PR-121 "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" Review (2019 NAACL)(NLP)
PR-121 "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" Review (2019 NAACL)(NLP)
1. Citations & Abstract 읽기
Citations : 2022.01.08 기준 32208회
저자
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova - Google AI Language
Abstract

우리는 BERT라는 새로운 언어 표현 모델을 소개한다. 이는 Transformer의 양방향 인코더 표현(Bidirectional Encoder Representations)을 의미한다.최근의 언어 표현 모델 (Peters et al., 2018a; Radford et al., 2018)와 달리, BERT는 모든 layer들에서 왼쪽과 오른쪽의 문맥을 함께 조절함으로써 레이블이 없는 문장으로부터 양방향 표현을 사전 훈련하도록 설계한다. 결과적으로 pretrain된 BERT 모델은 실질적인 작업별 아키텍처 수정들 없이 질문 답변이나 언어 추론과 같은 광범위한 작업에 대한 최신 모델을 생성하기 위해서 단 하나의 추가 출력 layer를 fine-tune한다. BERT는 개념적으로 간단하고 경험적으로 강력하다. GLUE 점수 80.5%(7.7% 포인트 절대 개선), MultiNLI 정확도 86.7%(4.6% 포인트 절대 개선), SQuAD v1.1 질의응답 테스트 F1 93.2(1.5 포인트 절대 개선) 그리고 SQuAD v2.0 질의응답 테스트 F1 83.1(5.1 포인트 절대 개선)을 포함하여 11개의 NLP에 대한 최첨단 결과를 새로 얻었다.
개인 정리
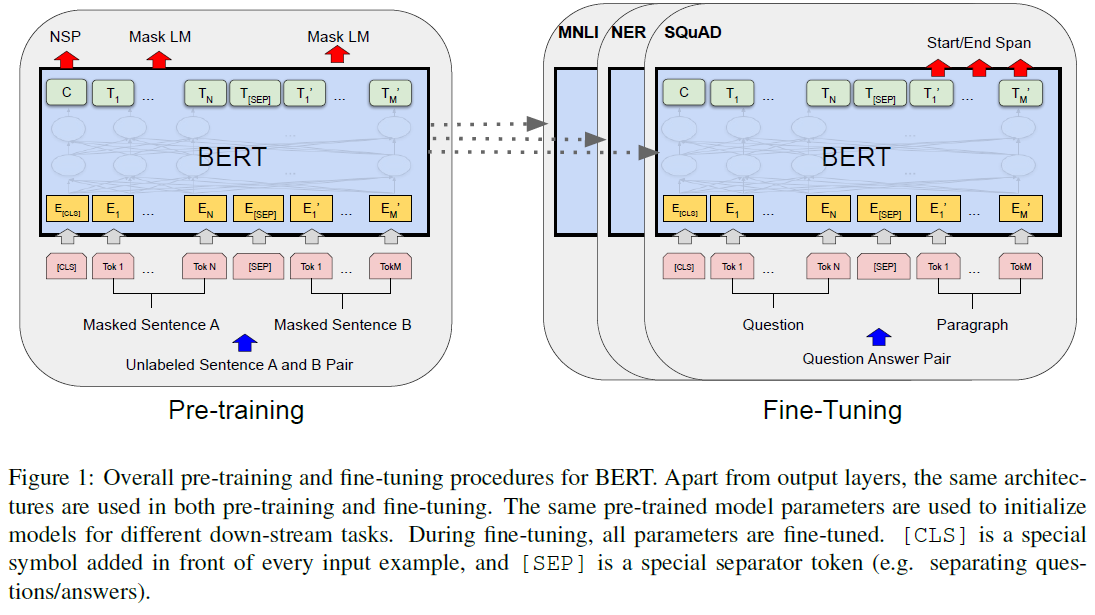
BERT의 이름에서 나타내듯 Transformer를 양방향 인코더 표현방향을 통해 사전 훈련하고 이를 fine-tune해서 좋은 결과를 얻었다고 느낌. 11개의 성과 지표에서 좋은 성과도 얻은 듯. 자세한 내용은 이후 강의 정리 확인.
