[논문 Summary] StyleGAN2-Ada (2020 NIPS) "Training Generative Adversarial Networks with Limited Data"
[논문 Summary] StyleGAN2-Ada (2020 NIPS) "Training Generative Adversarial Networks with Limited Data"
논문 정보
Citation : 2022.06.02 토요일 기준 436회
저자
Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, Timo Aila - NVIDIA
논문 링크
Official
https://proceedings.neurips.cc/paper/2020/file/8d30aa96e72440759f74bd2306c1fa3d-Paper.pdf
Arxiv
https://arxiv.org/abs/2006.06676
Training Generative Adversarial Networks with Limited Data
Training generative adversarial networks (GAN) using too little data typically leads to discriminator overfitting, causing training to diverge. We propose an adaptive discriminator augmentation mechanism that significantly stabilizes training in limited da
arxiv.org
논문 Summary
Abstract

- 매우 적은 데이터를 통해 GAN을 학습하는 것은 Discriminator가 overfitting되고 발산을 유발하게 된다.
- 제한된 데이터 상황에서 안정적으로 학습하도록 도와주는 adaptive discriminator augmentation mechanism을 제안한다.
- loss function이나 네트워크 구조를 변경할 필요도 없고 처음부터 훈련할 때든 fine-tuning할 때 모두 적용 가능하다.
- 여러 데이터 세트로 실험했고 수천 장의 훈련 이미지만으로도 좋은 결과를 얻었다.
0. 설명 시작 전 Overview
1. Introduction
인상깊은 GAN의 결과물들은 무제한적으로 공급될 수 있는 것처럼 보이지만 특정 제약 조건을 갖춘 많은 양의 이미지가 필요하다는 어려움이 있다. 특히, 새로운 custom data의 경우 최근 고해상도 고품질 GAN 기준 $10^5~10^6$개의 이미지가 필요하다.
작은 양의 데이터세트를 활용했을 때 가장 중요 문제는 discriminator의 overfit이다. 이는 generator으로의 feedback을 무용지물로 만들고 발산하는 문제점을 가진다. overfit에 대한 가장 일반적인 해결법은 dataset augmentation이지만 GAN에서 noise, rotate 등으로 augmentation을 진행하면 augment된 분포에서도 학습을 진행하기 때문에 원치않는 결과물이 생성되닉도 한다. (논문에서는 "leaking" augmentation이라 표현. 아마 augmentation 정보가 generator로 leak(새다, 누수되다. 스며들다.)되는 것을 의미)
예를 들어 noise augmentation을 추가했을 때 noisy 결과를 얻을 수 있다는 의미
본 논문에서는 생성된 이미지로의 augmentation 누수없이 discriminator가 overfitting되는 것을 방지하는 광범위한 augmentation 방법을 설명한다.
1) leaking으로부터 augmentation을 방지하는 조건들에 대해 광범위한 분석
2) 다양한 augmentation 집합과 adaptive control scheme를 설계
StyleGAN2 기준 오직 수천장의 이미지만으로도 좋은 결과가 나옴을 증명한다.
2. Overfitting in GANs
FFHQ, LSUN CAT 데이터세트 사용
Baseline StyleGNA2, BigGAN (StyleGAN2가 대부분의 전제 backbone)
광범위한 Hyperparameter와 dataset size를 활용하기 위해 FFHQ 256x256 사이즈로 실험
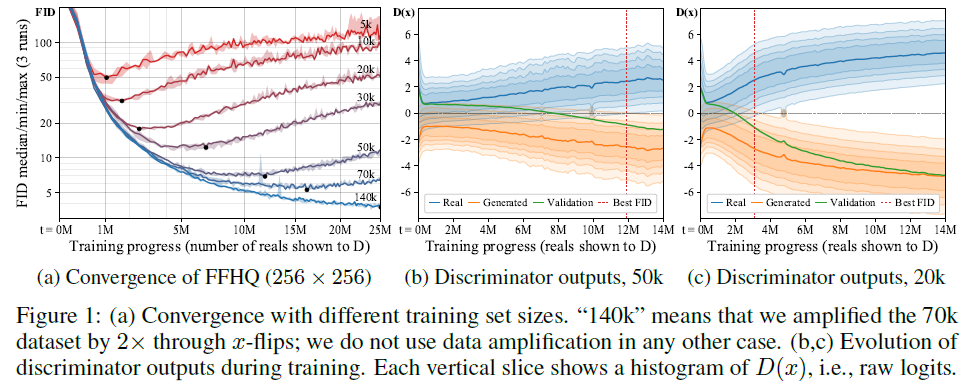
Figure 1. (a) 데이터세트의 데이터 양에 따라 FID 수치를 나타낸 것으로 데이터의 양이 적을 수록 가장 낮은 FID 수치가 빠르게 온다. 이후 빠르게 성능이 나빠지는 것을 확인할 수 있다. (데이터의 양이 적을 수록 Overfitting)
Figure 1. (b, c) 데이터의 양에 따른 Discriminator 결과를 나타낸 것으로 초기에는 겹침이 존재하나 Validation은 점진적으로 Generated의 수치에 가까워짐을 확인할 수 있다. 그리고 이 가까워짐은 데이터의 양이 적을수록 빠르게 일어난다.(Overfitting)
2.1 Stochastic discriminator augmentation
"Improved consistency regularization for GANs", 2021 AAAI
https://arxiv.org/abs/2002.04724
Improved Consistency Regularization for GANs
Recent work has increased the performance of Generative Adversarial Networks (GANs) by enforcing a consistency cost on the discriminator. We improve on this technique in several ways. We first show that consistency regularization can introduce artifacts in
arxiv.org
위 논문은 생성된 이미지에 leak augmentation이 일어나지 않는 balanced consistency regularization (bCR) 방법을 제안함.


