[논문 Summary] StyleGAN (2019 CVPR) "A Style-Based Generator Architecture for Generative Adversarial Networks"
[논문 Summary] StyleGAN (2019 CVPR) "A Style-Based Generator Architecture for Generative Adversarial Networks"

논문 정보
Citation : 2022.05.11 수요일 기준 4040회
저자
Tero Karras, Samuli Laine, Timo Aila - NVIDIA
논문 링크
Official
CVPR 2019 Open Access Repository
Tero Karras, Samuli Laine, Timo Aila; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4401-4410 We propose an alternative generator architecture for generative adversarial networks, borrowing from style t
openaccess.thecvf.com
arxiv
https://arxiv.org/abs/1812.04948
A Style-Based Generator Architecture for Generative Adversarial Networks
We propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature. The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identit
arxiv.org
논문 Summary
Abstract

0. 설명 시작 전 Overview
StyleGAN은 PGGAN을 base model로 style transfer의 개념과 더불어 style mixing과 stochastic variation을 새로이 사용합니다.
이를 통해 다양한 style의 고해상도 이미지를 생성합니다.
더불어 위 방법론들을 통해 latent space가 disentangle되기 때문에 layer별 block별 상관관계가 크지 않고 구분되는 style들을 기반으로 사실적이고 고해상도인 이미지를 생성할 수 있다.
이제부터 이를 알아보기 위한 논문의 내용을 summary하도록 하겠습니다.
추천 논문 : CGAN(Disentanglement), InfoGAN(Disentanglement), WGAN-GP(Loss), PGGAN(Base model, High resolution image synthesis), BigGAN (Truncation trick, High resolution image synthesis)
1. Introduction
1)저자들은 generator에 다음 3가지를 새로이 디자인하여 이미지 합성을 이뤄낸다.
(1) a learned constant input으로 시작
(2) 서로 다른 크기에 따른 conv 다음에 style을 추가, 합성
(3) noise를 주입 (stochastic variation)
이로써 고차원의 특성 (사람의 경우 pose나 identity)의 자동적, 비지도적 분리가 가능하게 하고 scale-specific mixing과 interpoplation을 가능하게 한다.
여기서 Base model의 discriminator / loss function의 수정이 이뤄지지 않는다.
2) input latent code를 바로 사용하는 것이 아니라 중간에 MLP를 통한 새로운 latent code를 구성함으로써 latent space가 entanglement되는 것을 피할 수 있다.
3) 2가지 자동화된 metric 소개 : generator가 linear하고 덜 entangle되었다는 것을 보여주는 지표
(1) perceptual path length
(2) linear separability
4) 새로운 고해상도 사람 얼굴 데이터 세트 : FFHQ(Flickr-Faces-HQ) 제시
2. Style-based generator
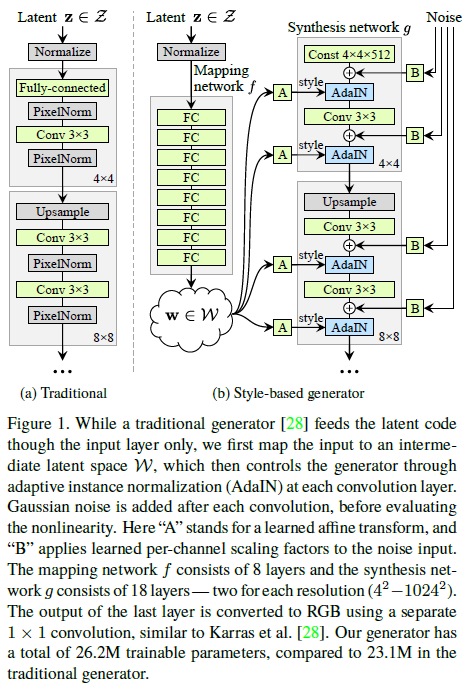
(1) Intermediate latent space $\mathcal{W}$
Figure 1. (a)에서 보이듯 전통적인 방법은 latent code를 바로 layer에 넣는 방식으로 활용된다.
그러나 제안한 방법은 latent code $z$가 non-linear mapping $\mathcal{f} : \mathcal{Z} \rightarrow \mathcal{W}$를 통해 $\mathcal{W}$를 생성한다. 이때의 Mapping function은 8개의 MLP layer로 구성되고 결과 차원(채널)은 512이다.
이렇게 진행함으로써 1. Introduction에서 언급했던 것처럼 entanglement되는 것을 피할 수 있다. (Section 4. Disentanglement studies 참조)

