[논문 Summary] DreaMoving (2023.12 Arxiv) "DreaMoving: A Human Video Generation Framework based on Diffusion Models"
[논문 Summary] DreaMoving (2023.12 Arxiv) "DreaMoving: A Human Video Generation Framework based on Diffusion Models"
논문 정보
Citation : 2024.03.12 화요일 기준 1회
저자
Mengyang Feng, Jinlin Liu, Kai Yu, Yuan Yao, Zheng Hui, Xiefan Guo, Xianhui Lin, Haolan Xue, Chen Shi, Xiaowen Li, Aojie Li, Xiaoyang Kang, Biwen Lei, Miaomiao Cui, Peiran Ren, Xuansong Xie
- Alibaba Group
논문 & Github 링크
Official
Arxiv
https://arxiv.org/abs/2312.05107
DreaMoving: A Human Video Generation Framework based on Diffusion Models
In this paper, we present DreaMoving, a diffusion-based controllable video generation framework to produce high-quality customized human videos. Specifically, given target identity and posture sequences, DreaMoving can generate a video of the target identi
arxiv.org
공식 Github
https://dreamoving.github.io/dreamoving/
DreaMoving
Project page for DreaMoving.
dreamoving.github.io
https://huggingface.co/spaces/jiayong/Dreamoving
논문 Summary
Abstract

고품질 customized human video 생성을 위해 제어가능한 diffusion 기반 video generation framework인 DreaMoving 제안.
target identity와 posture sequence가 주어졌을 때, target identity moving이나 dancing video 생성이 가능하다.
추가 제안 모듈 : motion-controlling을 위한 Video ControlNet & identity preserving을 위한 Content Guider

0. 설명 시작 전 Overview
1. Introduction
T2V의 진전에도 인간 중심 기반 생성에는 어려움을 겪는 중.
open-source human dance video dataset의 부족, text 묘사의 어려움으로 인해 frame간 일관성, 긴 길이, 다양성을 포함한 비디오 생성에 어려움을 겪는다.
personalization과 controllability 의 어려움 또한 존재
구조적 제어를 위한 ControlNet, appearance 제어를 위한 Dreambooth, LoRA
그러나 이 기술들은 정확한 제어가 어렵고 hyperparameter tuning 요소가 존재 & 추가 계산 부담
이에 새로운 방법론인 DreaMoving 제안
2. Architecture
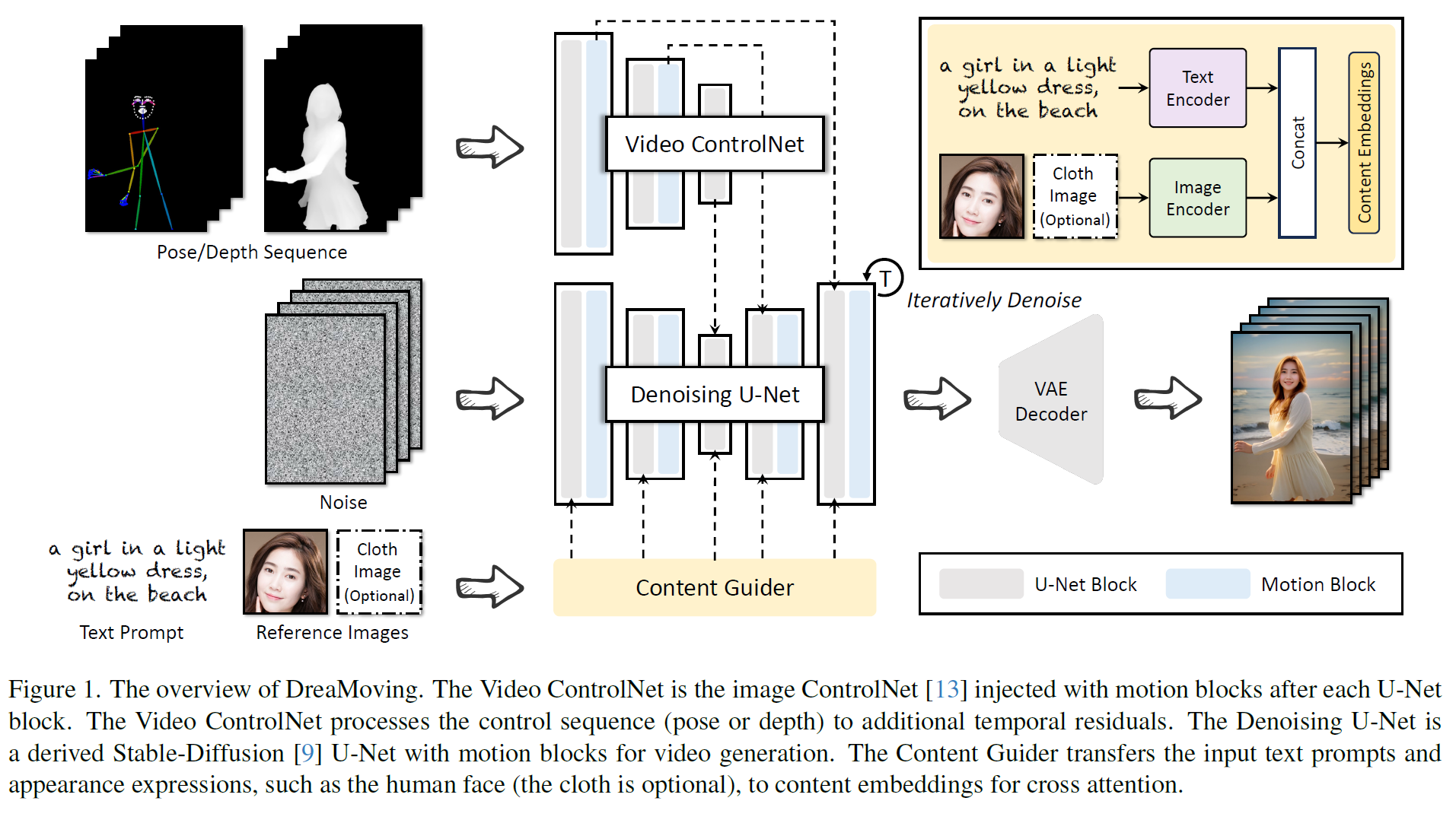
LDM 기반 모델을 기반으로 3가지 주요 network로 구성 : U-Net, Video ControlNet, Content Guider
AnimateDiff에서 영감을 받아 U-Net 각 block 이후 motion block을 추가
Plug-in : motion-controlling을 위한 Video ControlNet & identity preserving을 위한 Content Guider
2.1 Data Collection and Preprocessing
인터넷에서 human dance video 1000의 고품질 영상으로 훈련
temporal module 훈련은 변이나 특별한 효과 없는 연속적 frame이 필요하기 때문에 clip video로 split하여 6000개의 짧은 비디오를 획득한다.(8~10s)
text description을 위해서 Minigpt-v2를 video-captioner로 사용
- “[grounding] describe this frame in a detailed manner”의 명령으로 획득
