PR-107 "Image Inpainting for Irregular Holes Using Partial Convolutions" Review (2018 ECCV)(Image Inpainting)
PR-107 "Image Inpainting for Irregular Holes Using Partial Convolutions" Review (2018 ECCV)(Image Inpainting)
1. Citations & Abstract 읽기
Citations : 2021.12.16 기준 1008회
저자
Guilin Liu, Fitsum A. Reda, Kevin J. Shih Ting-Chun Wang, Andrew Tao, Bryan Catanzaro - NVIDIA Corporation
Abstract

Image Inpainting 방법론에 기반한 현존하는 딥러닝은 마스크된 구멍들에서의 대체 값들 (일반적으로 평균 값)뿐 아니라 유효한 픽셀 모두에 대해 조건화된 conv filter response를 사용하여 손상된 이미지에 대한 표준 conv 네트워크를 사용한다. 이는 색 불일치와 흐릿함과 같은 artifact를 이끈다. 후처리가 해당 artifact를 줄이기 위해 일반적으로 사용되지만 비용이 많이들고 실패할 수도 있다. 우리는 부분적인 conv를 사용하도록 제안한다. 이 때의 conv는 오직 유효한 픽셀들에 대해서 조건화되어지도록 마스크되고 재정규화된다. 더욱이 우리는 forward pass(?)의 부분으로 다음 layer에 대한 업데이트된 mask를 자동적으로 생산하는 메커니즘을 포함한다. 우리들의 방법은 비정상적인 mask에 대하여 다른 모델들 대비 뛰어나다. 우리는 우리의 접근법을 검증하기 위해 다른 방법들과 정성적, 정량적 비교를 보인다.
2. 발표 정리
공식 논문 링크
cf) Arxiv 논문 링크 (이번 회차는 해당 Arxiv 내용이 필요, 공식 논문에 없는 내용이 일부 포함됨)
https://arxiv.org/abs/1804.07723
Image Inpainting for Irregular Holes Using Partial Convolutions
Existing deep learning based image inpainting methods use a standard convolutional network over the corrupted image, using convolutional filter responses conditioned on both valid pixels as well as the substitute values in the masked holes (typically the m
arxiv.org
Presentation Slide
없음
Contents