(2) AdaIN
생성된 intermediate latent vector $w$는 이후 affine transformation을 진행하여 shape을 맞춘다. 해당 결과와 합성 네트워크의 결과값을 기반으로 AdaIN(Adaptive Instance Normalization)을 적용함으로써 style을 입힌다.
즉, 각 feature 정보의 scaling과 bias를 변화시켜 입력 스타일로 분포를 바꿀 수 있게 해준다.
(각 채널의 conv output을 shift시켜 style을 입힌다고 생각.)
4, 8, 16, 32, 64, 128, 256, 512, 1024까지 각 크기마다 AdaIN은 2번씩 사용되며 총 18번의 AdaIN을 사용한다.
AdaIN는 학습 파라미터가 필요하지 않은 normalization.

(3) Noise
마지막으로 noise input을 새롭게 만들어 합성 네트워크의 각 layer에 추가한다. (Gaussian noise)
(효과 : Section 3.2 stochastic variation, 3.3 Separation of global effects from stochasticity 참조)
(4) Ablation Study에 따른 FID 결과
Base Model은 PGGAN으로 아래와 같이 진행된다.
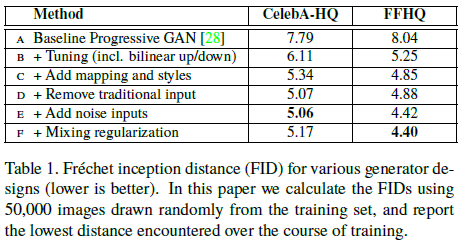
Baseline A에서부터 하나씩 추가하여 그 결과를 살펴보는 것이 Table 1이다. (이때, FID는 낮을수록 좋다.)
B : Tuning - NN 대신 binear up/downsampling, 긴 훈련시간, 정제된 hyperparameter
C: mapping network & AdaIN 적용
D: Figure 1(a)에서 설명한 것처럼 전통적인 방식과 달리 learned 4x4x512 constant tensor에서부터 시작하는 입력
E: noise 추가
F: Mixing regularization
점진적인 추가에 따라 FID가 성능이 향상됨을 확인할 수 있다.
3. Properties of the style-based generator
3.1 Style mixing
style에 대한 localize를 위해 mixing regularization을 수행한다. 기존에 하나의 latent code만을 사용하는 것과 달리 여기서는 2개의 랜덤 latent code를 활용한다.
1) latent code $z_1, z_2$에 대해 mapping network를 진행하고 이에 상응하는 $w_1, w_2$를 생성합니다.
2) cross point 이전에는 $w_1$을 적용하고 그 이후에는 $w_2$를 적용합니다.
즉, 앞단에는 $w_1$ style로 학습하다가 특정 layer 이후부터는 $w_2$로 style 적용.
단, 이때 style이 교체되는 layer를 매번 random하게 결정.
이를 통해 인접한 style들끼리 상관관계(correlate)되는 것을 방지하고 regularization 효과를 보인다. 또한, 각 layer와 block가 특정 부분의 스타일에 대한 구분되도록 진행된다.
본 논문은 이를 style mixing이라 칭한다.

Figure 3는 2개의 latent code를 mixng함으로써 생성된 이미지를 나타낸다.
(1) Coarse Style - pose, hair, face shape (4, 8 resolution, 2개의 resolution * 2개의 AdaIN = 4개)
high-level attribute 즉, pose, 일반적인 머리 스타일, 얼굴 모양, 안경 유무의 변화를 초래
(2) Middle Style : facial features, eyes (16, 32 resolution, 2개의 resolution * 2개의 AdaIN = 4개)
머리 스타일, 눈이 떴는지 감았는지의 변화를 초래
(3) Fine Style - color scheme (64, 128, 256, 512, 1024 resolution, 5개의 resolution * 2개의 AdaIN = 10개)
색상이나 미세한 구조 detail의 변화를 초래

