[논문 Summary] Real-ESRGAN (2021 ICLRW) "Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data"
[논문 Summary] Real-ESRGAN (2021 ICLRW) "Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data"

논문 정보
Citation : 2022.04.06 수요일 기준 37회
저자
Xintao Wang - Applied Research Center (ARC), Tencent PCG
Liangbin Xie - Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, University of Chinese Academy of Sciences
Chao Dong - Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shanghai AI Laboratory
Ying Shan - Applied Research Center (ARC), Tencent PCG
논문 링크
https://arxiv.org/abs/2107.10833
Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
Though many attempts have been made in blind super-resolution to restore low-resolution images with unknown and complex degradations, they are still far from addressing general real-world degraded images. In this work, we extend the powerful ESRGAN to a pr
arxiv.org
https://ieeexplore.ieee.org/document/9607421
Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
Though many attempts have been made in blind super-resolution to restore low-resolution images with unknown and complex degradations, they are still far from addressing general real-world degraded images. In this work, we extend the powerful ESRGAN to a pr
ieeexplore.ieee.org
논문 Summary
Abstract
알 수 없고 복잡한 저하가 된 저해상도 이미지를 복원하는 blind super-resolution 연구분야는 여전히 어려움을 겪고 있다. 이를 위해 Real-ESRGAN이라는 모델을 제안한다.
1) 고차 저하(high-order degradation) 모델 프로세스를 통해 복잡하고 현실적인 저하 방법을 구현한다. 더불어 합성 단계에서 ringing과 overshoot artifact에 대해서도 고려한다.
2) spectral normalization을 포함하는 U-Net discriminator를 통해 discriminator의 성능을 향상하고 훈련의 안정성을 높인다.
광범위한 비교를 통해 제안한 모델의 성능이 시각적으로 우위에 있음을 보인다.
1. Introduction
Single Image Super Resolution(SISR)에서 많이 사용하는 CNN 기반 모델들은 이상적인 bicubic downsampling kernel을 통해 LR을 생성하지만 이는 실제 현실세계에서의 저하와는 차이가 있다.
Blind super-resolution은 알지못하고 복잡한 저하가 있는 저해상도 이미지를 복원하는 것을 목표로 한다. 이는 explicit modeling과 implicit modeling 2가지로 분류 가능하다.
1) Explicit modeling 방법에서는 흐릿함, downsampling, 노이즈, JPEG 압축으로 구성된 고전적인 degradation 모델을 사용하지만 현실 세계에서의 저하는 다수의 저하 방법의 조합만으로 모델화하기에는 너무 복잡하다. 때문에 Explicit modeling 방법들은 현실세계 샘플에서는 실패한다.
2) Implicit modeling 방법들은 GAN을 포함하는 데이터 분포 학습을 활용한다. 그러나 이는 훈련 데이터 세트의 저하에 국한되기 때문에 데이터 분포 외의 이미지에 대해서는 일반화가 어렵다.
참조) "Blind Image Super-Resolution: A Survey and Beyond", 21.07
https://arxiv.org/abs/2107.03055
Blind Image Super-Resolution: A Survey and Beyond
Blind image super-resolution (SR), aiming to super-resolve low-resolution images with unknown degradation, has attracted increasing attention due to its significance in promoting real-world applications. Many novel and effective solutions have been propose
arxiv.org
현실의 복잡한 저하(degradation)는 카메라의 이미지 시스템, 이미지 편집, 인터넷 전송과 같은 서로다른 저하 절차의 복잡한 조합으로부터 온다.
예 1) 카메라의 흐릿함, 센서 노이스, sharpening artifact 그리고 JPEG 압축을 통한 저하
예 2) 이미지 편집, 소셜미디어 업로드를 통한 압축과 알 수 없는 노이즈 * 인터넷 상에서 공유되며 발생하는 여러 차례의 복잡한 저하(degradation)
이에 본 연구에서는 고전적인 "first-order" 저하 모델에서 확장하여 "high-order" degradation modeling을 활용한다. 경험적으로 second-order degradation process가 단순성이나 효율성 사이에서 좋은 균형을 가지기 때문에 이를 채택한다. 최근 random shuffling 전략을 사용하여 실질적인 degradation을 합성하는 경우도 있지만 불분명하다. 대신 high-order degradation modeling을 사용함으로써 더 유연하고 현실적인 저하 일반화 프로세스를 모방할 수 있다.
더불어 ringing과 overshoot articat를 구현하기 위한 절차로 sinc filter 또한 활용한다.
degradation space는 모델보다 훨씬 크기 때문에 훈련에 어려움이 있다. 이 때문에 아래와 같은 조치가 필요하다.
1) discriminator의 역량을 키우기 위해 VGG-style discriminator를 U-Net 디자인으로 변경
2) U-Net 구조와 복잡한 degradation으로 인해 훈련의 불안정성이 향상되었기 때문에 훈련의 안정성을 위해 spectral normalization을 활용.
이를 통해 Real-ESRGAN은 쉽고 안정적으로 훈련하고 지역적 디테일 향상과 artifact 억제 측면에서 좋은 균형을 갖춤.
(Summary는 Abstract와 동일하므로 생략)
2. Related Work
생략 (대다수 Introduction에서 설명한 내용이며 blind super resolution에서 활용한 방법들을 소개하고 이에 대한 제한점을 서술함.)
3. Methodology
3.1 Classical Degradation Model
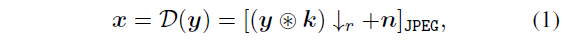
$y$ : ground-truth image
$k$ : blur kernel
$r$ : scale factor
n : noise
JPEG compression
$\mathcal{D}$ : degradation process
Blur
일반적인 blur degradation은 linear blur filter (kernel)에 conv을 진행한 것.
보통 Isotropic 그리고 anisotropic Gaussian filter 둘 중 하나를 선택함.