End2End Model이며 어떤 사이즈, 모양(irregular hole)도 다룰 수 있음.
U-Net 구조를 가지는 Partial Conv


Introduction Summary
1) We propose the the use of partial convolutions with an automatic mask update step for achieving state-of-the-art on image inpainting.
2) While previous works fail to achieve good inpainting results with skip links in a U-Net [32] with typical convolutions, we demonstrate that substituting convolutional layers with partial convolutions and mask updates can achieve state-of-the-art inpainting results.
3) To the best of our knowledge, we are the first to demonstrate the efficacy of training image-inpainting models on irregularly shaped holes. (efficacy 효험 = effectiveness)
4) We propose a large irregular mask dataset, which will be released to public to facilitate future efforts in training and evaluating inpainting models.
Related Work
1) Non-learning based - Nearest Neighbor에서만 채우며, hole이 작아야하고, texture variance가 작아야하며 computing cost가 매우 커 실시간 처리가 어려움
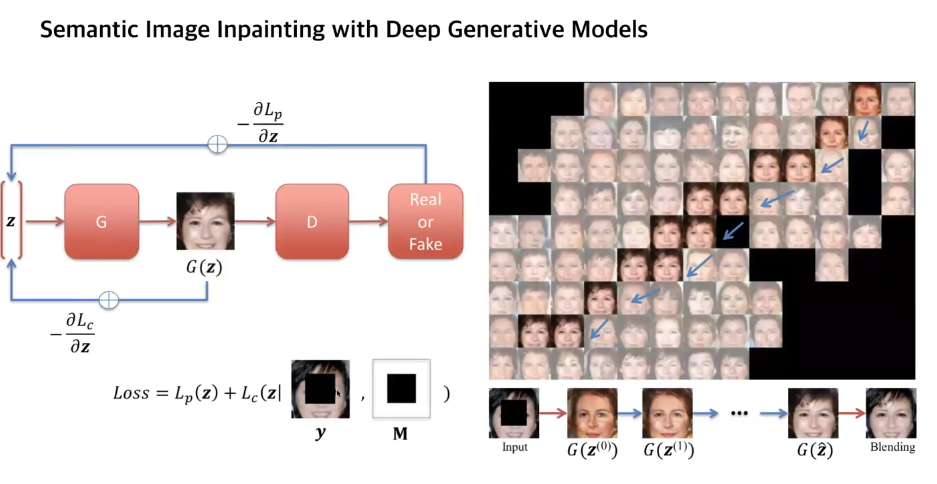
2) Deep learning based - Context Encoder, Semantic Image Inpainting with Deep Generative Models
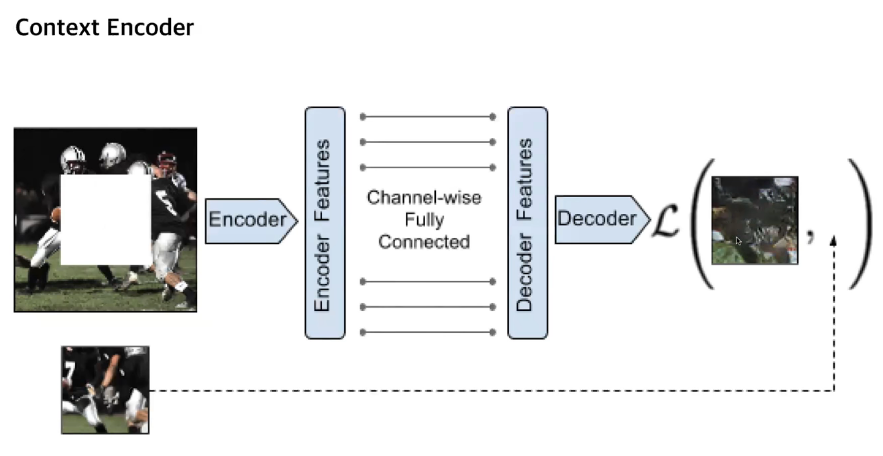
Context Encoder의 단점은 고정된 사이즈 고정된 크기의 Inpainting만 가능. Irregular hole이 있는 곳에서는 잘 작동이 어려움
Approach
1) Partial Convolutional Layer
2) Network Architecture and Implementation
3) Loss Functions
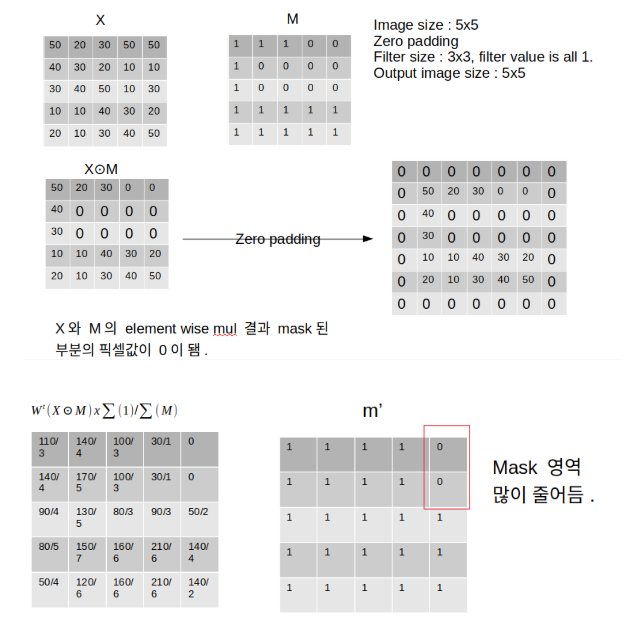
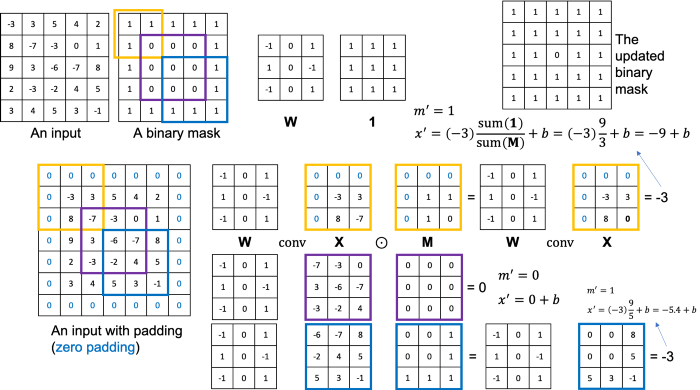
1) Partial Convolutional Layer
이 논문에서 처음 등장


