[논문 Summary] DDPM (2020 NIPS) "Denoising diffusion probabilistic models"
[논문 Summary] DDPM (2020 NIPS) "Denoising diffusion probabilistic models"

논문 정보
Citation : 2022.11.05 토요일 기준 660회
저자
Jonathan Ho, Ajay Jain, Pieter Abbeel
UC Berkeley
논문 링크
Official
https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf
Arxiv
https://arxiv.org/abs/2006.11239
Denoising Diffusion Probabilistic Models
We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound
arxiv.org
논문 Summary
Abstract

본 논문을 통해 non-equilibrium thermodynamics에서 영감을 얻은 diffusion probabilistic models을 활용하여 고품질의 이미지 합성을 보이고자 한다. diffusion probabilistic model과 Langevin dynamics를 활용하는 denoising score matching간의 새로운 연결을 통해 설계된 weighted variational bound를 훈련함으로써 가장 좋은 결과를 얻어내었고, 이는 본 모델이 auto-regressive decoding의 일반화로 해석될 수 있는 progressive lossy decompression 방식으로 보여질 수 있음을 인정한다.
LSUN에서 Progressive GAN과 비슷한 결과를 얻음.
0. 설명 시작 전 Overview
1. Introduction

GAN, autoregressive models, flows, VAE는 괄목할만한 이미지와 오디오 샘플들을 합성해왔다.
energy-based modeling과 score matching 역시 두괄할만한 향상을 보여왔다.
본 논문은 DPM(diffusion probabilistic model)의 진전됨을 보이고자 한다.
"Deep unsupervised learning using nonequilibrium thermodynamics", ICML 2015.
https://arxiv.org/abs/1503.03585
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
A central problem in machine learning involves modeling complex data-sets using highly flexible families of probability distributions in which learning, sampling, inference, and evaluation are still analytically or computationally tractable. Here, we devel
arxiv.org

DPM은 variational inference를 활용하여 훈련된 parameterized Markov chain이다.
signal이 파괴될 때까지 sampling의 반대 방향으로 noise를 점진적으로 추가하는 Markov chain을 진행하고 그 역을 통해 데이터를 샘플링한다. 소량의 Gaussian noise를 넣는 것만으로 간단한 NN parameterization이 가능하게 된다.
2. Background
Diffusion model은 궁극적으로 reverse process를 의미하는 $p_\theta (x_0)$를 찾는 것이다.
$$p_\theta (x_0) = \int p_\theta (x_{0:T}) dx_{1:T}$$
Forward process (Diffusion process)
$x_0$ 원본 이미지를 기준으로 점진적으로 Gaussian noise를 주입하여 최종적으로는 Isotropic Gaussian Distribution 이미지를 생성한다.
물론 이때 variance schedule $\beta_1, ..., \beta_T$에 따른 data에 Gaussian noise를 주입하는 Markov chain을 고정시킨다.
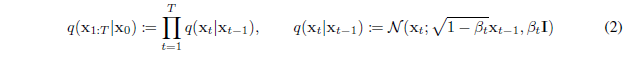
이때, $\sqrt{1-\beta_t}$로 scaling하는 이유는 variance가 발산하는 것을 막기 위함이다. 이를 통해 variance가 일정하게 유지될 수 있다. (https://happy-jihye.github.io/diffusion/diffusion-1/)
수학
$$Var(ax) = a^2 Var(x)$$
$$Var(x+y) = Var(x) + Var(y)$$
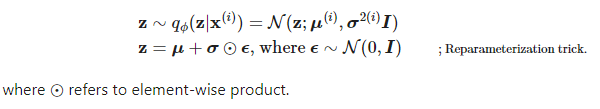
위를 기준으로 reparameterization하면 다음과 같다.
$$x_t = \sqrt{1-\beta_t}x_{t-1} + \sqrt{\beta_t} * \epsilon$$
$$Var(x_t) = Var(\sqrt{1-\beta_t}x_{t-1} + \sqrt{\beta_t})$$
여기서 $x_{t-1}=1로 가정$
$$Var(x_t) = Var(\sqrt{1-\beta_t}) + Var(\sqrt{\beta_t}) = (1-\beta_t)Var(1) + \beta_t Var(1) = Var(1)$$
$$\sqrt{1-\beta_t}^2 + \sqrt{\beta_t}^2 = 1$$
variances $\beta_t$는 reparameterization에 의해 학습할 수도 있고 hyperparameter인 상수로도 사용가능하다. (본 논문에서는 후자)