낮은 해상도를 담당하는 초반 layer에서는 전체적인 스타일 담당
높은 해상도를 담당하는 후반 layer에서는 세부적인 스타일을 담당
이를 통해 고해상도 이미지를 생성
다만 위 이미지에서 주의깊게 봐야하는 것은 Source B에 해당하는 style을 어느 resolution까지 사용할 것인가를 고려한 결과임을 이해해야한다.
3.2 Stochastic variation
머릿결, 주근깨, 모공 등 인지에는 크게 영향을 끼치며 랜덤하게 생성되는 부분을 stochastic으로 간주한다.
(이런 부분들에 대한 기존 모델들의 입장 - 중략)
본 논문에서는 stochastic variation을을 위해 각 conv 다음 per-pixel noise를 추가한다. (Figure 1 (b) 우측 부분)

보이는 바와 같이 Figure 4 (b)는 noise를 줬을 때의 결과를 보여준다. 전반적인 외관은 그대로거나 동일하지만 머릿결이 바뀌는 것을 확인할 수 있다. 이는 Figure 4 (c)에서 밝은 부분을 보면 더 확연히 알 수 있다.

Figure 5. (a) 모든 layer에 noise를 적용한 경우 - 자연스럽고 섬세한 머리 곱슬이 나타남.
Figure 5. (b) noise를 적용하지 않는 경우 - 자연스러운 머리가 어려움.
Figure 5. (c) noise를 fine layer만 적용한 경우 - 섬세한 머리 곱슬이 나타남.
Figure 5. (d) noise를 coarse layer에만 적용한 경우 - 큰 윤곽의 머리 곱슬이 나타남.
정리하면 다음과 같다.
Coarse layer noise - large-scale curling of hair
Fine layer noise - finer details, texture
No noise - featureless "painterly" look
4. Disentanglement studies
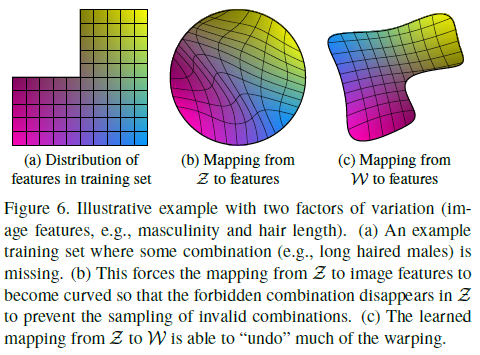
Disentanglement란 하나의 변동요소를 제어할 수 있는 선형 부분공간들로 구성된 latent space를 의미한다. 그러나 제약된 분포(일반적으로는 Gaussian)에서 훈련 데이터 세트에서의 분포를 바로 따라야 하는 일반적인 방법들은 disentanglment가 어렵다. (Figure 6 (b))
그러나 제안된 mapping function을 통해 생성한 intermediate latent space $\mathcal{W}$는 고정된 분포로부터 sampling을 바로 하지 않기 때문에 선형적인 분포를 생성할 수 있다. (Figure 6 (c))
그러나 현존하는 방법들 중 disentanglement를 정량화할 수 있는 척도는 없다.
이에 2가지 measurement : perceptual path length와 linear separability를 제시한다.
4.1 Perceptual path length
latent space vector에서 interpolation의 linearity가 없다면 이는 entangle된 것임을 의미한다.
즉, 두 지점에 대하여 중간 지점에 급격한 변화가 있거나 존재하지 않는다면 entangle된 것이다.
본 정의를 바탕으로 disentanglement를 측정하기 위해 2개의 VGG16 embedding사이의 weight 차이를 계산한다. 즉, pretrained model인 VGG16 layer의 feature map을 사용하여 perceptual difference를 구한다.
이때 얼굴부분만 crop해서 사용.
perceptual path length를 구한다.
다만 latent space $\mathcal{Z}$는 가우시안 분포를 따르는 경우가 많아 spherical interpolation을 사용하고 latent space $\mathcal{W}$는 normalize되지 않았기 때문에 linear interpolation을 사용한다. (Figure 6 참조)