W: convolution filter weights
Mask (M)는 Binary Mask = hole (mask된 부분) : 0 / non-hole : 1
Non-Hole이 조금이라도 있으면 $x^\prime$의 식이 작동함. 그 외는 0
위 식을 통해 점점 hole이 채워짐
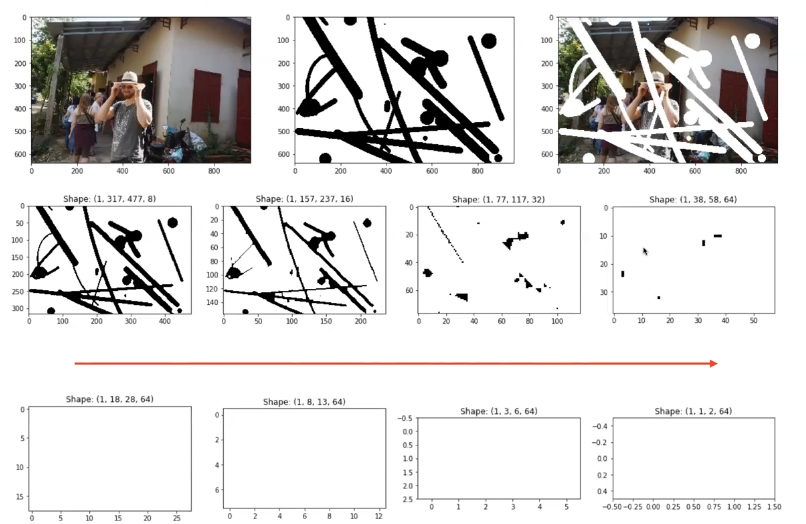
Hole이 점점 채워지면서 Inpainting이 진행됨
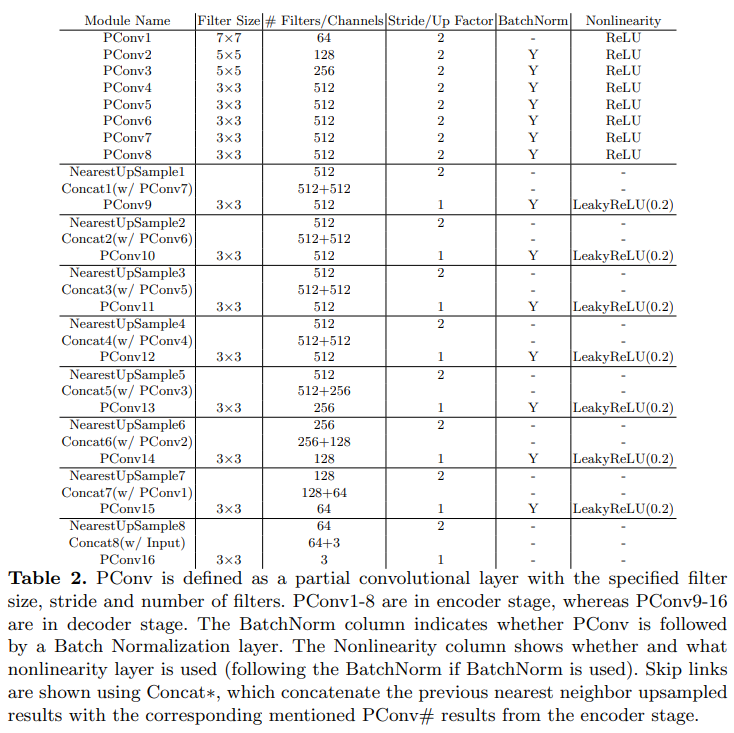
2) Network Architecture and Implementation

U-Net 구조이며 모두 Partial Conv를 활용
Implementation
PyTorch
V100 GPU 1장, 0.23초
Network Design
U-Net like arch
Nearest Neighbor upsampling
ReLU encoding stage / Leaky-ReLU with alpha=0.2 decoding stage
3) Loss Functions

Perceptual Loss - pretrained VGG16의 feature들을 활용하여 계산
Style Loss - Gram matrix를 활용하여 계산
Total Variation (TV) Loss를 통해 spatial smoothness를 추구함

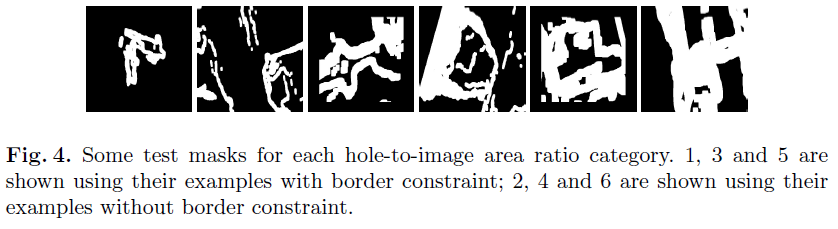
6가지 카테고리의 다른 크기의 hole을 가진 mask를 활용
ImageNet/Places2/CelebA-HQ
He initializer / Adam Optimizer
Single V100 GPU / batch size 6
Hole의 크기에 따른 BatchNorm 값이 달라지는 문제가 생김 (Encoding stage) 이에 초기 lr=0.0002로 시작한 후 마지막에 fine-tuning시 BatchNorm 학습을 freeze한 후 lr=0.00005로 작동시킴.