eq 2 증명) $q(x_{1:T} | x_0) = \prod_{t=1}^T q(x_t | x_{t-1})$
Markov chain에 따라 다음이 성립한다.
$q(x_T | x_{T-1}) = q (x_T | x_{T-1},x_{T-2},x_{T-3}, ... ,x_{1},x_{0})$
이를 활용하면 증명된다.
$$\prod_{t=1}^T q(x_t | x_{t-1}) = q (x_1 | x_0) q (x_2 | x_1) q (x_3 | x_2) \cdots q (x_T | x_{T-1}) = {q(x_1, x_0) \over q(x_0)} {q(x_2, x_1) \over q(x_1)} \cdots {q(x_T, x_{T-1}) \over q(x_{T-1})}$$
$$ = q (x_1 | x_0) q (x_2 | x_1, x_0) q (x_3 | x_2, x_1, x_0) \cdots q (x_T | x_{T-1}, ...., x_2, x_1, x_0) (\because Markov \quad chain)$$
$$ = {q(x_1, x_0) \over q(x_0)} {q(x_2, x_1, x_0) \over q(x_1, x_0)} {q(x_3, x_2, x_1, x_0) \over q(x_2, x_1, x_0)} \cdots {q(x_T, x_{T-1}, ..., x_2, x_1, x_0) \over q(x_{T-1}, ..., x_2, x_1, x_0)}$$
$$ = {q(x_T, x_{T-1}, ..., x_2, x_1, x_0) \over q(x_0)}$$
$$ = q(x_{1:T} | x_0)$$
$$\therefore q(x_{1:T} | x_0) = \prod_{t=1}^T q(x_t | x_{t-1})$$
eq 4 증명) $q(\mathbf{x}_t \vert \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I})$
$\begin{aligned} \mathbf{x}_t &= \sqrt{1-\beta_t}\mathbf{x}_{t-1} + \sqrt{\beta_t}\boldsymbol{\epsilon}_{t-1} \\ &= \sqrt{\alpha_t}\mathbf{x}_{t-1} + \sqrt{1 - \alpha_t}\boldsymbol{\epsilon}_{t-1} \\ & \quad \text{ where } \alpha_t = 1 - \beta_t, \boldsymbol{\epsilon}_{t} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\ &= \sqrt{\alpha_t}(\sqrt{\alpha_{t-1}}\mathbf{x}_{t-2} + \sqrt{1 - \alpha_{t-1}}\boldsymbol{\epsilon}_{t-2}) + \sqrt{1 - \alpha_t}\boldsymbol{\epsilon}_{t-1} \\ &= \sqrt{\alpha_t \alpha_{t-1}} \mathbf{x}_{t-2} + \sqrt{\alpha_t(1 - \alpha_{t-1}) + (1-\alpha_t)}\bar{\boldsymbol{\epsilon}}_{t-2} \\ & \quad \text{ where } \bar{\boldsymbol{\epsilon}}_{t-2} \text{ merges two Gaussians (*).} \\ &= \sqrt{\alpha_t \alpha_{t-1}} \mathbf{x}_{t-2} + \sqrt{1 - \alpha_t \alpha_{t-1}} \bar{\boldsymbol{\epsilon}}_{t-2} \\ &= \dots \\ &= \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon} \\ & \quad \text{ where } \bar{\alpha}_t = \prod_{i=1}^t \alpha_i \\ \therefore q(\mathbf{x}_t \vert \mathbf{x}_0) &= \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I}) \end{aligned}$
If X1 ~ Gaussian (mean1, std1), X2 ~ Gaussian (mean2, std2),
X1+X2 ~ Gaussian (mean1+mean2, $\sqrt{(std1^2 + std2^2)}$)
Reverse process
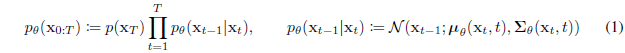
eq 1 증명) $p_\theta(x_{0:T}) = p_\theta(x_T) \prod_{t=1}^Tp_\theta(x_{t-1} | x_{t})$
이 역시 eq 2 증명과 마찬가지로 Markov chain을 활용하여 증명한다.
$$\prod_{t=1}^Tp_\theta(x_{t-1} | x_{t}) = p_\theta (x_0 | x_1) p_\theta (x_1 | x_2) p_\theta (x_2 | x_3) \cdots p_\theta (x_{T-1} | x_{T})$$
$$ = p_\theta (x_0 | x_1, x_2, x_3, ..., x_T)p_\theta (x_1 | x_2, x_3..., x_T)p_\theta (x_2 | x_3, ..., x_T) \cdots p_\theta (x_{T-1} | x_{T})$$
$$ \because Markov \quad chain$$
$$ = {p_\theta(x_0, x_1, x_2, ..., x_T) \over p_\theta(x_1, x_2, ..., x_T)} {p_\theta(x_1, x_2, ..., x_T) \over p_\theta(x_2, ..., x_T)} \cdots {p_\theta(x_T, x_{T-1}) \over p_\theta(x_{T})}$$
$$ = {p_\theta(x_0, x_1, x_2, ..., x_T) \over p_\theta(x_T)} = {p_\theta(x_{0:T}) \over p_\theta(x_T)} = \prod_{t=1}^Tp_\theta(x_{t-1} | x_{t})$$
$$\therefore p_\theta(x_{0:T}) = p_\theta(x_T) \prod_{t=1}^Tp_\theta(x_{t-1} | x_{t})$$
Training
훈련은 Negative Log Likelihood(NLL)의 variational bound를 최적화하는 방향으로 수행된다.
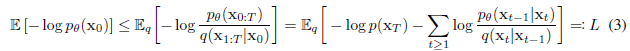
upper bound에 대하여 Appdendix A와 같이 정리하면 식 5와 같이 정리된다.

