[논문 Summary] CycleGAN (2017 ICCV) "Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks"
[논문 Summary] CycleGAN (2017 ICCV) "Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks"

논문 정보
Citation : 2022.04.08 일요일 기준 12134회
저자
Jun-Yan Zhu(1저자), Taesung Park(1저자), Phillip Isola, Alexei A. Efros - Berkeley AI Research (BAIR) laboratory, UC Berkeley
논문 링크
https://arxiv.org/abs/1703.10593
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be a
arxiv.org
논문 Summary
Abstract
고전적인 Image-to-Image Translation은 입력 짝이 존재하는 훈련 데이터로부터 mapping된 결과를 뽑아낸다.
그러나 현실에서는 짝없는 경우가 대다수이다.
고로 본 논문에서 짝이 존재하지 않는 상황에서 source domain $X$로부터 target domain $Y$로의 이미지 변환을 학습하는 방법을 제안한다.
mapping $G$ : $X \rightarrow Y$ (adversarial loss)
그러나 제약이 불충분하기에 역방향 mapping $F$ : $Y \rightarrow X$ 역시 진행
$F(G(X)) \approx X$과 그 역($G(F(Y)) \approx Y$)을 위한 cycle consistency loss를 도입
Qualitative results : 짝없는 데이터 세트를 활용한 style transfer, object transfiguration, season transfer, photo enhancement 등에서 활용한 결과를 보임.
Quantitative results : 다른 선행 연구들보다 우위에 있음을 보임.
1. Introduction
image-to-image translation은 짝이 존재하는 상황에서 x에서 y로의 표현하는 이미지로의 변환이 가능케 하는 것이 널리 사용되었다. 가령 아래와 같은 gray 이미지 - color 이미지 / image - semantic labels / edge-map - photograph로의 변환을 주로 활용했다.

