[논문 Summary] CSPNet (2020 CVPR) "CSPNet: A New Backbone that can Enhance Learning Capability of CNN"
[논문 Summary] CSPNet (2020 CVPR) "CSPNet: A New Backbone that can Enhance Learning Capability of CNN"
논문 정보
Citation : 2023.01.15 일요일 기준 1693회
저자
Chien-Yao Wang, Hong-Yuan Mark Liao, I-Hau Yeh, Yueh-Hua Wu, Ping-Yang Chen, Jun-Wei Hsieh
- Taiwan, Institute of Information Science Academia Sinica, National Chiao Tung University
논문 링크
Official
Arxiv
https://arxiv.org/abs/1911.11929
논문 Summary
Abstract

0. 설명 시작 전 Overview
Cross Stage Partial Network (CSPNet)을 활용하여 duplicate gradient information에 대한 문제를 해결함과 동시에 경량화와 더불어 나은 정확도를 유지할 수 있는 방법을 제안한다.
1. Paper Motivation
Neutral Network는 깊어지고(deepr) 넓어질수록(wider) 강력한 성능을 내지만 많은 computation이 필요로 한다.
이에 작은 device(ex) mobile etc)에서의 짧은 inference time을 요구하는 light-weight computing이 많은 관심을 받고 있다.
이에 성능에 대한 큰 희생없이 가벼운 backbone 모델을 위한 CSPNet(Cross Stage Partial Network)을 제안한다.
CSPNet을 사용하는 주 목적은 architecture의 계산량을 줄이면서 더 풍부한 gradient 조합을 가능하게 하기 위한 것이다.
기본 레이어의 feature map을 2 부분으로 분할한 다음 제안한 cross-stage hierarchy를 통해 병합합니다.
제안한 CSPNet 기반의 object detector는 3가지 문제를 다룬다.
1) CNN의 학습 능력을 강화한다.
- 일반적으로 경량화를 진행하면 기존의 CNN 방법의 정확도는 하락한다. 그러나 제안한 CSPNet을 ResNet, ResNeXt, DenseNet에 쉽게 적용한 이후 확인했을 때 CNN의 학습 능력을 강화시켜 10~20% 정도의 계산량을 감소시킴과 동시에 기존 모델 대비 높은 정확도를 얻을 수 있다.
2) computational bottleneck을 제거한다
- 높은 계산량을 요구하는 bottleneck은 inference 할 때 많은 cycle을 요구하거나 일부 산술 장치가 가동되지 않는다.
저자들은 CNN의 각 layer들이 비슷한 연산량으로 분배할 수 있다. 결국 CSPNet은 불필요한 에너지 소비를 줄인다.
3) memory 비용을 감소한다.
- cross-channel pooling을 채택하여 feature pyramid 상에서의 feature map을 압축하고 이를 통해 메모리의 사용량을 줄인다.

Figure 1에서 확인할 수 있듯 DenseNet-201-Elastic 대비 CSPDenseNet-201-Elasticsms 19% 낮은 BFLOPS(메모리 사용량)을 확인할 수 있다. 또한 ResNeXt-50의 경우도 마찬가지로 CSPResNeXt-50eh 22%의 BFLOPS가 낮아지고 정확도도 일부 상승함을 확인할 수 있다.
2-1. CSPNet


Figure 2를 의미하는 위 두 이미지에서 확인할 수 있듯 DenseNet을 예로 CSPNet의 설명을 이어가겠다.
DenseNet은 DenseConnection을 통해 output을 내놓고 Transition Layer를 통해 결과를 뽑아낸다.
그러나 CSPNet을 적용시킨다는 것은 초기 input feature map을 반으로 나눠 $x_{0_'}, x_{0_"}$로 분할한다.
이후 DenseNet의 모델을 통과시킨 후 Transition Layer에서 concatenate를 진행하고 conv를 마지막으로 진행한다.
이를 수식적으로 나타내면 다음과 같다.

DensNet을 통과시켰을 때 최종 feature map인 $x_k$는 위와 같이 나타낼 수 있다.

여기서 backpropagation을 진행하면 위 수식과 같이 나타나는데 DensNet의 구조적 특성상 앞 feature map이 역전파할 때 반복적으로 사용되는 것으로 나타난다. 이와 같은 gradient information의 재사용은 메모리를 더 많이 사용하게 하고 bottleneck을 만든다.
이에 CSPNet을 적용하면 다음과 같이 전개할 수 있다.

