[논문 Summary] "Beyond Surface Statistics: Scene Representations in a Latent Diffusion Model" (NIPS 2023 Workshop)
[논문 Summary] "Beyond Surface Statistics: Scene Representations in a Latent Diffusion Model" (NIPS 2023 Workshop)
논문 정보 (Citation, 저자, 링크)
Citation : 2024.06.16 일요일 기준 6회
저자 (소속) : ( Yida Chen, Fernanda Viégas, Martin Wattenberg ) [Harvard University]
논문 & Github 링크 : [ Official ] [ Arxiv ] [ 공식 Github ]
논문 Summary
0. 설명 시작 전 Overview

1. Introduction

본 연구에서 LDM가 2차원으로 묘사한 객체들의 내부 3D 표현을 생성할 수 있는지 의문을 가졌다.
질문에 답하기 위해, linear probing 방법론을 사전 학습된 LDM에 적용했고, 연속적인 depth map과 주요 객체/배경 구분의 선형 표현을 발견했다. 추가적인 실험을 통해 두 표현이 모델 출력에 미치는 인과적 역할을 추가로 밝혔습니다.
또한, 이는 denoising process의 초기 단계에서 나타남.
본 저자들은 3D 기하학의 간단한 선형적 표현이 LDM 이미지 합성의 인과적 역할을 한다는 발견이 결국 신경망 네트워크가 이미지 합성의 맥락 속에서 world model을 생성하는 법을 학습한다는 추가적인 증거를 제공한다.
( Our findings—that a simple linear representation of 3D geometry plays a causal role in LDM image synthesis—provide additional evidence that neural networks learn to create world models in the context of image synthesis )
2. Background
Probing Classifier는 딥러닝 신경망이 학습한 표현을 해석하는 데 사용함. 신경망의 중간 activation을 입력으로 받아 특정 속성을 추론함.
3. Probing for discrete and continuous depth
depth 표현과 관련한 2가지 관점에 대해 조사
(1) Discrete binary Depth : 사람 인지 관점 (3.2)
(2) Continuous Depth : 3D 기하학 관점 (3.3)
3.1 Synthetic dataset
probing 실험을 위한 데이터 세트 구성
1000장의 이미지 SD에서 생성. (linear multi-step scheduler, 15steps)
이미지의 질과 다양성을 보장하기 위해, LAION-AESTHETICS v2 prompt sampling
주요 객체/배경 레이블은 TRACER 모델(salient object detection)을 사용하여 생성. 깊이 레이블은 MiDaS 모델(monocular depth estimation, 단일 이미지/ 단일 카메라 기반 depth 추정)을 통해 추정.
참조)
stereo depth estimation : stereo vision 두 개 이상의 이미지 기반 depth 계산
부적절한 콘텐츠나 왜곡된 객체가 포함된 이미지를 수동으로 제외
최종 데이터셋은 617개의 샘플로 구성. (train 246, test 371)
3.2 Binary depth: salient object and background
LMD 내 binary depth representation 조사
sampling stept $t$, self-attention layer $l$의 중간 output : $\epsilon_{\theta(l,t)}$
중간 output 으로 훈련된 linear classifier $p_b$ : salient와 background class를 위한 pixel-level logit $\hat{d_b}$ (channel 512 x 512 x 2)예측을 위해 진행.
2 channel은 salient와 background class 분류

gradient descent를 활용한 $W$ update
- Cross Entropy loss $\hat{d_b}$ and the synthetic label $d_b$.

3.3 Continuous relative depth information
LMD 내 fine-grained depth 차원에 대한 조사
self-attention layer 중간 feature을 사용하여 MiDaS relitive depth map $d_c$ 예측하는 선형 회귀 모델을 훈련

optim : Huber loss
depth probing acc : RMSE
4. Linear Representations of Depth and Salient Objects

초기 5step에서 상당한 성능 향상을 보이고 이후는 수렴
salient object segmentation에서 평균 Dice 계수 0.85, depth estimation에서 평균 RMSE 0.47을 달성