그러나 짝이 있는 훈련 데이터를 얻는 것은 어렵고 비용이 크다.
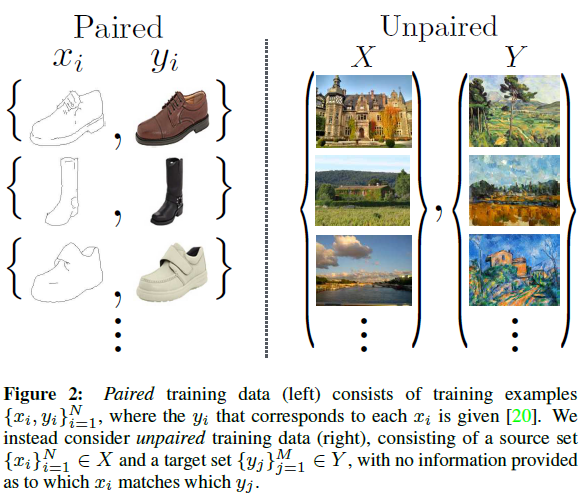
그리고 실제로는 짝이 없는 훈련 데이터의 양이 훨씬 많다. 하여 본 연구에서는 짝이 없는 예들로 가득찬 도메인들 간 변환이 가능하도록 학습하는 알고리즘을 제안한다.
저자들은 기본적으로 변화시키려는 짝이 없는 도메인들 간 근본적인 관계가 있다고 가정하고 그 관계를 찾기위해 학습한다.
output 결과 $\hat{y}$인 다음과 같이 표기가 가능하다.
$\hat{y} = G(x), x \in X$
이때 mapping $G : X \rightarrow Y$ 이다.
적대적(adversary) 학습을 통해 생성된 $\hat{y}$는 $Y$ 도메인의 $y$ 이미지와 구분할 수 없을 정도로 유사한 이미지를 생성하도록 학습시킨다. 이론적으로는 Y 도메인의 확률 분포와 일치하도록 유도되지만 실제로는 adversarial objective 단독으로는 이와 같은 최적화를 보장할 수 없다. mode collapse 문제도 생김.
이런 문제를 해결하기 위해 translation에서 cycle consistent 속성을 이용한다.
mapping $G : X \rightarrow Y$
mapping $F : Y \rightarrow X$
$F(G(X)) \approx X$와 $F(G(Y)) \approx Y$가 되도록 하는 cycle consistency loss를 추가하여 적용
도메인 X와 Y에 대해 adversarial loss와 cycle consistency loss를 합친 loss를 사용함으로써 unpaired image-to-image translation이 가능하게 한다.
이를 활용하여 style transfer, object transfiguration, attribute transfer, photo enhancement 등이 가능하다.
2. Related work
Generative Adversarial Networks (GANs)
image generation, image deiting, representation learning, image inpainting video, 3D model에서의 GAN을 소개
Image-to-Image Translation
pix2pix를 비롯한 짝이 있는 image-to-image translation에 대한 소개
Unpaired Image-to-Image Translation
Bayesian fromework를 화룡한 방법 / weight sharing 전략을 사용하는 CoupledGAN, cross-modal scene network / VAE& GAN을 조합한 방법 / adversarial network를 활용한 방법 등을 설명
본 연구는 위에서 언급한 유사도 함수나, 차원 공유와 같은 접근법이 아닌 일반화 목적의 해결책을 제안한다고 밝힘.
그외 본 연구에서 사용한 cycle consistency loss를 활용한 연구도 설명
Neural Style Transfer
image-to-image translation을 활용한 다른 방법으로 사전 훈련된 feature의 Gram matrix를 활용. 그러나 본 연구는 단순히 style transfer 뿐 아니라 다른 영역에서도 활용이 가능한 더 광범위한 연구임을 밝힘.
3. Formulation
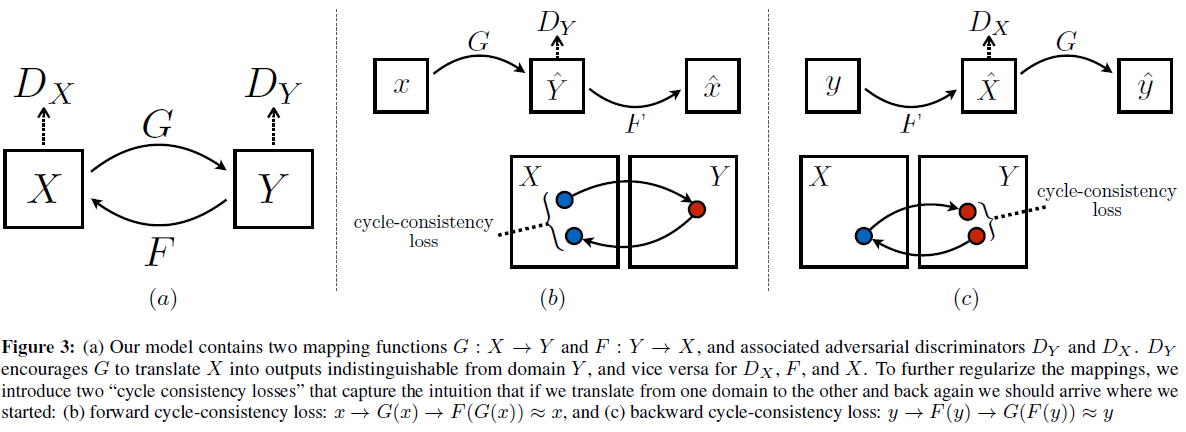
본 연구의 목표는 서로 다른 2개의 도메인 $X, Y$에 대한 2개의 mapping function을 학습하는 것이다.
mapping $G : X \rightarrow Y$
mapping $F : Y \rightarrow X$
더불어 2개의 adversarial discriminator $D_X, D_Y$를 도입한다.
$D_X$ : 이미지 $x$와 translate된 이미지 $F(Y)$ 간의 구별하는 판별자
$D_Y$ : 이미지 $y$와 translate된 이미지 $G(X)$ 간의 구별하는 판별자
2개의 objective function : adversarial loss, cycle consistency loss
3.1 Adversarial Loss
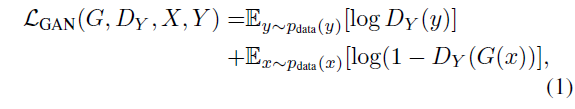
일반적인 GAN과 마찬가지의 Loss로 볼 수 있다.
mapping $G : X \rightarrow Y$와 $D_Y$를 활용한 adversarial loss를 의미한다.
다만 주의할 점은 해당 Loss뿐 아니라 역에 대한 adversarial loss 또한 존재한다는 것이다.
$\mathcal{L}_{GAN} (F, D_X, Y, X)$도 고려해야 한다.
3.2 Cycle Consistency Loss
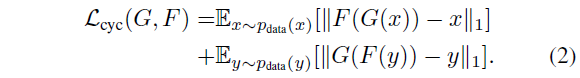
위 Figure 3 (b), (c) 참조
가능한 mapping function들의 공간을 줄이기 위해 학습한 mapping function은 cycle-consistent일 필요가 있습니다.
다시 말하면 forward cycle consistency와 backward cycle consistency가 모두 만족돼야 한다.
forward cycle consistency : $x \rightarrow G(x) \rightarrow F(G(x)) \approx x$
backward cycle consistency : $y \rightarrow F(y) \rightarrow G(F(y)) \approx y$
3.3 Full Objective