본 논문에서는 bCR에 대한 그림을 도식화해서 Figure 2 (a)에 넣어주었는데 그림과 알고리즘에서 느낄 수 있듯 Generator에서는 Augmentation을 사용하지 않고 Discriminator 훈련에 대해서만 Augmentation을 사용한다. 이후 consistency regularization term에 넣어 loss로 활용한다.
그러나 generator가 어떠한 penalty 없이 자유롭게 augmentation을 포함하는 이미지를 생성할 수 있기때문에 leaking augmentation의 가능성은 여전히 남아있다. (Section 4. Figure 7 (d) 참조)
이에 본 논문에서는 Figure 2 (b)에 나와있는 것처럼 오직 augmented 이미지를 사용하여 discriminator를 평가한다. 물론 generator 때도 동일하게 진행한다. 이를 stochastic discriminator augmentation이라 저자들은 칭한다.
2.2 Designing augmentations that do not leak
2.1에서 언급한 방법에 대한 저자들의 묘사는 다음과 같다.
"왜곡되고 심지어는 파괴된 고글을 discriminator에 씌우고 훈련 데이터와 구분할 수 없는 샘플을 generator가 생성하도록 만드는 것"
"AmbientGAN: Generative models from lossy measurements", 2018 ICLR 저자들은 이와 비슷한 고민을 했고 특정 조건 하에서 이것이 가능하다고 말한다.
https://openreview.net/forum?id=Hy7fDog0b
AmbientGAN: Generative models from lossy measurements
How to learn GANs from noisy, distorted, partial observations
openreview.net
조건 : corruption process가 데이터 공간의 확률 분포에 대한 invertible transformation이 가능할 때 올바른 분포를 찾아 생성해낼 수 있다.
본 저자들은 이를 "non-leaking"이라 부르기로 한다.
----------<...이해하기 난해...>----------
uniform하게 랜덤 회전 {0, 90, 180, 270}한다면 이는 invertible하지 않다. augmentation 이후 방향들에 대한 차이를 알아차리기 어렵다.
=>{25%, 25%, 25%, 25%} 동일한 확률이기 때문에 어디서 비롯되었는지 알기 어렵기 때문에 invertible이라고 칭하는 듯
그러나 p<1인 확률에서 회전을 실행한다면 0도에 대한 상대적 발생확률이 높아지기 때문에 invertible하다.
=> 이는 augmentation 이전의 회전으로의 회귀가 가능해지고 이는 결국 원래 모양을 예측할 수 있기때문에 이런 말을 하는 듯
Appendix C에는 이를 비롯한 다른 augmentation들에 대해 non-leaking 조건들을 어떻게 수행하는지 보여준다.
------------------------------------------------

