[논문 Summary] DreamPose (2023.04 arxiv) "DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion"
[논문 Summary] DreamPose (2023.04 arxiv) "DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion"
논문 정보
Citation : 2023.08.30 수요일 기준 4회
저자
Johanna Karras, Aleksander Holynski, Ting-Chun Wang, Ira Kemelmacher-Shlizerman
논문 링크
Official
https://grail.cs.washington.edu/projects/dreampose/
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
Given an image of a person and a sequence of body poses, DreamPose synthesizes a photorealistic, temporally consistent fashion video that maintains the fine details of the input image and follows the poses.
grail.cs.washington.edu
Arxiv
https://arxiv.org/abs/2304.06025
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
We present DreamPose, a diffusion-based method for generating animated fashion videos from still images. Given an image and a sequence of human body poses, our method synthesizes a video containing both human and fabric motion. To achieve this, we transfor
arxiv.org
논문 Summary
Abstract

DreamPose : 이미지를 통해 diffusion 기반의 animate fashion video를 생성하는 방법 제안.
image, human body pose sequence가 주어지면 사람과 fabric motion을 합성하여 비디오로 보여줌.
Stable Diffusion과 같은 pretrained text2image model을 pose-and image guided video synthesis model로 변환.
이때 UBC Fashion dataset을 활용한 새로운 finetuning 전략이 사용.
평가하고 증명.
0. 설명 시작 전 Overview
Dreampose
입력 : 1장의 이미지 + 여러 sequece pose
Contribution :
1) pretrained Stable Diffusion의 구조적 변화
2) 2 stage fine-tuning method 제안
이를 통한 Video generation model을 구성할 수 있게 했다.
1. Introduction

Fashion photography는 유명하지만 정보가 제한적이고 의류에 대한 뉘앙스에 대한 부분을 알기 어렵다. 이에 반해 Fashion video는 많은 양의 정보를 제안하지만 상대적으로 적다.
저자들은 pose sequence를 사용한 사실적이고 animate된 비디오를 만드는 DreamPose를 제안한다. 이 방법은 Stable Diffusion 기반의 Diffusion video synthesis model이다.
단일 이미지 + pose sequence를 통해 비디오 생성 가능.
물론, 이는 매우 어려운 작업이다.
- image diffusion model과 달리 비슷한 결과를 내지 못하고 textural motion에 제한적.
- poor temporal consistency, motion jitter, lack of realism, 그리고 the inability to control the motion or detailed object appearance으로 고통받는다.
이는 현존하는 모델이 text condition되어지기 때문. 만약 motion과 같은 signal을 conditioning으로 한다면 조금 더 섬세한 제어가 가능.
저자들의 방법인 image-and-pose conditioning scheme은 외형의 fidelity를 높여주고 frame-to-frame consistency이 가능하게 한다.
이를 달성하기 위해
- 저자들은 Stable Diffusion의 encoder와 conditioning mechanisms를 redesign함으로써 aligned-image과 unaligned-pose conditioning이 가능하게 함.
- UNet과 VAE finetuning을 동시에 처리하기 위한 a two-stage finetuning scheme 제안.
To summarize, our contributions
(1) DreamPose: an image-and-pose conditioned diffusion method for still fashion image animation
(2) a simple, yet effective, pose conditioning approach that greatly improves temporal consistency across frames
(3) a split CLIP-VAE encoder that increases the output fidelity to the conditioning image
(4) a finetuning strategy that effectively balances image fidelity and generalization to new poses.
2. Related Work
2.1 Diffusion models
impressive results in text-conditioned image synthesis, video synthesis and 3D generation tasks
However, training these models from scratch is computationally expensive and data intensive.
Latent Diffusion Models
our work leverages a pretrained Stable Diffusion model with subject-specific finetuning.
2.2 Still Image Animation
image animation refers to the task of generating a video from one or more input images
multiple separate networks. ex.
end-to-end single-network approaches. ex.
2.3 Fashion Image Synthesis
pose-guided fashion image synthesis methods - GAN 기반 방법
그러나 large pose changes, synthesizing occluded regions, and preserving garment style에 어려움.
최근 접근법 attention-based mechanisms
diffusion-based fashion image and video synthesis.
ex) DiffFashion, PIDM
2.4 Diffusion Models for Video Synthesis
Many text-to-video diffusion models rely on adapting text-to-image diffusion models for video synthesis
그러나 struggle to match the realism
처음부터 훈련시키기도 하지만
문제점 : requiring expensive computational resources, huge training datasets, and extensive training time
Tune-A-Video finetunes a text-to-image pretrained diffusion model for text-and-image conditioned video generation
Tune-A-Video 어려움 : exhibit textural flickering and structural inconsistencies.
2.5 Conditioning Mechanisms for Diffusion Models
While effective at controlling high-level details, text conditioning fails to provide rich, detailed information about the exact identity or pose of a person and garment.
이를 해결하기 위한 다양한 시도 image conditioning
ex) DreamBooth, PIDM, DreamPose
저자들의 방법 : CLIP and VAE를 섞은 것으로부터 image embedding을 추출하여 UNet의 cross-attention layer에 통합시키는 image conditioning approach를 사용. 이를 통해 smooth, temporally consistent motion을 달성.
3. Background
Diffusion model의 장점과 방법 설명
LDM에 대한 설명(process에 대한 개괄)
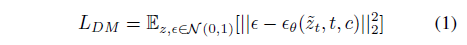
Classifier-free guidance에 대한 설명
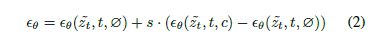
4. Method
Our method aims to produce photorealistic animated videos from a single image and a pose sequence
fine-tune a pretrained Stable Diffusion model on a collection of fashion videos.
4.1 Overview