전체적인 손실 함수는 위와 같이 표현이 가능하며 $\lambda$를 통해 제어한다.
본 연구의 모델은 2개의 autoencoder의 모양인 것처럼 보이며 이것은 adversarial autoencoder로도 볼 수 있다.
다만 autoencoder 도중에 다른 도메인의 이미지로 tranlation을 한다는 점이 차이이다.
4. Implementation
Network Architecture
본 모델의 Generator 구조는 Johnson 외 연구진이 제안한 "Perceptual Losses for Real-Time Style Transfer and Super-Resolution" (2016 ECCV) 논문을 채택한다.
2 stride conv 2개, residual block들, 1/2 stride conv 2개, instance normalization을 포함한다.
본 모델의 Discriminator 구조는 70x70 PatchGAN들을 사용한다. 70x70의 이미지가 진짜인지 가짜인지 구분하기 위한 구조.
Training details

모델 훈련의 안정성을 위해 2가지 기법을 적용합니다.
1) Eq 1의 adversarial loss의 objective를 NLL(negative log likelihood)에서 least square loss(LSGAN)으로 교체.
이를 통해 더 안정적인 학습과 더불어 높은 품질의 결과를 만들 수 있다.

2) model oscillation을 줄이기 위해 Shrivastava 외 연구진의 전략을 따르며 최근 생성 네트워크에 의해 생성된 이미지들이 아닌 훈련동안 저장된 생성 이미지들을 활용하여 discriminator $D_X, D_Y$를 업데이트 한다. 이를 위해 50개의 이미지 buffer를 유지한다.
5. Results
5.1 Evaluation
Pix2Pix에서 사용한 평가 데이터 세트와 metric을 그대로 활용
5.1.1 Baseline
CoGAN, Pixel loss + GAN, Feature loss + GAN, BiGAn/ALI, pix2pix
5.1.2 Comparison against baseline

압도적인 성능을 낼 수는 없었지만 pix2pix에 비슷한 정도의 성능을 보임.
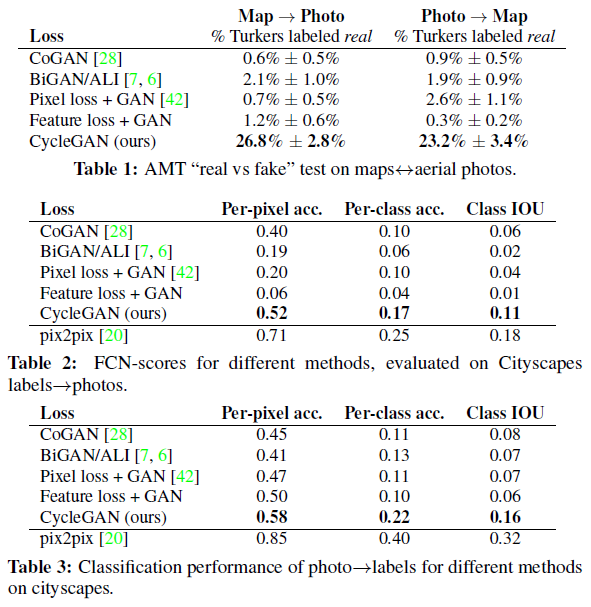
Table에서 확인할 수 있듯 가장 좋은 성과를 보임.
5.1.3 Ablation Study

GAN+forward, GAN+backward 모두 훈련의 불안정성을 보이며 mode collapse를 보임.
그에 대비하여 제안한 CycleGAN(adversarail loss + cycle consistency loss 모두 활용)의 결과는 좋은 성능을 보임.
5.2 Applications
Objective transfiguration, Season transfer

Collection style transfer

Photo generation from painting

Photo enhancement

6. Limitations and Discussion

1) 많은 경우의 image-to-image translation은 성공했으나 다양하고 기하학적 변화를 포함하는 극단적인 변형에 있어서는 연구가 필요하다.
2) 훈련 데이터에 존재하지 않는 특성의 입력을 활용하는 경우 실패한다.
3) 짝이 있는 데이터 세트에서의 결과와 비교했을 때 차이가 분명 존재한다.
많은 제약에도 불구하고 짝이 없는 데이터를 활용한 비지도 학습 방식은 많은 곳에서 활용될 가치가 있다.
Reference
공식 Github의 Pytorch 버전
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
GitHub - junyanz/pytorch-CycleGAN-and-pix2pix: Image-to-Image Translation in PyTorch
Image-to-Image Translation in PyTorch. Contribute to junyanz/pytorch-CycleGAN-and-pix2pix development by creating an account on GitHub.
github.com
도움이 되는 YouTube 1. CycleGAN 저자 박태성님
도움이 되는 YouTube 2. 동빈나
