PR-054 "ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices" Review (2018 CVPR)
PR-054 "ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices" Review (2018 CVPR)
1. Citations & Abstract 읽기
Citations : 2022.01.06 기준 3207회
저자
Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun - Megvii Inc (Face++)
Abstract

우리는 계산 능력이 매우 제한된 모바일 장치 (10-150 MFLOPs)를 위해 특별히 설계된 ShuffleNet이라는 매우 계산 효율적인 CNN 아키텍처를 소개한다. 새로운 아키텍처는 정확성을 유지하면서 계산 비용을 크게 감소시키기 위해 pointwise group conv와 channel shuffle이라는 두 가지 새로운 작업을 활용한다. ImageNet 분류와 MS COCO object detection 실험은 다른 구조들에 비해 ShuffleNet의 훌륭한 성과를 증명한다. 40 MFLOPs의 계산 하에서 ImageNet 분류 작업의 최근 MobileNet 보다 top-1 error가 낮음. ARM 기반 모바일 장치에서 ShuffleNet은 비슷한 정확도를 유지하면서 AlexNet보다 실제 속도가 13배 빠름을 달성했다.
모바일 기기에 2가지 방법을 적용하여 효과적인 결과를 얻어내었다.
1) pointwise group convolution
2) channel shuffle
2. 발표 정리
공식 논문 링크
https://arxiv.org/abs/1707.01083
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
We introduce an extremely computation-efficient CNN architecture named ShuffleNet, which is designed specially for mobile devices with very limited computing power (e.g., 10-150 MFLOPs). The new architecture utilizes two new operations, pointwise group con
arxiv.org
Presentation Slide
https://www.slideshare.net/JinwonLee9/shufflenet-pr054
ShuffleNet - PR054
Tensorflow-KR 논문읽기모임 54번째 발표자료입니다 영상링크 : https://youtu.be/pNuBdj53Hbc 논문링크 : https://arxiv.org/abs/1707.01083
www.slideshare.net
Contents
Xception - PR-034
MobileNet - PR-044
CNN 최적화 방향으로 발전되어 가는 중
Inception
1x1을 통해 channel에 대한 학습을 진행 이후 3x3을 통해 가로 세로에 대한 픽셀 확인을 진행
Depthwise Separable Convolution
Depthwise Convolution + Pointwise Convolution (1x1 Convolution)

1x1의 계산량을 더 줄일 수 있는 방법을 찾아보자

AlexNet - GPU 문제로 2 path로 나눠서 사용함 (Group Convolution)
초기 96 channel을 48 channel + 48 channel로 나눠서 사용. 이후에도 마찬가지
그러나 막상 알고보면 filter group 없는 AlexNet이 덜 효율적이고 정확도도 떨어지는 것을 확인
즉, Group Convolution을 하는 것이 효율적이라고 ShuffleNet 저자들은 판단함.
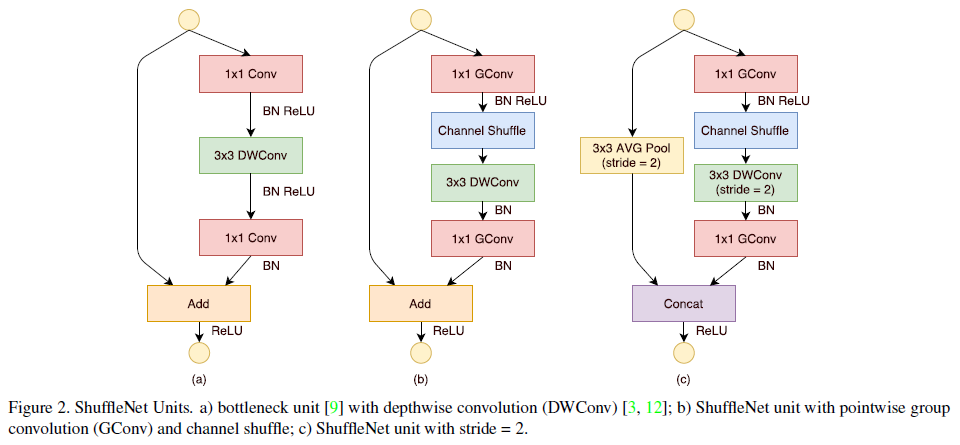
Main Ideas of ShuffleNet
1) Use Depthwise separable convolution
2) Grouped convolution on 1x1 convolution layers - pointwise group convolution
3) Channel shuffle operation after pointwise group convolution