$k$ : Gaussian blur kernel
$\sum$ : covariance matrix
$C$ : spatial coordinate 공간 좌표
$N$ : normalization 상수

$\sigma_1 , \sigma_2$는 covariance matrix eigenvalue를 의미하는 2개의 주축의 표준 편차.
$\sigma_1 = \sigma_2$면 k는 isotropic Gaussian blur kernel 그 외는 anisotropic kernel을 의미.
Discussion
generalized Gaussian blur kernel들과 plateau-shaped distribution을 채택하여 다양한 kernel을 활용.

blur kernel을 포함함으로써 실제 샘플들에 대해 더 날카로운 결과물을 얻을 수 있다.
Noise
2가지 noise 사용 (additive Gaussian noise, Poisson noise)
1) additive Gaussian noise
- Gaussian distribution의 pdf와 동일
- 노이즈의 강도는 Gaussian distribution의 표준편차에 의해 제어
- color noise(RGB 각 채널에 대해 독립적인 noise를 합성)와 gray noise(3개의 채널에 대해 동일한 noise를 합성) 모두 활용
2) Poisson noise
- sensor noise를 대략적인 모델링을 위해 Poisson 분포를 따르는 noise를 추가함.
- 이미지 강도에 비례, 서로 다른 픽셀의 노이즈에 대해 독립적
Resize(Downsampling)
4개의 resize 알고리즘 : nearest-neighbor interpolation, area resize, bilinear interpolation, bicubic interpolation
위 알고리즘들에 의해 흐릿한 결과를 내놓기도 하고 overshoot artifact를 포함하는 날카운 이미지를 생성하기도 함.
nearest-neighbor interpolation은 misalignment 문제를 발생시키기 때문에 이를 제외한 3가지 resize 알고리즘을 랜덤으로 활용
JPEG compression
JPEG 압축은 흔한 손실 압축 기술로 YCbCr color space로 이미지를 전환하고 chroma channel로 downsample한다. 그 후 8x8 블록으로 나눈 다음 각 블록은 2차원 discrete cosine transform(DCT)로 변환한다.
본 논문에서는 Pytorch DiffJPEG를 활용한다.
3.2 High-order Degradation Model

Figure 3는 classical degradation model로 구성된 훈련을 진행했을 때 알 수 없는 노이즈와 복잡한 artifact를 포함하는 현실 세계의 복잡한 degradation 이미지의 개선이 어렵다는 것을 보여준다. 이는 classical degradation을 확장한 high-order degradation이 필요함을 설명한다.

classical degradation model = first-order modeling.
그러나 현실 세계는 더 복잡하고 다양한 방식의 degradation이 진행됨.
(자세한 설명은 축약)
n-order model = degradation process를 n번 반복한 것을 의미

경험적으로 second-order degradation process가 단순성을 유지하면서 좋은 결과를 뽑기에 채택하여 사용함.
각 degradation은 랜덤 섞기 전략(radom shuffle strategy)을 통해 반복적인 degradation을 적용함.
3.3 Rining and overshoot artifact

Ringing & overshoot artifact는 신호가 고주파수 없이 대역제한적이기 때문에 발생합니다. 일반적으로는 sharping알고리즘, JPEG 압축에 의해 주로 발견됩니다.
degradation model에 Ringing & overshoot artifact를 적용하기 위해 sinc filter를 사용합니다.