Figure 3. (a)와 같이 Isotropic image scaling인 경우 p에 무관하게 안전한 augmentation이 가능하다.
그러나 Figure 3. (B)와 앞에서 언급한 랜덤 90도 회전의 경우 p가 너무 높으면 generator 랜덤 중 하나를 선택하게 된다. 다만 0.85 이전에 대해서는 올바른 결과를 생성한다.
Figure 3. (C) color transformation의 경우 역시 (B)와 마찬가지로 p=0.8보다 낮은 값이면 올바른 결과를 생성해낸다.
실험에 따르면 p가 0.8이하면 leak가 발생하지 않는다.
2.3 Our augmentation pipeline
Image classification의 한 논문의 성공에 기반해봤을 때 최대한 다양한 augmentation을 적용하는 것이 좋다는 가정으로 시작.
6개 카테고리 18개 transformation (Appendix B 참조)
pixel blitting (x-flips, 90도 rotations, integer translation), more general geometric transformations, color transforms, image-space filtering, additive noise, cutout

Figure 2 (b)에 나와있는 것처럼 augmentation된 이미지를 넣으므로 미분가능한 augmentation이어야함.
모든 transformation에 대해 동일한 p 값을 사용. p가 작을수록 깨끗한 이미지 생성


Figure 4 (a, b) : 소규모 데이터 세트로 훈련시킬 때 p=0.8인 경우 가장 좋은 FID를 나타냄. 특히 Pixel blitting과 Geometric transform의 효과가 가장 좋음. 다른 augmentation은 미미함.
Figure 4. (c) : 데이터 양이 많을 때 모든 augmentation은 역효과
Figure 4. (d) : 10k의 데이터 세트에 대해 p=0.8일 때 Geometric transform의 효과가 가장 좋았다. 강한 augmentation 사용이 overfitting을 감소시켜주지만 그만큼 수렴의 속도를 늦춘다.(오래 학습)
3. Adaptive discriminator augmentation
이상적으로 overfitting의 정도에 기반한 동적으로 augmentation tuning을 조절 및 제어한다.
overfitting을 정량화하는 일반적인 방법은 validation set을 분리하여 활용하는 것으로 training set에 상대적인 행동에 관찰하는 것이다.
4개의 연속된 minibatch (2*64=256 이미지)
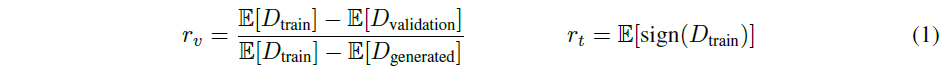
$r$이 0 이면 overfitting이 없다는 의미이고 $r$이 1이면 완전한 overfitting을 의미한다.
