PR-111 "EVA2:Exploiting Temporal Redundancy in Live Computer Vision" Review (2018 ISCA)
PR-111 "EVA2:Exploiting Temporal Redundancy in Live Computer Vision" Review (2018 ISCA)
1. Citations & Abstract 읽기
Citations : 2021.12.21 기준 49회
저자
Mark Buckler - Cornell University
Philip Bedoukian - Cornell University
Suren Jayasuriya - Arizona State University
Adrian Sampson - Cornell University
Abstract

깊은 CNN을 위한 하드웨어 지원은 모바일과 임베디드 장치에서의 진보된 컴퓨터 비전에 매우 중요하다. 그러나 현재 디자인은 일반 CNN을 가소고하한다. 그들은 실시간 비전의 고유 특성을 활용하지 않는다. 우리는 대부분의 프레임에서 불필요한 계산을 피하기 위해 자연 비디오에서 시간적 중복 사용을 제안한다. 새로운 알고리즘인 Activation Motion Compensation (AMC, 활성화 모션 보상)은 시각 입력에서의 변화를 감지하고 이전에 계산된 활성화를 점진적으로 업데이트한다. 이 기술은 비디오 압축으로부터 영감을 받았고 시각적 변화에 적응하기 위해 잘 알려진 모션 추정 기술을 적용한다. 우리는입력이 변화함에 따라 효율성과 비전의 질 사이의 trade-off를 제어하기 위해 적응형 키 프레임율을 사용한다. 최신 CNN 가속기 설계의 확장으로 하드웨어에 이 기술을 시행한다. 새로운 유닛은 비전 정확도가 1% 미만인 3개의 CNN에 대해 프레임당 평균 에너지를 54%, 62%, 87%를 줄인다.
개인적인 정리
동기 : 모바일과 임베디드 장치에서 사용한 컴퓨터 비전용 가속기 장치가 부족하다.
제안 : 새로운 알고리즘 activation motion compensation (AMC)으로 감지와 업데이트를 진행하고 adaptive key frame rate를 사용함으로써 효율성과 시각적 질 간의 균형을 맞춤.
결과 : 균형을 맞춤과 동시에 필요 에너지를 감소시킴
2. 발표 정리
공식 논문 링크
https://www.cs.cornell.edu/~asampson/media/papers/eva2-isca2018.pdf
Presentation Slide
연결이 되지 않음.....
Contents
ISCA : computer architecture에서 최고 학회로 손꼽힘
학회 포커스가 Machine Learning으로 옮겨가는 추세 (2018년 기준임을 고려)
Exploit 최대로 잘 활용하다.
대부분의 시간이 소모되고 계산이 진행되는 곳은 CNN Prefix (VGG 같은 모델을 지칭).
Predicted Frame에 존재하는 Frame의 경우 유사하기 때문에 Key Frame에 있는 Input Frame처럼 모든 CNN 모델을 돌릴 필요가 없음.
Motion Estimation을 통해 Motion Vector Field를 구함. 이후 Target Activation과의 Motion Compensation을 통해 Predicted Activation을 도출해 냄.
이를 통해 계산량을 줄일 수 있다는 아이디어
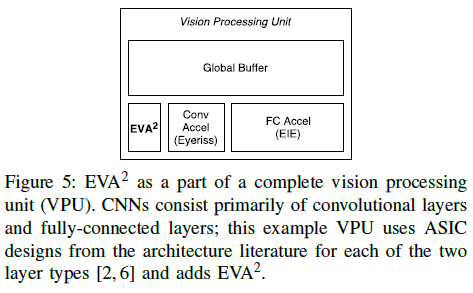
Activation Motion Compensation (AMC) : 소프트웨어
The Embedded Vision Accelerator Accelerator (EVAA) : 하드웨어
질문 1) 어떻게 Key Frame과 Predicted Frame을 선택할 것인가


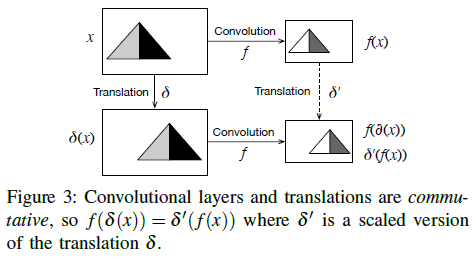
가정 : Key Frame에서 얼마만큼 움직였는가에 대해 계산하는 것은 Key Frame 계산에 나중에 움직인 만큼에 대한 계산을 더한 것과 같다.
where x: Key Frame, dx: movement
Convolutions and translations commute
convolution -> translation = translation -> convolution
꼭 그렇게 되지 않는데?
저자들도 인지
Perfect Motion Activation