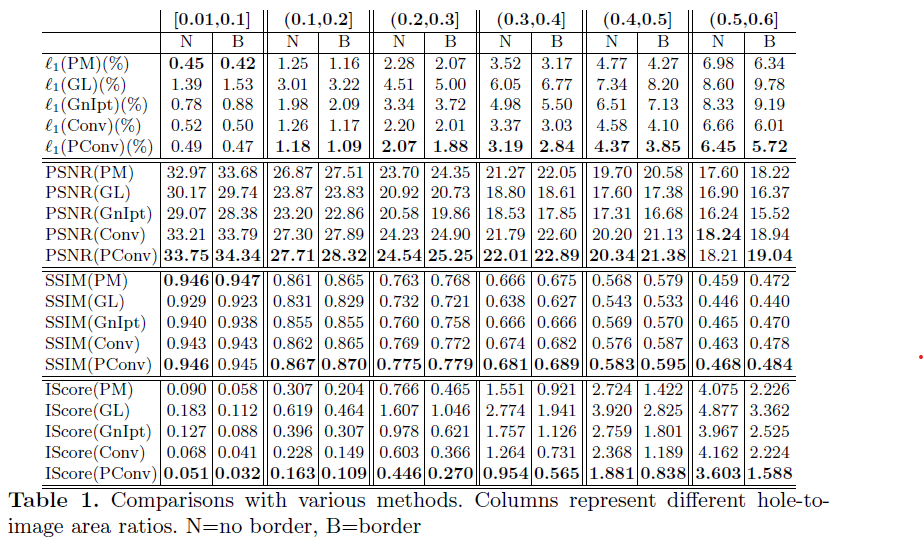
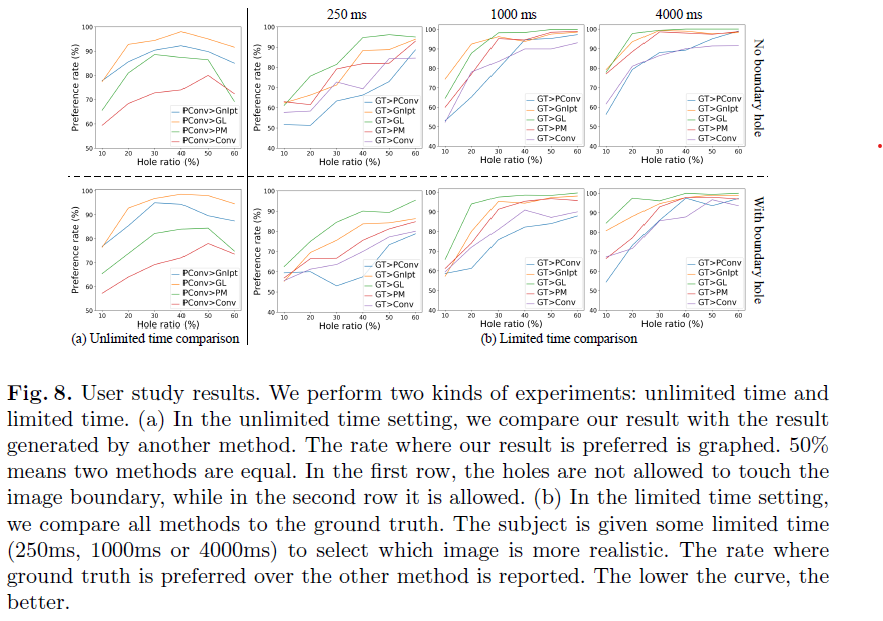
(a) PConv와 다른 모델들과의 비교
(b) 시간제한을 두고 GT와 모델들과의 비교 (낮을수록 좋은 것)

참조
1. 공식 Github
https://github.com/NVIDIA/partialconv
GitHub - NVIDIA/partialconv: A New Padding Scheme: Partial Convolution based Padding
A New Padding Scheme: Partial Convolution based Padding - GitHub - NVIDIA/partialconv: A New Padding Scheme: Partial Convolution based Padding
github.com
2. 다른 Github
https://github.com/MathiasGruber/PConv-Keras
GitHub - MathiasGruber/PConv-Keras: Unofficial implementation of "Image Inpainting for Irregular Holes Using Partial Convolution
Unofficial implementation of "Image Inpainting for Irregular Holes Using Partial Convolutions". Try at: www.fixmyphoto.ai - GitHub - MathiasGruber/PConv-Keras: Unofficial implementation o...
github.com
3. NVIDIA 시연영상
4. 참조 블로그
https://labcontext.github.io/restoration/partialconv/
[고문서복원] Partial Convolutions 논문 & 코드 리뷰
Partial Convolution
labcontext.github.io
5. 참조 블로그
Pushing the Limits of Deep Image Inpainting Using Partial Convolutions
Review: Image Inpainting for Irregular Holes Using Partial Convolutions
towardsdatascience.com
6. 같은 저자 비슷한 논문 (Partial Convolution based Padding) (공식 Github에 본 논문과 같이 쓰임)
PR-123 참조
https://arxiv.org/pdf/1811.11718.pdf