=> $r_v$의 경우 $D_{validation}$이 만약 $D_{generated}$에 가깝게 행동한다면 1이 된다. 반면 $D_{train}$에 가깝게 행동하면 0이 된다. 다시 말하면 validation이 generated와 마찬가지로 가짜라고 판단되어 같게 판별된다면 완전한 overfitting이 되고 validation이 train와 같은 분포의 값으로 예측되어 이와 같이 판단된다면 overfitting없이 훈련이 잘 된다고 판별한다.
$r_t$의 경우 training data에서 real이라 판별하는 데이터가 얼마나 있는지를 판별한다. 이는 hyperparameter가 적기 때문에 덜 민감하다.
초기 p=0로 설정하고 매 4번의 minibatch마다 overfitting heuristic에 근간하여 값을 조절한다. p는 0~1 사이 값을 가지도록 강제함.
저자들은 이를 Adaptive Discriminator Augmentation (ADA)라고 칭한다.
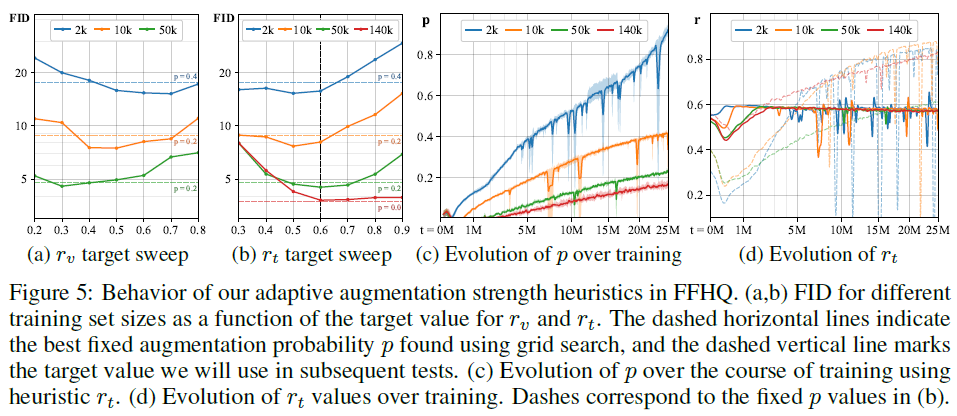
Figure 5. (a,b) : $r_v, r_t$ 모두 overfitting을 방지하는데 영향이 있다. 그러나 더 사실적인 $r_t$를 p=0.6에 대해 사용한다.
Figure 5. (c) : 데이터의 양이 적을수록 높은 p를 사용하려는 경향이 있다. 2k training set에서는 거의 p=1에 해당하는 정도까지 값이 높아질만큼 augmentation을 사용한다.
Figure 5. (d) : 고정된 p는 초반에는 강하지만 후에 약한 모습(overfitting)을 보이지만 적응형 p를 사용할 경우 안정적임을 보여준다.
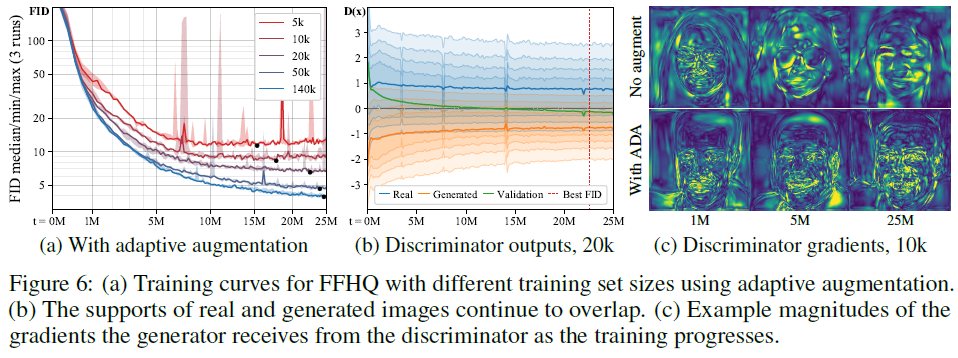
Figure 6. (a) Adaptive augmentation을 사용할 때 Figure 1 (a)와 비교하면 더 좋은 FID 값을 나타낸다.
Figure 6. (b) 역시 마찬가지로 overfitting이 더 이상 일어나지 않고 훈련 데이터 사이즈와 관계없이 수렴함을 보인다.
Figure 6. (c) ADA와 함께라면 gradient field는 더 자세한 detail 묘사를 진행한다.
4. Evaluation
4.1 Training from scratch

Figure 7. (a, b) : FFHQ와 LSUN CAT 데이터 세트의 적은 데이터일지라도 ADA 혹은 ADA+bCR을 사용한 모델의 FID가 더 좋다는 것을 보여준다.
Figure 7. (c) : 데이터의 양이 적을 때 ADA와 ADA+bCR인 경우의 Median FID가 좋게 나타났다. 다만 데이터의 양이 많을 때는 LSUN CAT의 경우 Baseline이 더 좋은 FID를 가진다.
Figure 7. (d) : bCR 단독으로 사용되는 것은 데이터 augmentation에 효과적이나 생성된 이미지에 누수가 발생되므로 주의해야한다.