ResNext
ResNet + Inception Idea
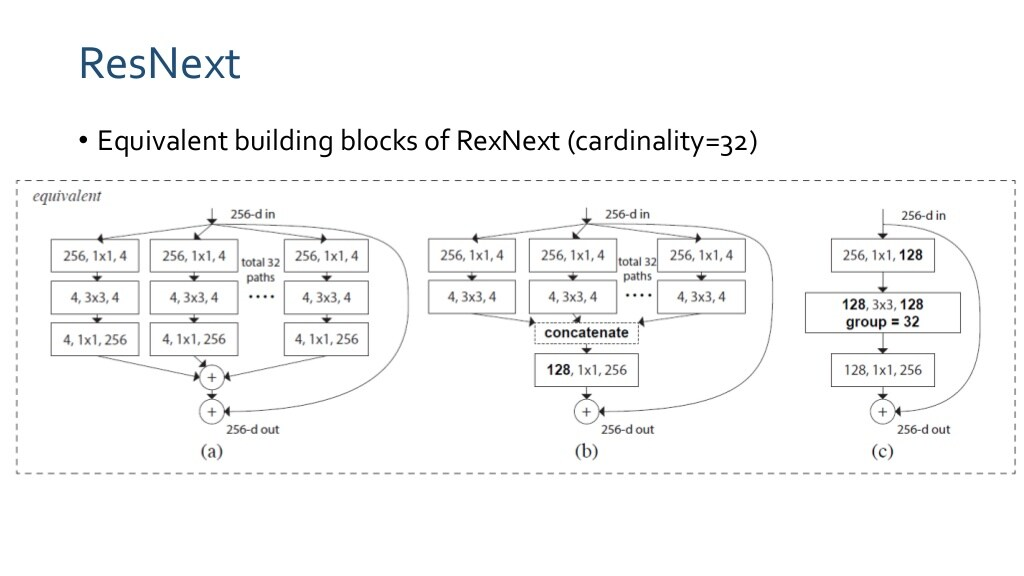
(a) = (b) = (c)
ResNet보다 더 좋은 성능을 보임

channel shuffle한 후 concatenate를 input으로 넣음.
연산량

ResNeXt : group 개수 만큼 나눔
ShuffleNet : 1x1 Group Conv : 2cm/g

Group을 늘려 연산량을 줄이고 Channel을 늘려 Complexity를 맞춤.
Group 1개 MobileNet

Scaling Factor 배수에 따라 channel 수를 줄일 때의 연산량과 error율을 보임
channel 수가 적을수록 차이가 많이 난다.

shuffle을 하느냐 하지 않느냐에 따른 결과
shuffle 하는 것이 더 좋음

channel 수가 중요함.

MobileNet보다 Depth가 깊음.
Structure에 의한 것이지 Depth에 의한 것은 아님을 보임
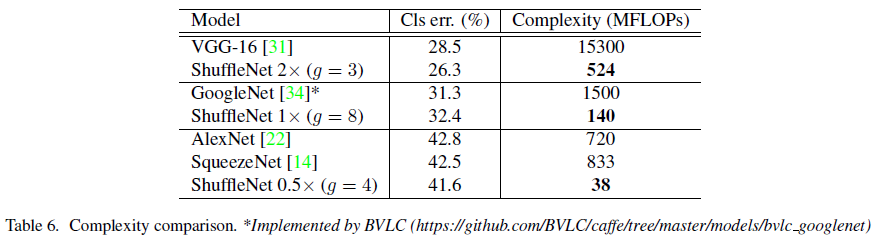
Classification Error를 비슷하게 맞췄을 때 Complexity가 적음을 보임

Detection 적용시 성능이 MobileNet보다 좋았음.

MobileNet 대비 이미지 Resolution에 따른 속도도 더 좋음을 보임.
참조
GitHub
https://github.com/MG2033/ShuffleNet
GitHub - MG2033/ShuffleNet: ShuffleNet Implementation in TensorFlow
ShuffleNet Implementation in TensorFlow. Contribute to MG2033/ShuffleNet development by creating an account on GitHub.
github.com
블로그
https://hichoe95.tistory.com/54
ShuffleNet : An Extremely Efficient Convolutional Neural Network for Mobile Devices
오늘은 MobileNet을 이어 ShuffleNet! 드디어 이까지 왔네요 .. 그럼 살펴보도록 할까요 Introduction ShuffleNet은 MobileNet과 마찬가지로 prameter수와 computational cost를 줄여 매우작은 모델을 만드는것이..
hichoe95.tistory.com
https://deep-learning-study.tistory.com/544
[논문 읽기] ShuffleNet(2018) 리뷰, An Extremely Efficient Convolutional Neural Network for Mobile Devices
안녕하세요! 이번에 읽어볼 논문은 ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 입니다. ShuffleNet은 경량화에 집중한 모델입니다. 또 다른 경량화 모델인 MobileN..
deep-learning-study.tistory.com
