[Pytorch] Multi-GPU 사용하는 방법
[Pytorch] Multi-GPU 사용하는 방법
방법 1 : 가장 쉽지만 메모리 불균형이 생김
일반적으로 하나의 GPU에서는 다음과 같이 사용합니다.
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Mymodel().to(device)그러나 여러개의 GPU 사용에 있어서는 다음과 같은 방법을 사용합니다.
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Mymodel()
if (device.type == 'cuda') and (torch.cuda.device_count() > 1):
print('Multi GPU activate')
net = nn.DataParallel(netG, device_ids=list(range(NGPU)))
model.to(device)해당 예제 Tutorial은 아래 URL을 참조하시길 바랍니다.
tutorials.pytorch.kr/beginner/former_torchies/parallelism_tutorial.html
멀티-GPU 예제 — PyTorch Tutorials 1.6.0 documentation
Shortcuts
tutorials.pytorch.kr
tutorials.pytorch.kr/beginner/blitz/data_parallel_tutorial.html
선택 사항: 데이터 병렬 처리 (Data Parallelism) — PyTorch Tutorials 1.6.0 documentation
Note Click here to download the full example code 선택 사항: 데이터 병렬 처리 (Data Parallelism) 글쓴이: Sung Kim and Jenny Kang 번역: ‘정아진 ’ 이 튜토리얼에서는 DataParallel (데이터 병렬)
tutorials.pytorch.kr
해당 방법은 model을 분산하는 pytorch 기반 기본 data parallel 방법으로 가장 쉽고 빠릅니다. 그러나 저의 경우 해당 방법으로는 데이터 불균형이 일어났습니다.
'왜일까'하고 생각하며 조사해보니 아래와 같은 답을 얻을 수 있었습니다.
torch 코드에 언제 to(device) 혹은 cuda()를 붙인다고 생각하시나요
바로 model, loss, tensor 이 3개의 상황에서 cuda를 사용합니다. model의 경우에는 위 방법으로 해소가 되고 tensor는 그 크기가 작아 크게 영향을 끼치지 않으나 loss의 경우는 하나의 device에 몰리게 되어 GPU Memory 불균형이 생깁니다.
바로 이 문제를 해결하면 불균형이 해소된다고 저는 보고있습니다.
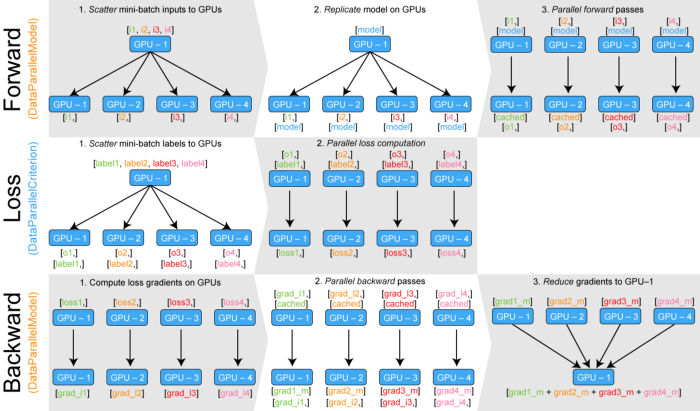
해당 내용과 관련하여 아래 블로그를 참조하시길 바랍니다.(영어는 함정)
💥 Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
Training neural networks with larger batches in PyTorch: gradient accumulation, gradient checkpointing, multi-GPUs and distributed setups…
medium.com
방법 2. Custom DataParallel을 활용한 loss function parallel 만들기
URL : github.com/zhanghang1989/PyTorch-Encoding/blob/master/encoding/parallel.py
zhanghang1989/PyTorch-Encoding
A CV toolkit for my papers. Contribute to zhanghang1989/PyTorch-Encoding development by creating an account on GitHub.
github.com
from parallel import DataParallelModel, DataParallelCriterion
parallel_model = DataParallelModel(model) # Encapsulate the model
parallel_loss = DataParallelCriterion(loss_function) # Encapsulate the loss function
predictions = parallel_model(inputs) # Parallel forward pass
# "predictions" is a tuple of n_gpu tensors
loss = parallel_loss(predictions, labels) # Compute loss function in parallel
loss.backward() # Backward pass
optimizer.step() # Optimizer step
predictions = parallel_model(inputs) # Parallel forward pass with new parametersloss로 인한 GPU Memory 불균형을 해소하기 위한 방법으로 위 github를 사용하여 해결할 수 있다고 하나 구버전이라 그런지 저는 바로 이 코드 from torch.nn.parallel.parallel_apply import get_a_var 하나 실행이 되지 않아 시도해보지 못하였습니다.
귀차니즘도 있어 저는 포기했지만 해당 방법을 시도해서 성공한다면 loss 또한 분산된 상태로 처리되기 때문에 시간을 단축하고 batch를 늘릴 수 있을 것으로 예상합니다.
많은 참조를 얻은 아래 링크를 참조하길 바랍니다.
🔥PyTorch Multi-GPU 학습 제대로 하기
PyTorch를 사용해서 Multi-GPU 학습을 하는 과정을 정리했습니다. 이 포스트는 다음과 같이 진행합니다.
medium.com
위 내용은 DataParallel, Custom DataParallel, Distributed DataParallel, NVIDIA Apex 4가지에 대한 multi-GPU 학습법에 대한 설명을 하고 있다.
방법 3. Horovod 사용
현재 상황에서는 Ubuntu 환경이고 Multi-GPU 상황이라면 Horovod 프레임워크 사용이 좋을 것 같습니다. 위에서 설명한 2 방법은 자잘한 문제들이 생길 수 있어 오류가 있는 반면 해당 방법은 상대적으로 간단한 방법과 동시에 좋은 효율을 내어 메모리 불균형 문제를 해결해 준다고 합니다. 추후 나중에 해당 내용에 대해 자세히 포스팅해보도록 하겠습니다.
horovod/horovod
Distributed training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. - horovod/horovod
github.com
Horovod 모듈 사용하여 Pytorch Multi GPU 학습 효율적으로 하기
1. Introduction 기본적으로 Pytorch를 이용하여 학습을 가속하기 위해서는 다수의 GPU를 활용해야 합니다. 이전 글에서 기술한 것처럼 다수의 GPU를 사용할 수 있는 방법을 Pytorch 자체에서 DistributedDataPa
blog.si-analytics.ai
