[논문 Summary] InstructPix2Pix (2023 CVPR) "InstructPix2Pix: Learning to Follow Image Editing Instructions"
[논문 Summary] InstructPix2Pix (2023 CVPR) "InstructPix2Pix: Learning to Follow Image Editing Instructions"
논문 정보
Citation : 2023.05.01 월요일 기준 34회
저자
Tim Brooks, Aleksander Holynski, Alexei A. Efros - University of California, Berkeley
논문 링크
Official
Arxiv
https://arxiv.org/abs/2211.09800
InstructPix2Pix: Learning to Follow Image Editing Instructions
We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the
arxiv.org
논문 Summary
Abstract

https://instruct-pix2pix.timothybrooks.com/instruct-pix2pix.mp4
0. 설명 시작 전 Overview
language model(GPT-3)과 text-to-image model(Stable Diffusion) 두 pretrained model을 결합하여 훈련 데이터를 구성하고 conditional diffusion model인 InstructPix2Pix를 통해 생성된 데이터로 훈련시킨다. 실제 이미지들과 user-written 지시들을 inference time동안 일반화시켜 사용한다.
추가적인 별도의 fine-tuning이나 inversion을 요구하지 않음. 빠름.
1. Introduction

Image editing을 위해 human-written instruction을 따르는 generative model을 훈련시키기 위한 방법을 제안
paired training data를 위해 language model(GPT-3)과 text-to-image model(Stable Diffusion) 두 pretrained model을 결합하여 생성.
생성된 paired data를 사용하여 conditional diffusion model에서 훈련함.
모델은 forward pass에서의 image edit이기 때문에 추가적인 예시 이미지가 필요하지 않고 example마다의 fine-tuning 역시 필요하지 않다.
본 모델은 임의의 real image와 natural human-written instruction을 통한 zero-shot genratlization을 달성하기에 다양한 edit이 가능하다.
2. Prior work
Composing large pretrained models
~
GPT3, Stable Diffusion 이 모델들을 활용해 paired multi-modal training data를 생성하는데 사용함.
Diffusion-based generative models
다양한 generative modalities 수행.
Generative models for image editing
~
본 모델은 단일 이미지와 instruction을 가지고 어떻게 이미지를 수정하는지 수행.
특별한 user가 그린 mask, 추가적인 이미지 또는 example마다의 inversion/fine-tuning 없이 forward pass에 대한 edit을 수행.
Learning to follow instructions
Training data generation with generative models
~
저자들은 두 generative model(language, text-to-image)를 사용하여 훈련 데이터를 생성하기 위해 사용
3. Methods

(1) paired training dataset 생성
(2) 생성된 dataset으로 image editing diffusion model 훈련
생성된 이미지와 editing instruction으로 훈련시켰음에도 불구하고, 본 모델은 임의의 human-written instruction을 사용하여 실제 이미지들을 editing하고 일반화할 수 있다.
-> 사람이 직접 instruction과 이미지를 제공하면 Instruction에 맞는 이미지 editing된 이미지를 생성해준다는 의미
3.1 Generating a Multi-modal Training Dataset
3.1.1 Genrating Instructions and Paired Captions

Figure 2 (a)에서 보이듯 Input Caption이 제공되었을 때 Instruction과 Edited Caption을 만들기 위해서 GPT-3를 finetuning하여 훈련시킨다.
여기서 우리가 필요한 것은 Input Caption, Edit Instruction, Output Caption 총 3개이다. (일종의 Supervised 형식)
이에 따라 700개의 input caption과 사람이 직접 적은 instruction과 output caption을 훈련데이터로 사용한다.
GPT-3 Davinci model을 1 epoch에 대하여 fine-tuning 진행
-> 이렇게 하면 Input Caption에 대하여 창의적이고 sensible instruction과 caption이 생성된다.
Input Caption은 큰 규모의 다양한 내용이 있고 다양한 medium이 존재하는 LAION dataset-Aesthetics로부터 caption한다.
LAION에 noise가 있는 단점은 dataset filtering과 classfier-free guidance로 완화시킴.
이를 통해 454,445개의 instruction과 caption corpus example을 구성
3.1.2 Genrating paired images from Paired Captions
Figure 2 (b)와 마찬가지로 Input Caption과 Edited Caption이 주어졌을 때 이미지를 Edit하기 위해 Stable diffusion을 사용한다. 그러나 image consistency의 유지를 위해 Prompt-to-Prompt를 사용한다.