본 연구의 degradation에서는 sinc filter를 총 2번 사용합니다.
1) first-order Blur에서 한 번
2)second-order JPEG 이후에 한 번
3.4 Networks and Training
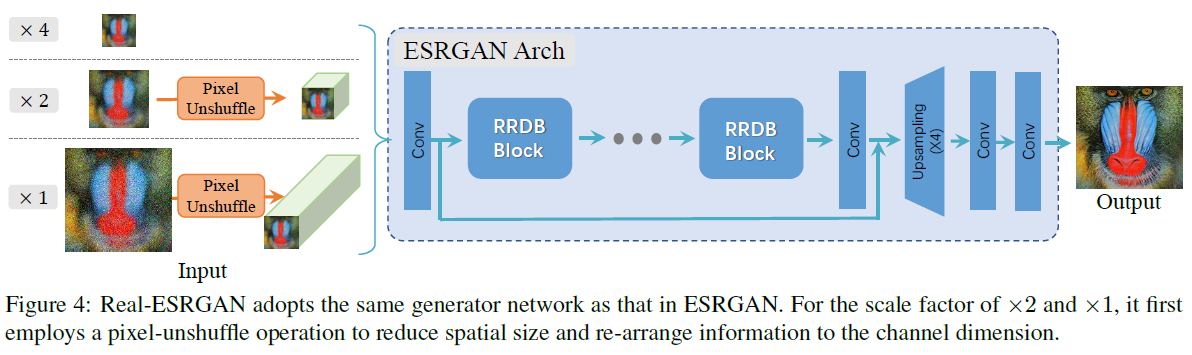
ESRGAN generator를 답습한다. 다만, 앞 입력부분에 1배, 2배, 4배짜리의 이미지를 pixel-unshuffle을 통해 얻은 값들을 concat하여 활용. 이를 통해 spatial size를 줄이고 channel size를 늘려 학습함. GPU memory와 계산 비용을 절약함.

U-Net을 통해 큰 degradation space를 개선시킬 discriminator의 성능을 향상시킨다. 이를 통해 local texture에 대한 정확한 생산이 가능하다. 다만 U-Net 구조와 복잡한 degradation은 훈련의 안정성이 떨어진다. 훈련을 안정화시킬 수 있는 spectral normalization을 같이 활용한다. 이를 통해 oversharp와 나쁜 artifact도 덜 생산하도록 한다.
4. Experiments
4.1 Datasets and Implementation
Training Details
훈련 데이터 세트 : DIV2K, Flickr2K, OST(OutdoorSceneTraining) cf) 테스트 데이터 세트는 4.2 참조
HR patch size : 256
batch size : 48
Optimizer : Adam Optimizer
ESRGAN에서 finetune된 weight를 Real-ESRGAN으로 활용
learning rate : 400K까지 $1 \times 10^{-4}$, 1000K까지 $2 \times 10^{-4}$
EMA(Exponential moving average) 사용 (어디서, 어떻게 사용했는지 나와있지 않음.)
L1 loss, Perceptual loss, GAN loss weight 비율 : {1,1,0.1}
pretrained VGG network activation 이전의 conv feature map weight 비율 : {0.1, 0.1, 1, 1, 1}
Degradation Details
second-order degradation 활용 - 단순성과 효율성의 좋은 균형을 가짐(Introduction 참조)
Gaussian kernels, generalized Gaussian kernels, plateau-shaped kernels 확룔 : {0.7, 0.15, 0.15}
Blur kernel size : {7,9,...,21} 중 랜덤 선택
Blue standard deviation $\sigma$ : first-order [0.2, 3]에서 선택 / second-order [0.2, 1.5]에서 선택
Shape Prameter $\beta$ (3.1 참조) : generalized Gaussian [0.5, 4] / plateau-shaped kernels [1, 2]
sinc kernel 확률 : 0.1
second blur degradation skip 확률 : 0.2
Gaussian noise와 Poisson noise 확률 : {0.5, 0.5}
Noise sigma range : first-order [1, 30] / second-order [1, 25]
Poisson noise scale : first-order [0.05, 3] / second-order [0.05, 2.5]
Gray noise 확률 : 0.4
JPEG compression quality factor : [30, 95]
sinc filter 적용 확률 : 0.8
(sinc kernel 확률, sinc filter 적용 확률 차이를 모르겠.....)
Training pair pool
Pytorch로 구현
batch에서의 합성된 degradation의 다양성에 제한이 걸리기 때문에 이를 개선하기 위해 매 iteration마다 훈련 샘플을 training pair pool에서 랜덤으로 선택하여 batch의 형태로 구성. pool size는 180
Sharpen ground-truth images during training
전형적인 sharpening 방법인 unsharp masking(USM)을 활용할 수도 있으나 이 알고리즘은 overshoot artifact가 생김.
훈련동안 sharpening한 원본 이미지가 sharpeness와 overshoot artifact를 억제간의 좋은 균형을 달성하는 Real-ESRGAN+를 제안함.
4.2 Comparisons with Prior Works
비교 모델 : ESRGAN, DAN, CDC, RealSR, BSRGAN
테스트 데이터 세트 : RealSR, DrealSR, OST300, DPED, ADE20k validation, Internet 이미지
perceptual quality를 평가하는 metric의 경우 실질적인 인간의 인지적 선호에 대한 반영이 불가능하다고 판단.