latent space $\mathcal{Z}$에 대한 perceptual path length

latent space $\mathcal{W}$에 대한 perceptual path length

4.2 Linear separability
latent space point들이 linear hyperplane을 통해 서로 다른 두 집합으로 잘 분리되는지를 정량화하는 지표를 제안한다.
Discriminator와 같은 구조의 classifier를 사용
40개의 속성이 보유된 CelebA-HQ를 이용하여 40개의 분류 모델을 학습한다.
이때, 20만개의 이미지를 생성 후 분류 모델을 통해 분류함.
confidence가 낮은 절반을 제거하고 10만개의 label된 latent-space vector를 생성해냄.
각 속성마다 linear SVM를 학습.
각 속성별로 conditional entropy를 구한 separability score $exp( \sum_i H(Y_i|X_i))$를 구함.
(i는 속성, X는 SVM로 예측된 class, Y는 pre-train된 분류기로 결정된 class)
Disentanglement measurement 결과
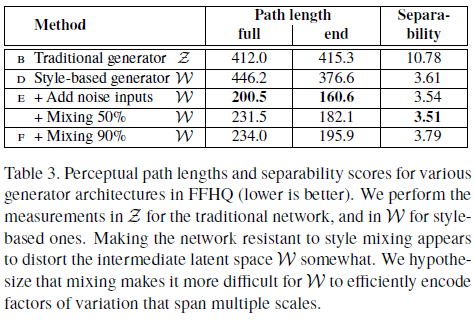
Table 3에서 보이는 바와 같이 $\mathcal{Z}$보다 $\mathcal{W}$가 더 disentanglement하다는 것 즉 더 선형적이라는 것을 보여준다. (Path length, Separability가 낮을수록 좋음)
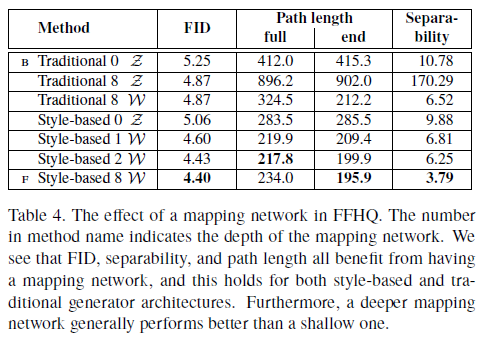
Table 4. Mapping network가 disentanglement 즉, linear해지는데 더 도움을 준다는 것을 보여준다.
Appendix - 생략 (FFHQ, Truncation trick, Hyperparameter와 training detail, training convergence)