2. 발표 정리
공식 논문 링크
https://aclanthology.org/N19-1423.pdf
https://arxiv.org/abs/1810.04805
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org
Presentation Slide
없음
Contents
Related Work
1) PR-049 : Attention is all you need (2017)
https://aigong.tistory.com/243
[논문 Summary] 2017 NIPS (Transformer) "Attention is all you need" (Transformer) Summary
[논문 Summary] 2017 NIPS (Transformer) "Attention is all you need" (Transformer) Summary 목차 1. 동기 근래 Vision 관련 Top 학회에서 transformer와 결합된 많은 논문들이 각광을 받고 있습니다. 저 역시 a..
aigong.tistory.com
2) Improving Language Understanding by Generative Pre-Training
3) GLUE : A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding (2018)
Language Understanding Metric으로 활용하는 GLUE
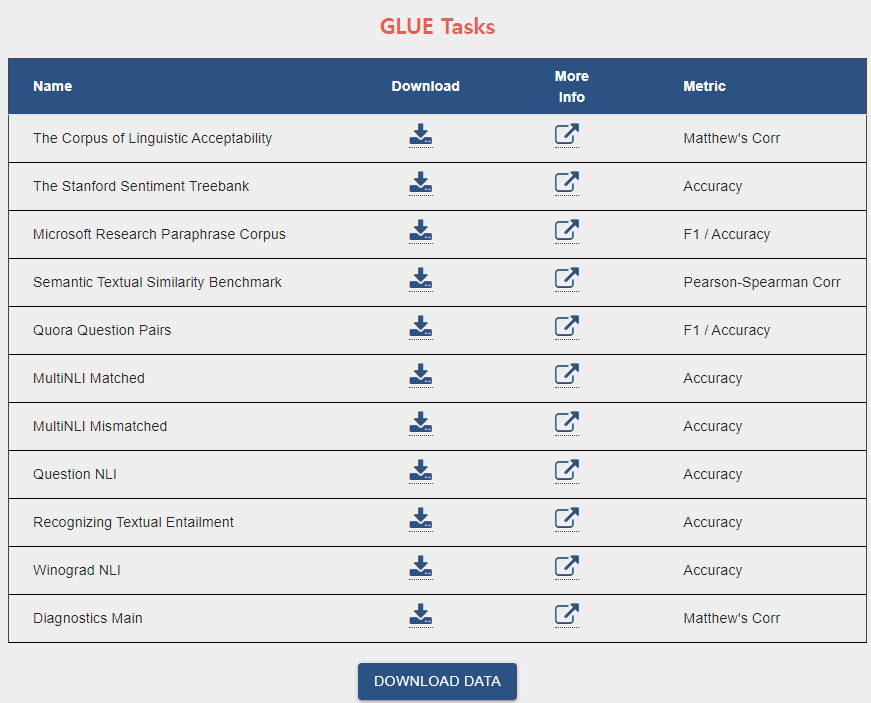
GLUE Benchmark
The General Language Understanding Evaluation (GLUE) benchmark is a collection of resources for training, evaluating, and analyzing natural language understanding systems
gluebenchmark.com
cf) 요즘은 더 발전한 SuperGLUE가 있나봄
https://super.gluebenchmark.com/
SuperGLUE Benchmark
SuperGLUE is a new benchmark styled after original GLUE benchmark with a set of more difficult language understanding tasks, improved resources, and a new public leaderboard.
