[논문 Summary] PerSAM (2023.05 arxiv) "Personalize Segment Anything Model with One Shot"
[논문 Summary] PerSAM (2023.05 arxiv) "Personalize Segment Anything Model with One Shot"
논문 정보
Citation : 2023.06.30 금요일 기준 4회
저자
Renrui Zhang, Zhengkai Jiang, Ziyu Guo, Shilin Yan, Junting Pan, Hao Dong, Peng Gao, Hongsheng Li
논문 링크
Official
Arxiv
https://arxiv.org/abs/2305.03048
Personalize Segment Anything Model with One Shot
Driven by large-data pre-training, Segment Anything Model (SAM) has been demonstrated as a powerful and promptable framework, revolutionizing the segmentation models. Despite the generality, customizing SAM for specific visual concepts without man-powered
arxiv.org
논문 Summary
Abstract

0. 설명 시작 전 Overview
SAM을 활용한 Personalization approach에 대한 방안으로 PerSAM과 PerSAM-F을 제안.
단일 이미지와 이에 상응하는 mask를 3단계에 걸쳐 진행함으로써 효과적인 성능 결과를 확인 가능
1) target-guided attention
2) target-semantic prompting
3) cascaded post-refinement
mask의 ambiguity를 완화하기 위해 단 2개의 parameter에 대해 10초간 fine-tuning을 진행.
이를 PerSAM-F라 칭하며 성능이 좋아졌다고 함. Figure 2 참조
Dreambooth에서도 본 방법을 활용함으로써 더 좋은 personalize 결과 도출 가능.
1. Introduction
Segment Anything(SAM)에 대한 일반화된 segmentation mask 결과 도출은 놀라운 결과임이 자명하지만 특정 visual concept을 segment하는 확장성에서 부족함이 있다.
더욱이 SAM은 labor-intensive하고 time-consuming
뿐 아니라 각기 다른 pose나 context에서 정확한 target object의 위치를 특정하고 정확한 prompt를 통한 SAM의 활성화로 segment를 진행해야 한다.
여기서 저자들은 자문해본다.
Can we personalize SAM to automatically segment unique visual concepts in a simple and efficient manner?
간단하고 효율적인 방법으로 독특한 visual concept의 segment를 자동화하기 위한 personalize SAM을 만들 수 없을까?
여기서 저자들은 훈련이 필요없는 PerSAM을 제안한다.

Figure 1에서 제안한 바와 같이 1장의 이미지와 mask를 SAM의 이미지 encoder에 넣고 embedding을 encoding함.
test image의 모든 픽셀과 segment한 object 간의 feature similarity를 계산한다.
SAM decoder 처리에 있어 3가지 tech를 도입
1) Target-guided attention : 계산된 feature similarity로 SAM decoder의 token-to-image cross-attention layer를 guide
2) Target-semantic prompting : original low-level prompt token과 target object embedding의 결합으로 decoder에 더 충분한 visual cues를 제공.
3) Cascaded post-refinement : 더 섬세한 segmentation 결과를 위해 two-step post-refinement strategy 채택. 100ms
PerSAM 자체만으로도 장점이 있으나 ambiguity가 생기는 문제가 발생
SAM은 freeze하고 10초내 2개의 parameter를 fine-tune하는 PerSAM-F를 제안

employ learnable relative weights for each scale, and conduct a weighted summation as the final mask output.
각 scale마다의 상대적 학습가능한 weight를 채택하여 마지막 mask output에 weighted sum을 수행
the ambiguity issue can be effectively restrained by efficiently weighing multi-scale masks.
the identifier simultaneously include the visual information of backgrounds in the given images ... enabling more diverse
and higher-fidelity synthesis.
Dreambooth에서도 identifier가 객체 뿐 아니라 배경의 시각 정보를 포함하는 경우가 있어 문제가 생기지만 본 방법을 추가함으로써 더 나은 성능을 보임
요약
1) Personalized Segmentation Task : 최소한의 비용으로 customize segmentation이 가능할 것인지를 제안
2) Efficient Adaption of SAM : PerSAM, PerSAM-F 제안
3) Personalization Evaluation : PerSeg라는 segmentation dataset 제공
4) Better Personalization of Stable Diffusion : DreamBooth와 같은 personalized generation 성능 향상
2. Related work
Segmentation in Vision
SAM 짱짱맨
Foundataion Models
Bert, GPT, LLaMA, CLIP, CaFO,등 이있지만 SAM 말하고 싶어함
Parameter-efficient Fine-tuning
큰 모델에 대한 학습 어려우니 parameter efficient 방법들이 제안되어옴.
Prompt Tuning, LoRA, Adapter가 있음
3. Methods
3.1 Preliminary
A Revisit of Segment Anything
Personalized Segment Task
3.2 Training-free PerSAM
Positive-negative Location Prior
Target-guided Attention
Target-semantic Prompting
Cascaded Post-refinement
3.3 Fine-tuning of PerSAM-F
Ambiguity of Mask Scales
Learnable Scale Weights
3.4 Better Personalization of Stable Diffusion
A Revist of Dreambooth
PerSAM-assisted Dreambooth
4. Experiments
4.1 Personalized Evaluzation
PerSeg Dataset
Experimental Details
Performance
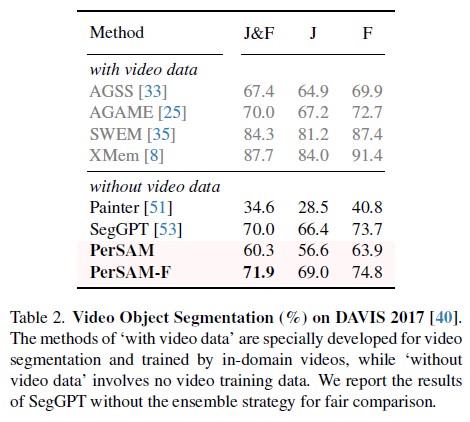
4.2 Video Object Segmentation
Experimental Details
DAVIS 2017 [40] dataset for evaluation
official J and F scores as metrics.
For PerSAM-F, we conduct one-shot fine-tuning on the first frame for 800 epochs with a learning rate $4^{-4}$
Performance