결과 정리
1. mapping network를 구성함으로써 disentanglement를 일정부분 보장할 수 있게 함.
2. 각 size별 style을 적용함으로써 다양한 스타일 적용이 가능하게 함.
3. style mixing을 통해 localization을 보장하는 layer별 style을 고정시킴
4. stochastic variation을 통해 더 사실적이고 다양한 이미지 생성을 가능하게 함.
5. Disentanglement를 측정할 수 있는 2가지 방법론을 제시(Perceptual Path Length, Linear Separability)
6. 새로운 데이터세트 FFHQ 제시
번외
걸린 시간
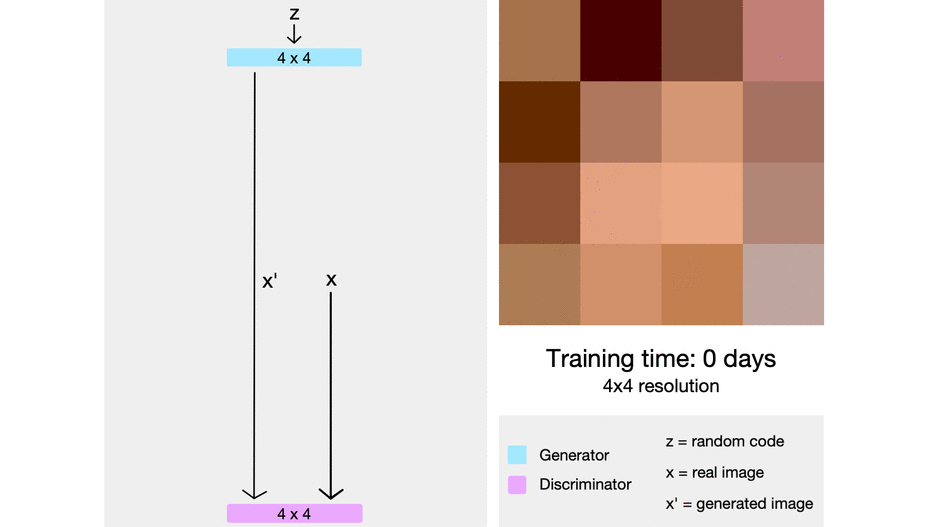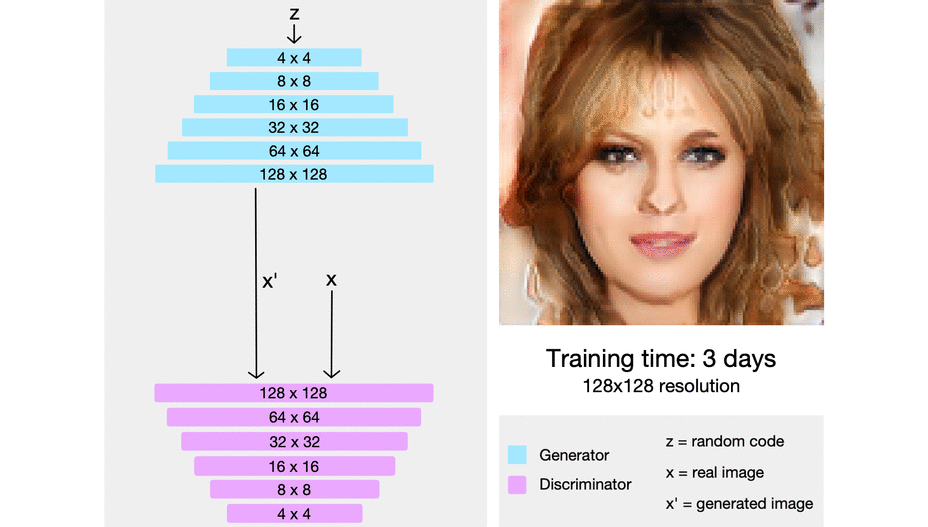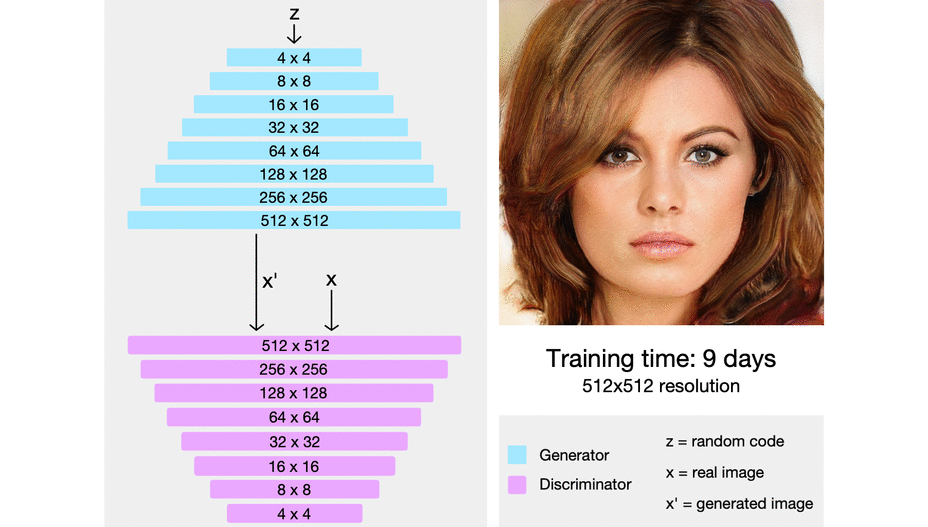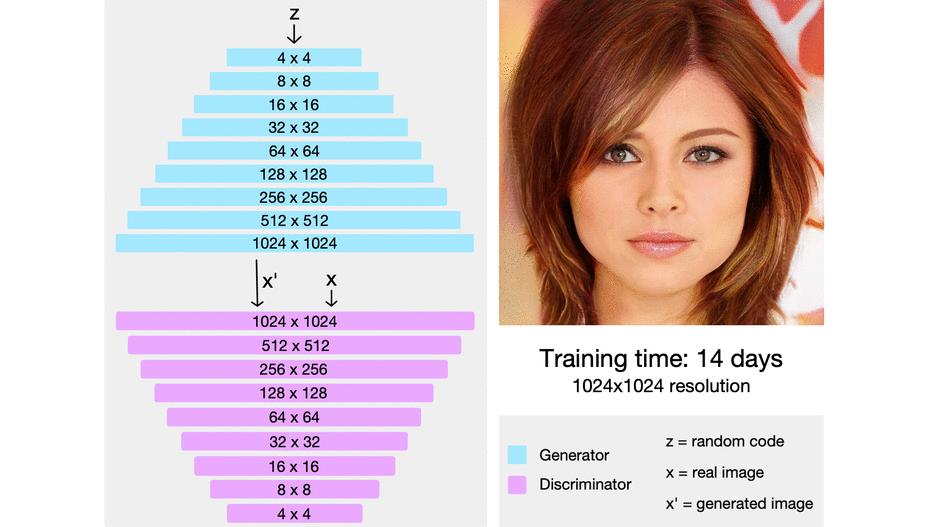
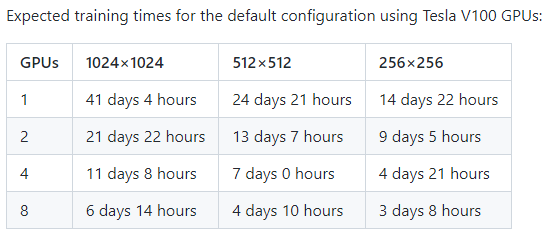
Official github에 따르면 아래와 같은 시간대가 걸린다고 봅니다. 심지어 $256 times 256$에 대해 GPU 하나만으로 15일 가량을 학습해야하니 상당히 오랜시간 학습해야합니다.
제 경험상 실험실에서 사용하는 워크스테이션은 GPU 4개 3090 이니 1024 해상도에 대해서 아마 11일보다는 적게 걸리겠지만 그래도 상당한 시간이 소모되는 것은 사실입니다.
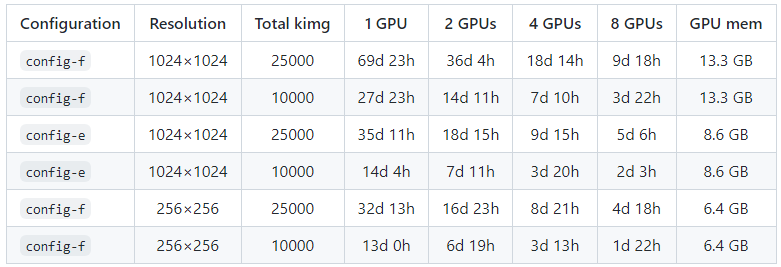
StyleGAN v2는 같은 조건 하에서 약간 시간이 덜 잡아먹히는 것 같아보이기도 하지만 full tuning으로 하면 stylegan v1보다는 많이 소요됨.
https://github.com/NVlabs/stylegan2
GitHub - NVlabs/stylegan2: StyleGAN2 - Official TensorFlow Implementation
StyleGAN2 - Official TensorFlow Implementation. Contribute to NVlabs/stylegan2 development by creating an account on GitHub.
github.com
Reference
Official Github Code
https://github.com/NVlabs/stylegan
GitHub - NVlabs/stylegan: StyleGAN - Official TensorFlow Implementation