super.gluebenchmark.com
Motivation
Traditional RNN / LSTM / GRU units : 왼쪽에서 오른쪽으로 token을 학습시키는 방법
Bidirectional units
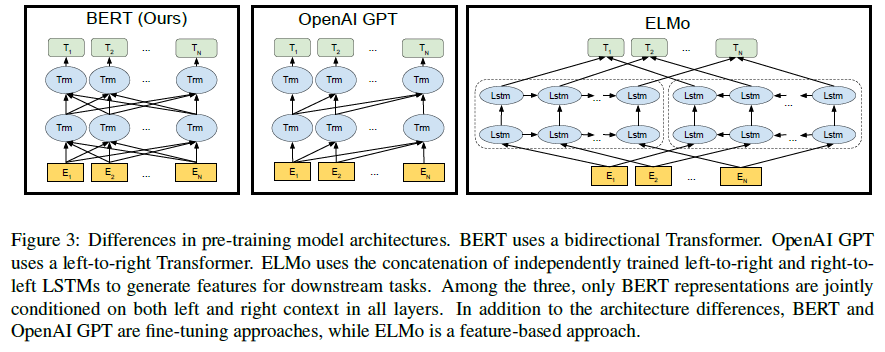
Problem
Multi-layer로 Bidirectional을 시행하면 간접적인 cheating을 하는 문제가 생김
Task #1 - Masked Language Model (MLM) ★
Task #2 - Next Sentence Prediction (NSP)
Task #1의 독창성, 새로움이 Task #2에 비해 더 큼
Task #1 - Masked Language Model (MLM)
(?)
Task #2 - Next Sentence Prediction (NSP)
classification task (binary)
2문장이 주어졌을 때 문장 2개가 이어지는지 예측 IsNext / NonNext
Embedding
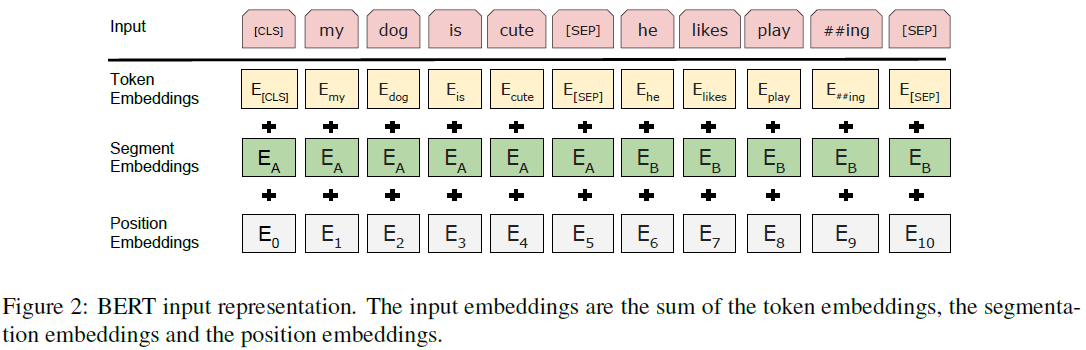
token embedding : word2vec과 비슷하게 token에 대한 embedding을 진행
position embedding 위치가 중요
segment embedding sentence 구별
[CLS] classification을 위한 hidden unit task
[SEP] sentence 구별
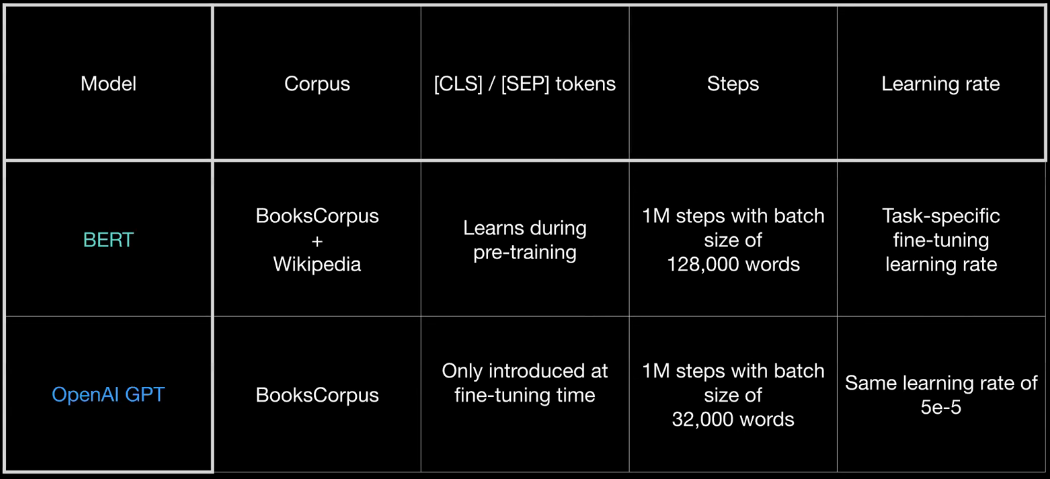
Corpus
1) BookCorpus(800M words)
2) English Wikipedia (2500M words)
Training dataset
(1) 50% - Two adjacent sentences
(2) 50% - Random sentence after a sentence
OpenAI GPT vs BERT
GLUE Benchmark
1) MNLI : Multi-Genre Natural Language Inference
(1) Given a pair of sentences, the goal is to predict whether the second sentence is an entailment, contradiction, or netural with respect to the first sentence.