초기 feature map을 분할하였기 때문에 추후 concatenate를 진행할 때까지 해당 channel의 feature map만큼의 메모리 가중을 덜어줄 수 있고 이를 통해 CSPNet은 경량화를 진행할 수 있다.
결론을 지으면 CSPDenseNet은 DenseNet feature 재사용의 장점을 유지하면서 gradient flow를 절단함으로써 과도하게 중복되는 gradient 정보를 방지한다.

그러나 저자들이 제안한 Figure 3 (b) 형태말고도 다른 방식으로 분할 병합을 진행할 수 있지 않을까하는 생각을 할 수 있다.
여기서 저자들이 Figure 3 (c-d)를 통해 실험을 진행했다.

Figure 4에서 확인할 수 있듯 저자들이 제안한 방법인 CSPPeleeNet은 메모리도 줄어들고 정확도도 높아진 반면 다른 두 방법은 메모리 사용량은 줄었어도 정확도에서 하락한 것을 확인할 수 있다.
즉, 저자들이 제안한 방법과 같은 분할, 병합하는 것이 좋다고 판단된다.

그리고 앞서 이야기한 바와 마찬가지로 CSPNet은 다양한 기저 모델에 사용할 수 있기 때문에 ReNe(X)t에서도 적용이 가능함을 Figure 5에서 보여준다.
2-2. Exact Fusion Model

CSPNet 외 저자들은 Exact Fusion Model (EFM)을 제안함으로써 One-stage 객체 검출기에서는 각 anchor가 적절한 FoV(Field of View)를 갖도록하여 성능을 끌어 올릴 수 있음을 확인했다.
EFM은 YOLOv4을 기반으로하며 초기 feature pyramid를 더 나은 방향으로 aggregate할 수 있다.
물론, Feature map의 concatenation은 많은 계산량과 메모리 트래픽을 요구하기 때문에 Maxout을 적용하여 feature map을 압축하는 추가적인 장치가 필요하다
3. Experiments

저자들이 제안한 방법대로 진행했을 때 높은 정확도와 낮은 메모리 사용량을 확인할 수 있다. (Figure 4와 같이 확인)

CSPNet을 각 모델에 적용했을 때 메모리 사용량이 줄고 정확도가 향상했다.

Object Detection에서의 결과에서 EFM과 더불어 CSPNet을 적용한 모델이 가장 좋은 AP임을 확인할 수 있다.
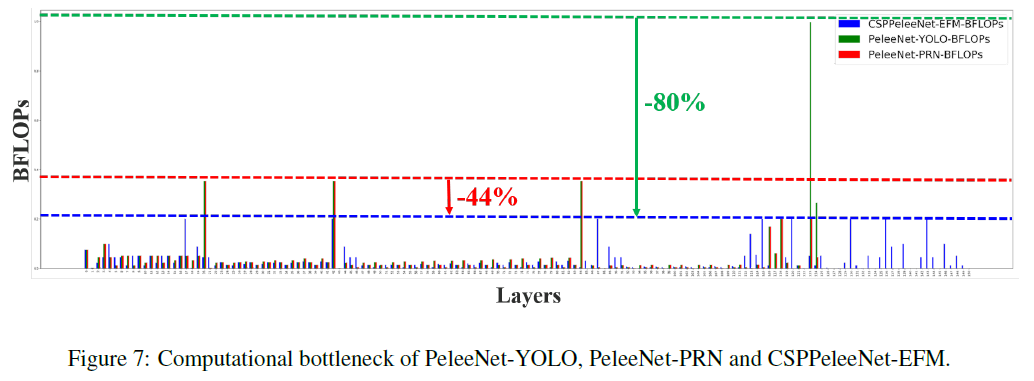
각 layer가 균일하게 활용될 수 있게 함으로써 bottleneck 계산량을 줄어드는 것을 확인할 수 있다.
4. Results
● We have proposed the CSPNet that enables state-of-the-art methods such as ResNet, ResNeXt, and DenseNet to be light-weighted for mobile GPUs or CPUs.
● Experimentally, we have shown that the proposed CSPNet with the EFM significantly outperforms competitors in terms of accuracy and inference rate on mobile GPU and CPU for real-time object detection tasks.
Reference
공식 Github
https://github.com/WongKinYiu/CrossStagePartialNetworks
GitHub - WongKinYiu/CrossStagePartialNetworks: Cross Stage Partial Networks
Cross Stage Partial Networks. Contribute to WongKinYiu/CrossStagePartialNetworks development by creating an account on GitHub.
github.com
