PR-205 "A Closer Look at Few Shot Classification" Review (2019 ICLR)(classification)
PR-205 "A Closer Look at Few Shot Classification" Review (2019 ICLR)(classification)
1. Citations & Abstract 읽기
Citations : 2022.01.25 기준 799회
저자
Wei-Yu Chen - Carnegie Mellon University
Yen-Cheng Liu & Zsolt Kira - Georgia Tech
Yu-Chiang Frank Wang - National Taiwan University
Jia-Bin Huang - Virginia Tech
Abstract

few-shot 분류는 제한된 레이블링된 예제를 포함하여 훈련 도중 보지 못한 class를 인지할 수 있도록 분류기를 학습시키는 것이 목표이다. 상당한 진전이 있었음에도, 네트워크 설계의 증가하는 복잡성, meta-learning 알고리즘, 실행 detail에서의 차이들은 공정한 비교를 어렵게 한다.
이 논문을 통해 우리는 3가지를 제시한다.
1) 몇 가지 대표적인 few-shot 분류 알고리즘의 일관된 비교 분석을 하며 그 결과는 더 깊은 backbone이 제한된 도메인 차이를 가진 데이터 세트의 방법들 간의 성능 차이를 크게 감소시킨다는 것을 보여준다.
2) min-ImageNet과 CUB 데이터 세트 모두에서 최신 모델과 비교했을 때 놀라운 비교 성능을 달성한 수정된 baseline 방법을 제안함.
3) few-shot 분류 알고리즘에서 cross-domain 일반화 능력을 평가하기 위한 새로운 실험 설정을 제시한다.
우리들의 결과는 feature backbone이 얕을 때는 내부 클래스 변동을 감소시키는 것이 중요한 요소지만 깊은 backbone에서는 중요하지 않다는 것을 보인다.
현실적인 cross-domain 평가 설정에서, 표준 fine-tuning 연습을 포함하는 baseline 방법이 다른 최신 few-shot 학습 알고리즘에 비해 유리하게 비교한다는 것을 보여준다.
favorably
1. 호의적으로, 호의를 가지고(with favor)
2. 유리하게, 순조롭게, (마침) 알맞게, 유망하게
2. 발표 정리
공식 논문 링크
https://openreview.net/forum?id=HkxLXnAcFQ
A Closer Look at Few-shot Classification
A detailed empirical study in few-shot classification that revealing challenges in standard evaluation setting and showing a new direction.
openreview.net
Presentation Slide
없음
Contents
ICLR 2019
간단하고 쉬운 논문
Few Shot Classiciation
PR-036 Learning to Remember Rare Events
PR-094 Model-Agnostic Meta-Learning for fast adaptation of deep networks
PR-153 SNAIL: A Simple Neural Attentive Meta-Learner
PR-165 Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
PR-168 Few Shot Unsupervised Image to Image Translation
PR-188 Online Meta-Learning
Few Shot Classification이란
매우 적은 예시만 보고 분류를 진행할 수 있는지를 확인하는 것.
Domain Adaptation vs Few Shot Classification
클래스 동일 vs 새로운 class
Few-shot classification aims to learn a classifier to recognize unseen classes during training with limited labeled examples.
1. Learning to Fine-tune
1) Learning Good Model Initilization 좋은 모델의 초기화
2) Learning an Optimizer 좋은 최적화
2. Learning to Compare
1) Distance Metric Learning
2) Cosine Similarity
3) Euclidean Distance
4) By Network
3. Learning to Augment
Limitations
1) 각자 너무 다른 실험 환경을 활용함.
2) Evaluation에서는 한계가 존재, 너무 작은 데이터 세트 -> 상대적으로 쉬운 작업

Transfer Learning-based Baseline
Training Stage: Train $f_\theta , W_b$
Fine-Tuning Stage : forward $f_\theta$, Fine-Tune $W_n$
Loss: Cross-Entropy Loss
Transfer Learning-based Baseline++
Cosine Similarity로 비교 -> softmax
Reduce Intra-Class Variations - 같은 클래스끼리는 뭉치게 함.
Meta Learning-based Few Shot Classification

MatchingNet : 단순히 비교하는 것
ProtoNet : mean feature와 비교
RelationNet : relation score를 가지고 비교
MAML(Model-Agnostic Meta Learning) :
Experiments
Mini-ImageNet, CUB 데이터 세트 활용
backbone : Conv-4
Adam Optimizer lr 1e-3
60,000(1-shot), 40,000(5-shot) meta-training & pick the model with best val. accuracy
Re-Implementation Setting
600번 실험 95% Confidence


Baseline++가 Baseline보다 좋음.
Reducing Intra-Class Variation is an important factor in the Few-Shot Classification

CUB: 깊이를 깊게 하는 경우 성능 차이가 줄어듬.
Mini-ImageNet : 성능 차이가 존재
두 데이터 세트에 대한 차이가 존재한다.
Domain Difference (도메인 차이)가 존재

Intra-Class Variation이 backbone이 깊어짐에 따라 줄어드는 지를 확인하는 Figure
Davies-Bouldin Index(1979) : Measure Intra-Group Separation

Mini-ImageNet 이후 CUB 사용한 경우 전반적인 성능은 하락하나 Baseline 성능이 가장 좋음.
도메인이 바뀌면 meta-learning으로 학습한 부분이 쓸모없어짐.
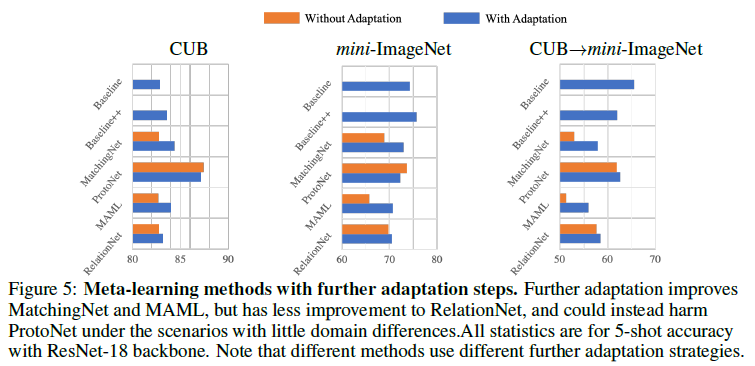
Summary
1) Baseline with data-augmentation performance
Baseline Performance is severely underestimated.
2) Baseline++ performance
Reducing Intra-Class Variation is an important factor in the Few-Shot Classification
3) Deeper Backbone Results
In the CUB dataset, the gap among existing methods would be reduced if backbone goes deeper
4) Cross-domain Results, Baseline outperforms
As the domain difference grows larger, the adaptation based on a few model class instances becomes more important.
5) MatchingNet, MAML performance increased after adpatation
Learning to learn adaptation in the meta-learning stage would be an improtant direction for future meta-learning research in few-shot classification
참조
GitHub
https://github.com/wyharveychen/CloserLookFewShot
GitHub - wyharveychen/CloserLookFewShot: source code to ICLR'19, 'A Closer Look at Few-shot Classification'
source code to ICLR'19, 'A Closer Look at Few-shot Classification' - GitHub - wyharveychen/CloserLookFewShot: source code to ICLR'19, 'A Closer Look at Few-shot Classification&...
github.com
블로그
[논문 리뷰] A Closer Look at Few shot Classification
submit: Chen, Wei-Yu, et al. ICLR (2019) paper: arxiv.org/abs/1904.04232 기존의 few-shot classification 알고리즘 비교 few-shot classification에 대한 baseline 모델 제안 1. Method Few-shot classificat..
22-22.tistory.com