Figure 8. (a) 다른 모델과 대비했을 때, 데이터의 양이 적을때 ADA를 사용한 방법의 FID가 가장 좋게 나왔다.
Figure 8. (b) Baseline 대비 ADA를 사용하는 것이 적은 데이터의 양에 대한 FID 역시 낮음을 확인할 수 있다.
4.2 Transfer learning

Transfer동안 discriminator의 고해상도 layer들을 freezing함으로써 좋은 결과를 보이는 논문들이 존재한다. (Freeze-D)
Figure 9. (a) ADA를 사용하지 않을 때, Freeze-D를 사용하는 것이 각각의 훈련 데이터의 양에 따른 결과 대비 수렴점에 따른 FID 성능이 더 좋다.
Figure 9. (b) ADA를 사용할 때는 사용하지 않을 때보다 훨씬 좋은 FID 성능을 보였으며 (a)와 마찬가지로 Freeze-D를 사용하는 것이 각각의 훈련 데이터의 양에 따른 결과 대비 수렴점에 따른 FID 성능이 더 좋다. 다만, 그 차이는 (a)와 같이 크게 차이나지는 않는다.
Figure 9. (c) ADA를 사용하는 것이 Baseline보다 더 성능이 좋으며 Transfer를 적용한 것이 그 다음으로 좋고, Freeze-D를 사용하는 것이 가장 좋은 결과를 만든다. 모든 상황에 대해서 데이터 세트 사이즈가 커질 수록 모두 FID가 좋아진다.
Transfer Learning은 처음부터 훈련시키는 것보다 더 좋은 결과를 보인다. 그리고 그 성공은 데이터 세트의 유사성보다 다양성에 주 원인이 있는 것처럼 보인다.
Figure 9. (d) CELEBA-HQ(사람 얼굴, 다양성이 적음), LSUN DOG(다양함) 두 데이터 세트로부터 Transfer할 때 다양성이 많은 LSUN DOG를 기저로 한 FID 성능이 좋음을 보인다.
4.3 Small datasets

다른 작은 데이터 세트에 대해서도 작동시켜봄.
METFACES, BRECAHAD, Animal faces (AFHQ), CIFAR-10

Figure 11. (a) 모든 실험해본 데이터 세트에 대해 ADA를 적용한 것의 FID와 KID 가 좋은 성과를 보였고 Transfer와 Freeze-D를 사용하면 도 좋은 결과를 도출할 수 있다.
Reference
공식 Github
https://github.com/NVlabs/stylegan2-ada-pytorch
GitHub - NVlabs/stylegan2-ada-pytorch: StyleGAN2-ADA - Official PyTorch implementation
StyleGAN2-ADA - Official PyTorch implementation. Contribute to NVlabs/stylegan2-ada-pytorch development by creating an account on GitHub.
github.com
도움이 되는 블로그
블로그 1.
https://happy-jihye.github.io/gan/gan-19/
[Paper Review] StyleGAN2-ADA #01: Training Generative Adversarial Networks with Limited Data 논문 분석
happy-jihye.github.io
블로그 2.
https://aruie.github.io/2020/10/28/ganwithlimiteddata.html
Training Generative Adversarial Networks with Limited Data
< Image Generation from Scene Graphs Training Generative Adversarial Networks with Limited Data --> --> 作者 | Aru --> > 파이썬 기초 정리
aruie.github.io
블로그 3.
Training Generative Adversarial Networks with Limited Data
작성자 - 백동희(donghee.paek@gmail.com)
www.notion.so
도움이 되는 YouTube
YouTube 1. 저자 Seminar
YouTube 2.
YouTube 3.
0000