Figure 3에서 확인할 수 있듯 Prompt-to-Prompt는 denoising step에서 cross attention weight를 수정함으로써 다른 prompt를 사용한 두 이미지간 유사성을 높이게 하는 방법이다.
denoising steps fraction인 p를 통해 두 이미지간 유사성을 조절할 수 있는 파라미터가 존재한다. 그러나 최적의 값을 찾는 것은 어렵기 때문에 caption pair 마다 100개의 sample 이미지 pair를 생성한다.
이후 CLIP 기반 metric을 사용하여 filter한다.
여기서 사용하는 CLIP space에서의 Directional Similarity는 두 이미지간의 변화와 두 이미지 caption간의 변화 consistency가 유사하도록 측정하는 metric으로 강건하며 다양하고 질 좋은 이미지를 만들도록 돕는다.
3.2 InstructPix2Pix
이제 만들어진 dataset을 Stable Diffusion에 fine-tuning한다.
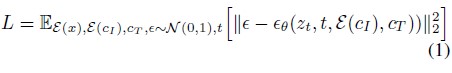
다만 image conditioning을 위해서 첫 conv layer의 input channel들을 추가함으로써 $z_t, \mathcal{E}(c_I)$을 concatenating한다.
이때의 초기 channel value는 0
3.2.1 Classifier-free Guidance for Two Conditionings
Classfier free Guidance는 diffusion model에의해 생성된 sample의 quality와 diversity의 trading off에 대한 향상된 방법론으로 data쪽으로 probability mass를 효율적으로 이동시킨다.
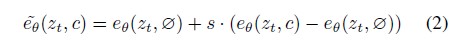
보통 conditioning $\e_\theta (z_t, c)$를 가깝게 하고 unconditioning $\e_\theta (z_t, \varnothing)$을 멀리하도록 수식이 주어진다.
본 모델은 image에 대한 것과 text instruction에 대한 conditioning을 고려해야하기에 아래와 같이 수식을 진행한다.

4. Results
4.1 Baseline comparison




SDEdit과 Text2Live와 비교를 진행
4.2 Ablations

CLIP filter를 사용하는 것이 더 좋다. 제거하면 image consistensy가 감소한다.

Classifier-free guidance의 weight별 결과로
$s_T$가 높을수록 강한 edit이 진행. 5~10
$s_I$가 높을수록 원본 이미지의 공간적 구조가 보존됨. 1~1.5
$s_T, s_I$가 각각 5~10, 1~1.5가 좋은 결과
5. Discussion


비교적 좋은 결과물들을 보였으나 한계점이 분명하고 좋지 못한 결과들이 나올 때가 존재.
이는 사용한 large model들의 bias가 영향을 주었음을 고려함.
Appendix
Appendix A. Implementation Details
Appendix B. Classfier-free Guidance Details
Reference
공식 Github
https://github.com/timothybrooks/instruct-pix2pix
GitHub - timothybrooks/instruct-pix2pix
Contribute to timothybrooks/instruct-pix2pix development by creating an account on GitHub.
github.com
공식 Blog
https://www.timothybrooks.com/instruct-pix2pix/
InstructPix2Pix
We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the
www.timothybrooks.com
Demo
https://huggingface.co/spaces/timbrooks/instruct-pix2pix?ref=louisbouchard.ai
InstructPix2Pix - a Hugging Face Space by timbrooks
huggingface.co
도움이 되는 YouTube 1. PR-413 - Doyup Lee
