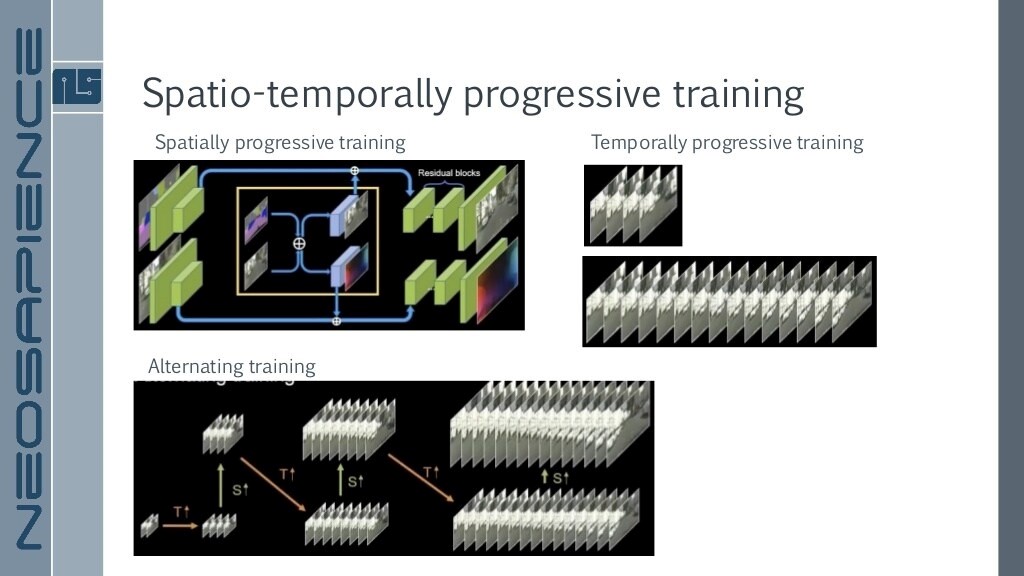
Sequence 2개짜리 Low Resolution짜리 학습 후 2배 Resolution 늘리고 Sequence 2배 늘리는 것으로 진행
Alternating training / Temporally progressive training

다른 스타일로도 적용이 가능
결론
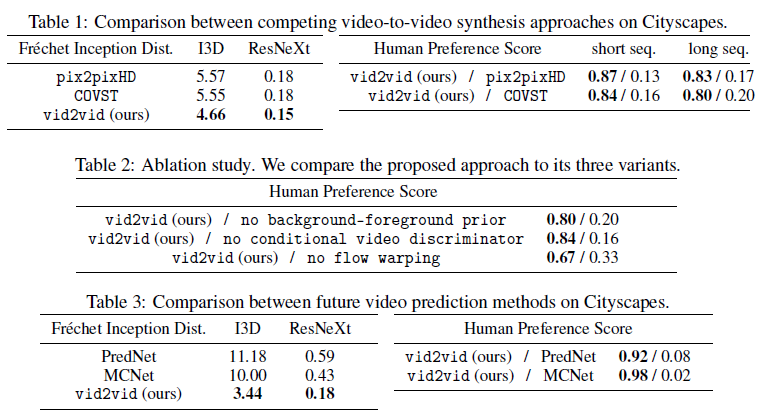
cGAN을 이용하여 General Video-to-Video 합성 프레임 워크가 가능하다.
고해상도, 사실적인 비디오 생성이 가능하다
단점
전체적으로 색이 바뀌는 듯한 일관성 없는 비디오 객체 생성이 되기도 한다.
artifact가 많이 생성되기도 함
참조
공식 YouTube (Short)
NVIDIA YouTube
공식 Github
https://github.com/NVIDIA/vid2vid
GitHub - NVIDIA/vid2vid: Pytorch implementation of our method for high-resolution (e.g. 2048x1024) photorealistic video-to-video
Pytorch implementation of our method for high-resolution (e.g. 2048x1024) photorealistic video-to-video translation. - GitHub - NVIDIA/vid2vid: Pytorch implementation of our method for high-resolut...
github.com
cf) Few-shot Video-to-Video Synthesis - NIPS2019
https://papers.nips.cc/paper/2019/hash/370bfb31abd222b582245b977ea5f25a-Abstract.html
Few-shot Video-to-Video Synthesis
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
papers.nips.cc
cf) 저자 중 한 사람 Jun-Yan Zhu
Pix2Pix, CycleGAN, Pix2PixHD, Vid2Vid etc....
https://www.cs.cmu.edu/~junyanz/
Jun-Yan Zhu's Homepage
Our lab studies the connection between Data, Humans, and Generative Models, with the goal of building intelligent machines, capable of recreating our visual world and helping everyone tell their visual stories. We focus on three directions: (1) We design n
www.cs.cmu.edu