(2) Two versions - MNLI matched, MNLI mismatched
(3) Two sentences, classification task
2) SST-2 : Stanford Sentiment Treebank
(1) Binary single-sentence classification task consisting of sentences extracted from movie reviews with human annotations of theri sentiment
(2) One sentence, binary classification task
3) CoLA: Corpus of Linguistic Acceptability
4) STS-B: The Semantic Textual Similarity Benchmark
5) MRPC: Microsoft Research Paraphrase Corpus
6) RTE: Recognizing Textual Entailment
7) WNLI: Winograd Natural Language Inference
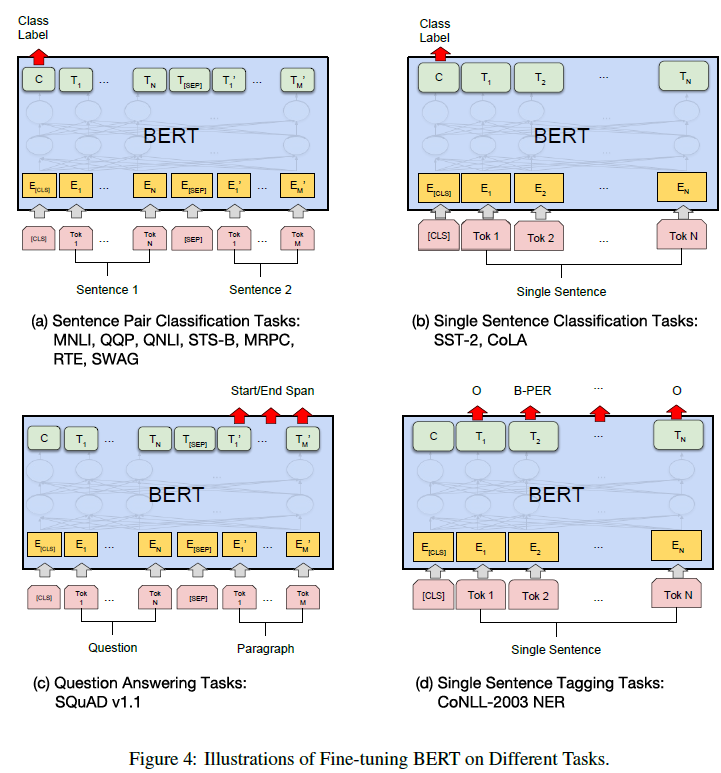
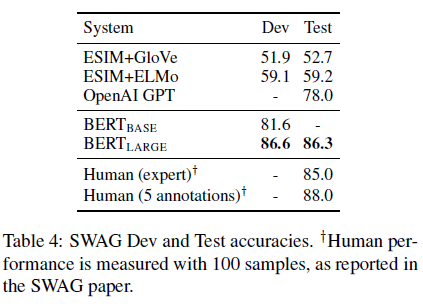
Results

SQuAD 1.1 엄밀한 시스템이기 대문에 Large에서만 Test 진행함
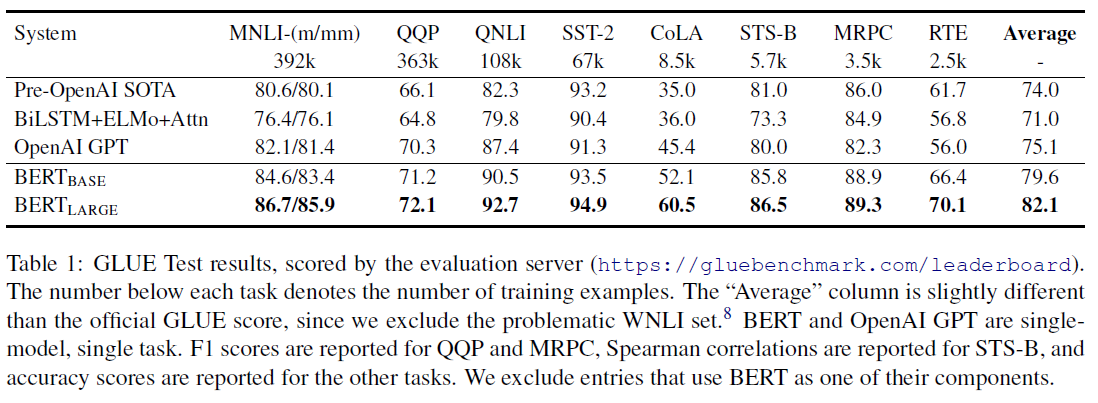
GLUE Results
Ablation Study
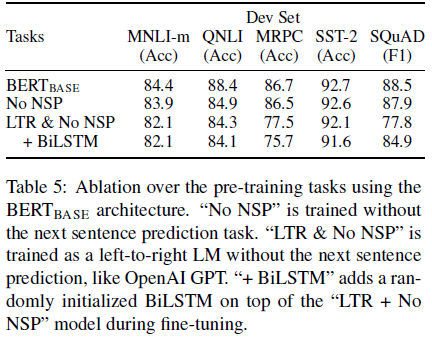
Model Size
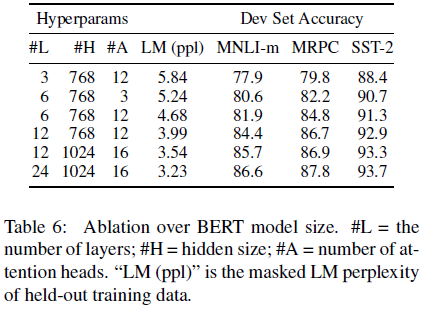
size가 클수록 성능이 좋아짐
Conclusion
1) Unsupervised pre-training is now an integral part of many language understanding systems.