Solution
1) Adaptive Key Frame Selection
2) Interpolated warping for precise execution
3) Careful target layer selection
Efficient Motion Estimation
Optical Flow Algorithm - pixel by pixel detect. 오히려 정확하지 않을 수 있음
Block Matching Algorithm 제안
Utilizing motion vectors in compressed video
Block Matching Algorithm
겹치는 곳은 그냥 가져다 쓰고 계산에서 제외 RFBME
Target Activation memory Issue
양이 많고 메모리에 많은 저장해야하는 문제가 발생
activation 0 값을 무시. 정확도에 크게 영향을 끼치지 않으므로 괜찮은 방법
Bilinear interpolation (cheap tech) 선택
Adaptive strategy vs Static Key Frame rate
Pixel compensation / Total motion magnitude
CNN 어디까지를 Prefix로 설정할 것인가
초기 CNN layer까지 설정하면 정확도는 향상. 그러나 에너지, 시간도 절약 효과가 적을 것
깊은 CNN layer까지 설정하면 predicted frame에서 계산량을 감소. 그러나 ativation warping이 불완전
"Deep Feature flow for video recognition" in CVPR, 2016에서 AMC에 대해서도 언급


Pixel Buffer에서 비교
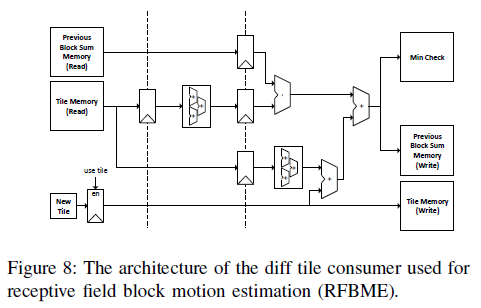
Tile 비교 -> Min Check
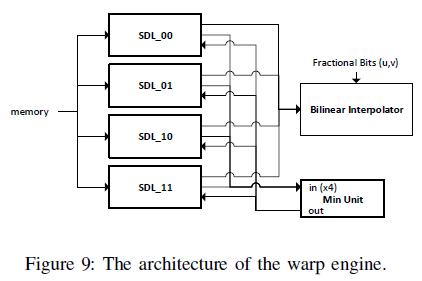
4개의 Tile을 Bilinear Interpolation으로 비교
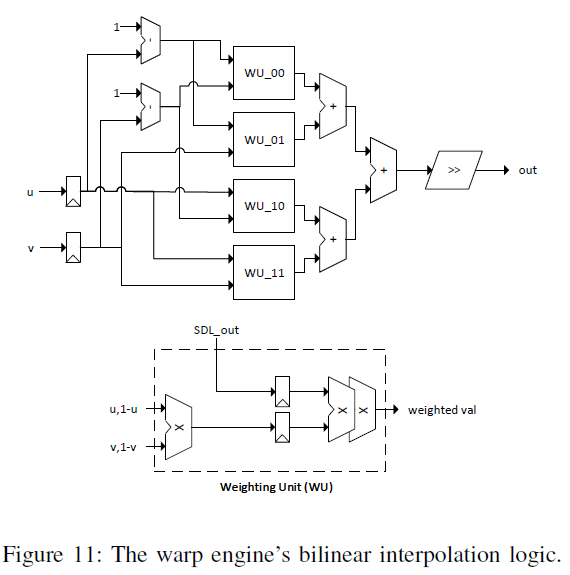
Activation 0을 다시 살려주는 작업도 진행해야함
Evaluation
1) First-Order Efficiency Comparison
2) Design Choices
3) Experimental Setup
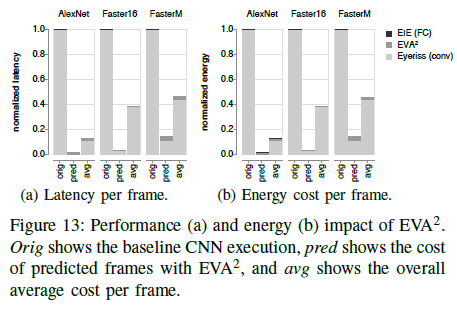
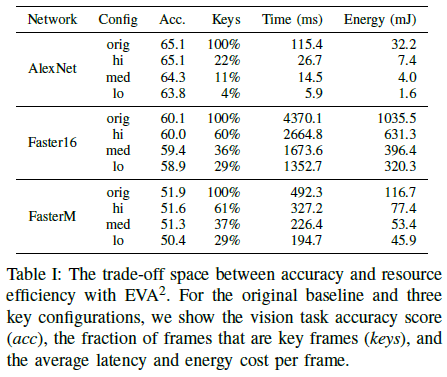
모델의 효과를 증명
Google Youtube Bounding Boxes Dataset
https://research.google.com/youtube-bb/
YouTube-BB Dataset | Google Research
YouTube-BoundingBoxes Dataset YouTube-BoundingBoxes is a large-scale data set of video URLs with densely-sampled high-quality single-object bounding box annotations. The data set consists of approximately 380,000 15-20s video segments extracted from 240,00
research.google.com
Baseline : Eyeriss & EIE
Networks : AlexNet & Faster R-CNN
Energy : 50~85% saving
Area : <5% Overhead
Latency : 50~85% saving
Accuracy : <1% Loss
Conclusion
1) Exploit Temporal Redundancy for Optimization
2) AMC & enable high efficiency & low accuracy loss
3) Universal Application (eg. classification, detection, segmentation)