StyleGAN - Official TensorFlow Implementation. Contribute to NVlabs/stylegan development by creating an account on GitHub.
github.com
Official YouTube Video
도움이 되는 YouTube 1. 나동빈님
도움이 되는 블로그 1. Jihye Back님의 정리 블로그 (깔끔 with code)
https://happy-jihye.github.io/gan/gan-6/
[Paper Review] StyleGAN : A Style-Based Generator Architecture for Generative Adversarial Networks 논문 분석
style transfer를 PGGAN에 적용한 nvidia research의 StyleGAN model에 대해 알아본다.
happy-jihye.github.io
도움이 되는 블로그 2
Explained: A Style-Based Generator Architecture for GANs - Generating and Tuning Realistic…
NVIDIA’s novel architecture for Generative Adversarial Networks
towardsdatascience.com
Pytorch 버전 StyleGAN 코드 (Naver CLOVA Kim Seonghyeon님)
https://github.com/rosinality/style-based-gan-pytorch
GitHub - rosinality/style-based-gan-pytorch: Implementation A Style-Based Generator Architecture for Generative Adversarial Netw
Implementation A Style-Based Generator Architecture for Generative Adversarial Networks in PyTorch - GitHub - rosinality/style-based-gan-pytorch: Implementation A Style-Based Generator Architecture...
github.com
기타(재미삼아 할 수 있는 사이트 2개)
https://thispersondoesnotexist.com/
This Person Does Not Exist
thispersondoesnotexist.com
https://www.whichfaceisreal.com/
Which Face Is Real?
www.whichfaceisreal.com
0000