2) Now models can be truly trained with deep bidirectional architectures.
3) State-of-the-art on almost every NLP tasks, in some cases surpassing human performance.
발표자 Young Seok Kim님의 개인적인 생각
읽기 쉽고 따르기 쉬웠음
모든 작업에 대한 SOTA를 이룸
NLP에서 많이 사용될 것으로 예상 (발표 시점이 2018.12.5일인 것을 감안하면 맞는 이야기)
모델이 간단하고 유용하며 단순한 수정으로 많은 작업에 적용할 수 있을 것으로 보임
Unsupervised pre-training과 supervised fine-tuning이 많은 도메인에 지배적일 것으로 예상
참조
GitHub
https://github.com/google-research/bert
GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT
TensorFlow code and pre-trained models for BERT. Contribute to google-research/bert development by creating an account on GitHub.
github.com
블로그 & 유튜브
https://docs.likejazz.com/bert/
BERT 톺아보기 · The Missing Papers
BERT 톺아보기 17 Dec 2018 어느날 SQuAD 리더보드에 낯선 모델이 등장했다. BERT라는 이름의 모델은 싱글 모델로도 지금껏 state-of-the-art 였던 앙상블 모델을 가볍게 누르며 1위를 차지했다. 마치 ELMo를
docs.likejazz.com