cf) Markov chain property
식 (19) -> 식 (20)
$$ q(x_t | x_{t-1}) = q(x_t | x_{t-1}, x_0) = q(x_{t-1} | x_t, x_0) { q(x_{t} | x_0) \over q(x_{t-1} | x_0) }$$

이때 L을 stochastic gradient descent와 함께 최적화하면 된다.

Proof. $ q(x_{t-1} | x_t, x_0)$

3. Diffusion models and denoising autoencoders
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
What are Diffusion Models?
[Updated on 2021-09-19: Highly recommend this blog post on score-based generative modeling by Yang Song (author of several key papers in the references)]. [Updated on 2022-08-27: Added classifier-free guidance, GLIDE, unCLIP and Imagen. [Updated on 2022-08
lilianweng.github.io
3.1 Forward process and $L_T$
forward process에서 variance $\beta_t$는 reparameterization에 의해 학습가능하나 상수로 활용한다.
이에 따라 식 (5)의 $L_T$는 상수항이 되고 무시가능하다.
3.2 Reverse process and $L_{1:T-1}$
variance는 $\sum_{\theta} (x_t,t)=\sigma_t^2 I$로 $\beta_t$와 $\tilde{\beta_t}$가 가의 비슷하기 때문에 훈련시키지 않는다.
따라서 $L_{t-1}$을 다음과 같이 표현할 수 있다.
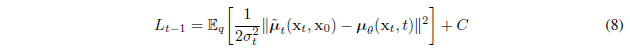
식 4에서 언급했듯 $x_t = \sqrt{\bar{\alpha_t}}x_0 + \sqrt{1 - \bar{\alpha_t}}\epsilon$과 같이 표현가능하다.
이를 $x_0$에 대해 나타내면 다음과 같다.
$$x_0 = {1 \over \sqrt{\bar{\alpha_t}}} (x_t - \sqrt{1 - \bar{\alpha_t}}\epsilon)$$

식 7에 $x_0$를 넣고 정리하면 식 10

예측값과 동일하게 진행되어야 하므로 식 11 성립
Langevin dynamic를 닮도록 식 11을 parameterization하여 식 10을 정리하면 식 12
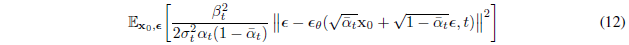
t에 대한 denoising score matching을 닮음
3.3 Data scaling, reverse process decoder, and $L_0$
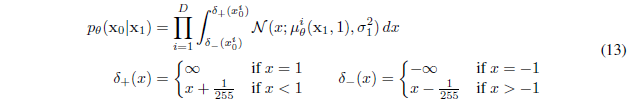
3.4 Simplified training objective
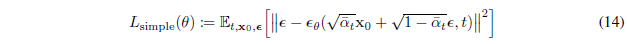
위와 같은 variational bound처럼 simplified된 식을 사용하는 것이 효과적이다.