4.1 Depth emerges at early denoising steps
초기 5 step동안 probing 성능이 급격히 증가.
the depth dimension develops at a stage when the decoded image still appears extremely noisy to a human.
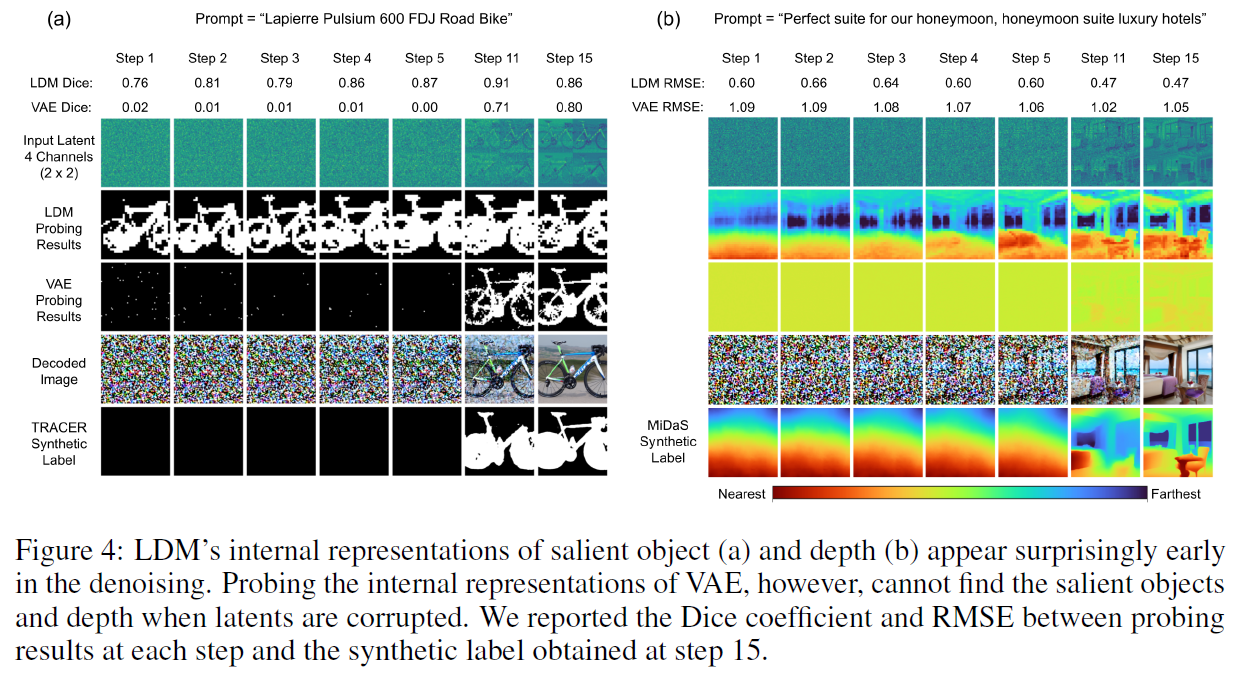
LDM이 VAE보다 더 강력한 깊이 표현을 가지고 있음
4.2 Is depth represented in latent space?

VAE bottleneck does not contain a significant linear representation of depth early in the denoising process
모든 경우에서, LDM이 더 강력한 depth representation을 가지고 있음을 보임
5. Causal Role of Depth Representation
Probing 실험은 LDM 내부 표현과 최종 이미지의 depth 간 강한 상관관계가 있음을 보임.
본 section에서 LDM의 내부 표현과 모델 출력 간의 인과 관계를 조사
5.1 Intervention experiment
목표: 동일한 프롬프트와 초기 입력을 사용하여 depth representation을 변경할 때, 출력 이미지의 depth에 상응하는 변경이 결과 이미지에도 발생하는지 확인
reference : 수정된 salient object maks $d_b^prime$ (랜덤하게 수직/수평 방향으로 이동된 mask)
LMD representation 수정, $p_b$는 frozen 상태에서 internal representation update, Adam

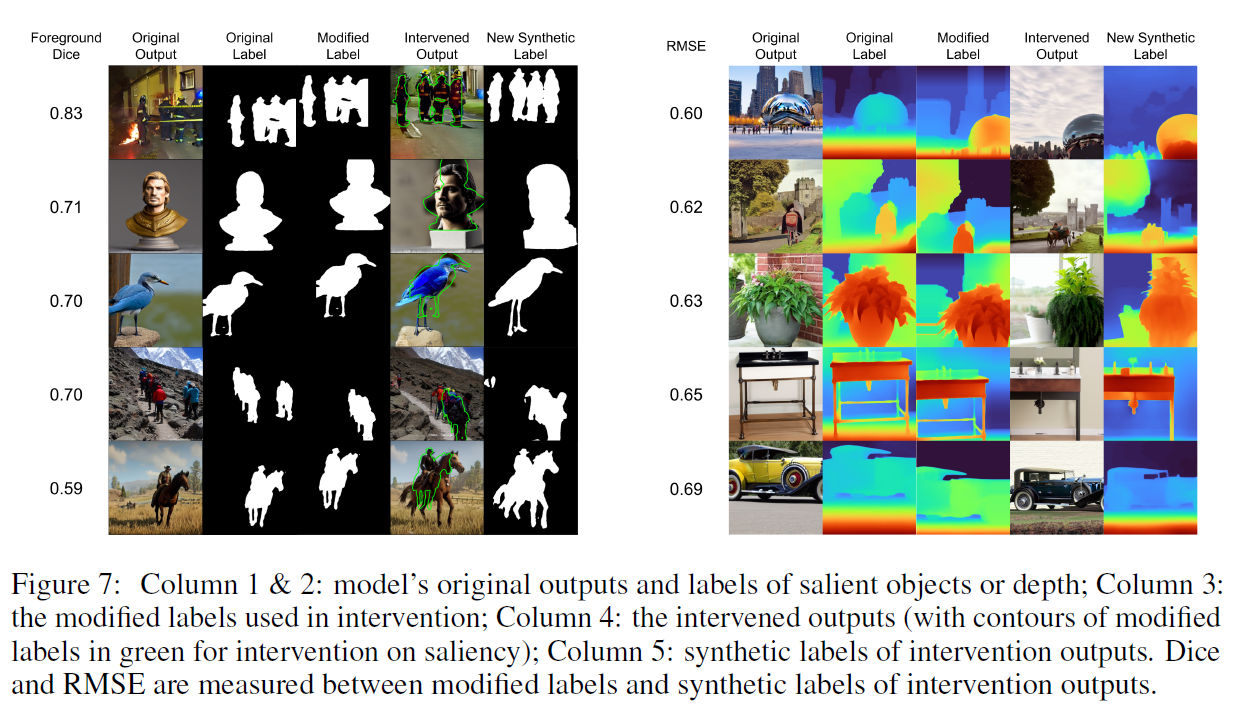
Salient object intervention results : 이 모델 출력에 인과적 역할을 한다
Depth intervention results : 깊이 표현이 모델 출력에 인과적 역할을 한다