4.3 Ablation Studies

1) second-order degradation 데이터를 활용한 경우 더 좋은 성능이 나타남
2) sinc filter를 적용한 데이터를 활용한 경우 ringing과 overshoot artifact를 잘 제거할 수 있음.

1) U-Net discriminator는 local datail을 상승할 수 있음. 그러나 부자연스러운 texutre와 만족스럽지 못한 artifact가 생김.
2) spectral normalization을 포함하는 U-Net discriminator를 통해 안정적인 훈련과 더불어 복원된 texture가 향상.

Blur 합성에 있어 Gaussian kernel과 plateau-shaped kernel을 적용하면 더 좋은 성과가 나타남.
4.4 Limitations

한계점
1) aliasing 문제 때문에 선들이 비틀림
2) GAN의 문제로 인해 일부 영상에서 만족스럽지 못한 artifact 생성
3) 현실 세계에서의 복잡한 degration 분포를 넘어서는 것에 대해 잘 복원하지 못함. 때로는 이것이 증폭됨
5. Conclusion
본 연구를 통해 현실 세계의 blind super resolution을 위한 실질적인 Real-ESRGAN을 훈련한다.
1) 더 실질적인 degradation 합성을 위해 high-order degradation process를 제안하고 여기에 sinc filter를 사용함으로써 흔한 rining과 overshoot artifact를 모델링한다.
2) spectral normalization regularization을 포함하는 U-Net discriminator를 활용함으로써 discriminator의 성능과 훈련에서의 안정성을 높힌다.
합성된 데이터로 훈련한 Real-ESRGAN은 디테일을 향상시키고 현실세계의 이미지에 가깝기 위한 불필요한 artifact를 제거한다.
Reference
공식 Github
https://github.com/xinntao/Real-ESRGAN
GitHub - xinntao/Real-ESRGAN: Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration.
Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration. - GitHub - xinntao/Real-ESRGAN: Real-ESRGAN aims at developing Practical Algorithms for General Image/Video ...
github.com
Real-ESRGAN 웹 실행
https://huggingface.co/spaces/akhaliq/Real-ESRGAN
Real ESRGAN - a Hugging Face Space by akhaliq
huggingface.co
https://replicate.com/cjwbw/rudalle-sr
cjwbw/rudalle-sr – Real-ESRGAN super-resolution model from ruDALL-E – Replicate
This is the Real-ESRGAN super-resolution model from ruDALL-E. Real-ESRGAN was created by Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Paper Re-trained version of Real-ESRGAN was created by Igor Pavlov ruDALL-E was created by Alex Shonenkov, Tatiana
replicate.com
저자 채널 Youtube 설명 - 추가적인 ppt slide와 예시들이 있어서 좋음
Real-ESRGAN 실행 관련 Youtube