Algorithm 1을 통해 간단한 objective로 완성된 훈련 절차를 보인다.

식 14는 식 12에서 앞의 weighting(coefficient term)을 제거한 간단화된 objective이다.
diffusion process에서 simplified objective로부터 작은 t에 상응하는 down-weight loss term을 만든다. 이 term은 매우 작은 noise로부터 데이터를 denoise하도록 network를 훈련시킬 뿐 아니라 큰 t에 대해서도 network가 어려운 denoising 작업에 집중하게 해 유용하게 한다.
4. Experiments
T=1000
$\beta_1 = 10^{-4}$, $\beta_T=0.02$ increasing linearly
unmasked PixelCNN++와 유사한 U-Net backbone을 사용하며 이때 group normalization 활용
time을 공유하며 Transformer sinusoidal position embedding을 사용하여 network를 구성
16x16 feature map resolution에서 self-attention 사용
Appendix B 참조 (자세히 나옴)
4.1 Sample quality

Appendix D 참조
4.2 Reverse process parameterization and training objective ablation
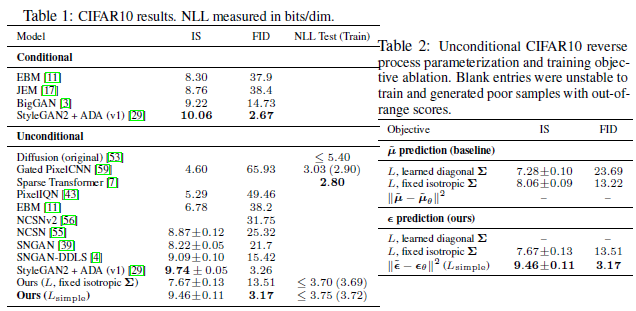
reverse proccess variances를 학습하는 것은 고정된 variance 대비 학습에 불안정성을 높이고 품질 또한 좋지 않다.
Table 2에서 확인할 수 있듯 fixed variance로 variational bound로 훈련시킬 때 $\tilde{\mu}$를 예측하는 것만큼 simplified objective와 함께$\epsilon$을 예측하는 것이 더 성능이 좋다.
4.3 Progressive coding
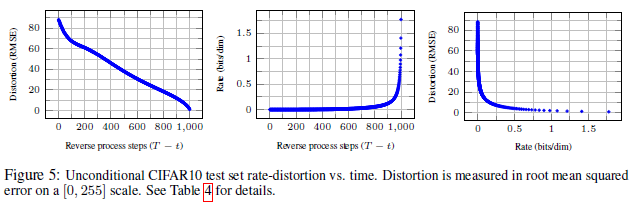


4.4 Interpolation

Reference
공식 Github
https://github.com/hojonathanho/diffusion
GitHub - hojonathanho/diffusion: Denoising Diffusion Probabilistic Models
Denoising Diffusion Probabilistic Models. Contribute to hojonathanho/diffusion development by creating an account on GitHub.
github.com
도움이 되는 YouTube 1. Diffusion Model 수학이 포함된 tutorial
도움이 되는 YouTube 2. PR-409 - Hyeongmin Lee
도움이 되는 YouTube 3. Outlier - Diffusion Models | Paper Explanation | Math Explained
도움이 되는 블로그 1. lilianweng 블로그 (영문)
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
What are Diffusion Models?
[Updated on 2021-09-19: Highly recommend this blog post on score-based generative modeling by Yang Song (author of several key papers in the references)]. [Updated on 2022-08-27: Added classifier-free guidance, GLIDE, unCLIP and Imagen. [Updated on 2022-08
lilianweng.github.io
도움이 되는 블로그 2. happy-jihye 블로그
https://happy-jihye.github.io/diffusion/diffusion-1/
[Paper Review] DDPM: Denoising Diffusion Probabilistic Models 논문 리뷰
jihye’s study blog
happy-jihye.github.io
도움이 되는 블로그 3.
https://developers-shack.tistory.com/8
[논문공부] Denoising Diffusion Probabilistic Models (DDPM) 설명
─ 들어가며 ─ 심심할때마다 아카이브에서 머신러닝 카테고리에서 그날 올라온 논문들이랑 paperswithcode를 봅니다. 아카이브 추세나 ICLR, ICML 등 주변 지인들 학회 쓰는거 보니까 이번 상반기에
developers-shack.tistory.com
0000