- subject와 background 내용에 대해 정확히 묘사
2.2 Motion Block
temporal consistency와 motion fidelity 향상을 위해서 U-Net과 ControlNet를 motion block으로 통합.
motion block은 AnimateDiff로 확장. temporal sequence length는 64로 확장
초기화 : AnimateDiff (mm_sd_v15.ckpt)
개인 인물 dance video로 finetuning
2.3 Content Guider
Content Guider는 인물의 appearance와 배경을 포함한 생성된 video의 내용을 제어하기 위해 고안됨.
가장 간단한 방법은 text prompt이지만 개인화된 인물 외관 묘사가 어렵다.
IP-Adapter에 영감을 받아 image prompt를 활용해 인물 외관에 대한 guidance를 주고 배경에 대해서는 text prompt 사용
얼굴 이미지는 image encoder를 통해 encode
text feature & 인물 외관 feature는 마지막 content embedding에 concat된 후 cross-attention에 보냄
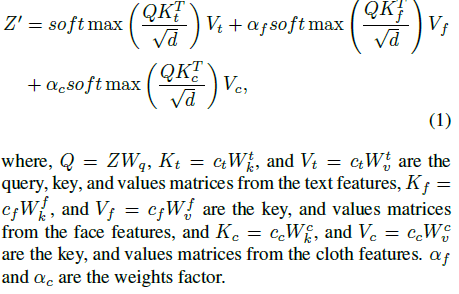
$Z$ : query features
$c_t$ : text features / $c_f$ : face features / $c_c$ : cloth features
$Z^\prime$ : cross-attention output
2.4 Model Training
2.4.1 Content Guider Training
Base Model : SD v1.5 기반
Image Encoder : OpenCLIP ViT-H14
reference face identity 보존을 위해 Arcface를 통해 얼굴 상관 feature 추출.
LAION-2B에서 human data 수집
훈련 : 512x512 random crop & resize
GPU : 8 V100, 100k steps, 16 batch size/GPU 1장
Optimizer : AdamW
learning rate : 1e-4, decay 1e-2
2.4.2 Long-Frame Pretraining
WebVid-10M validation set (5k video clips)에서 motion module의 sequence length를 16에서 64로 확장하기 위한 training stage 수행
U-Net motion module만 훈련하고 나머지는 freeze
ControlNet이나 image guidance 사용 안 함.
learning rate : 1e-4
resolution : 256x256 resize & center crop
batch size 1, 10k steps 이후 훈련 종료
2.4.3 Video ControlNet Training
long-frame pretraining 이후, Video ControlNet 훈련 진행.
U-Net 고정 & Video ControlNet의 U-Net block과 motion block은 unfreeze
수집한 6k human dance video data 훈련
DWPose나 ZoeDepth를 통한 human pose 또는 depth를 추출.
learning rate : 1e-4
resolution : 352x352
batch size 1, 25k steps 이후 훈련 종료
2.4.4 Expression Fine-Tuning
사람 표현을 더 낫게하기 위해 Video ControlNet을 포함한 U-Net의 motion block 구조에서 6k human dancing video data로 추가 fine-tuning
U-Net motion block weight만 update
learning rate : 5e-5
resolution : 512x512
batch size 1, 20k steps 이후 훈련 종료
2.5 Model Inference
입력 : text prompt, reference image, pose/depth sequence
Video ControlNet control scale : 1 (pose/depth에서만)
multi-controlnet을 통해 pose & depth 동시 사용 가능
Eq 1의 face/body guidance strength : $\alpha_f,\alpha_c$는 적응하도록
text prompt만 사용할 때 $\alpha_f=\alpha_c=0$
.