4.3 PerSAM-assisted Dreambooth
Experimental Details
1,000 iterations within 5 minutes on a single NVIDIA A100 GPU.
PerSAM-assisted DreamBooth
Performance
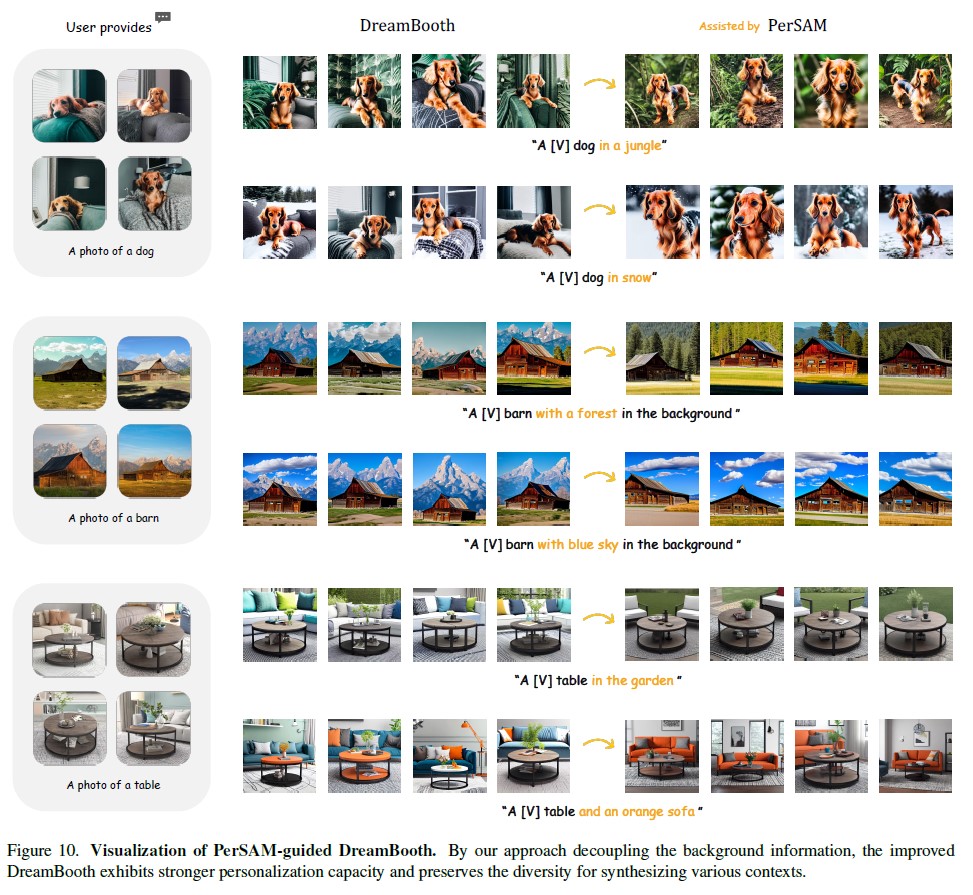
객체와 배경이 잘 분리됨
4.4 Ablation Study

5. Discussion
What is the Difference between SegGPT and PerSAM?
Painter and SegGPT contain 354M learnable parameters and unify a diverse set of segmentation data for large-scale
training.
In contrast, our approach is either training-free, or fine-tuning only 2 parameters within 10 seconds.
We aim at a more efficient way to customize an off-the-shelf foundation model
Can PerSAM tackle Multi-object Scenarios?
Robustness to Quality of the One-shot mask
Reference
공식 Github
https://github.com/ZrrSkywalker/Personalize-SAM
GitHub - ZrrSkywalker/Personalize-SAM: Personalize Segment Anything Model (SAM) with 1 shot in 10 seconds
Personalize Segment Anything Model (SAM) with 1 shot in 10 seconds - GitHub - ZrrSkywalker/Personalize-SAM: Personalize Segment Anything Model (SAM) with 1 shot in 10 seconds
github.com
도움이 되는 Blog 1. PerSAM 간략 요약
Personalize Segment Anything Model with One Shot (PerSAM)
SAM(Segment Anything Model) 개인화&자동화 arXiv Github Abstract SAM(Segment Anything Model)을 위한 개인화 접근 방식인 PerSAM 제안. 또한 학습 가능한 가중치를 도입하여 더욱 효율적인 변형인 PerSAM-F 제안. 제안한
ostin.tistory.com
0000