At inference time, we generate each frame independently
4.2 Architecture

The DreamPose model is a pose- and image-conditioned image generation model that modifies and finetunes the original text-to-image Stable Diffusion model for the purpose of image animation.
objectives
(1) faithfulness (2) visual quality (3) temporal stability
DreamPose requires an image conditioning mechanism that captures the global structure, person identity, and fine-grained details of the garment, as well as a method to effectively condition the output image on target pose while also enabling temporal consistency between independently sampled output frames
4.2.1 Split CLIP-VAE Encoder
our network aims specifically to produce images which are not spatially aligned with the input image.
we implement image conditioning by replacing the CLIP text encoder with a custom conditioning adapter that combines the encoded information from pretrained CLIP image and VAE encoders.
given that Stable Diffusion and CLIP, it seems natural to simply replace the CLIP conditioning with the embedding derived from the conditioning image.
CLIP image embeddings alone are insufficient for capturing fine-grained details in the conditioning image.
additionally input the encoded latent embeddings from Stable Diffusion’s VAE.
add an adapter module A that combines the CLIP and VAE embeddings to produce one embedding
This adapter blends both the signals together and transforms the output into the typical shape
the weights corresponding to the VAE embeddings are set to zero, such that the network begins training with only the CLIP embeddings
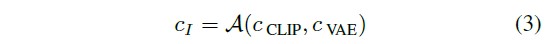
4.2.2 Modified UNET
concatenate the noisy latents $\tilde{z_i}$with a target pose representation $c_p$
we set $c_p$ to consist of five consecutive pose frames: $c_p = {p_{i-2}; p_{i-1}; p_i; p_{i+1} p_{i+2}}$
that individual poses are prone to frame-to-frame jitter, but training the network with a set of consecutive poses increases the overall motion smoothness and temporal consistency.
modify the UNet input layer to take in 10 extra input channels, initialized to zero,
4.3 Finetuning

초기
initialized from a pretrained text-to-image Stable Diffusion checkpoint, except for the CLIP image encoder which is loaded from a separate pretrained checkpoint
DreamPose is finetuned in two stages
The first phase fine-tunes the UNet and adapter module on the full training dataset in order to synthesize frames consistent with an input image and pose.
The second phase refines the base model by fine-tuning the UNet and adapter module, then the VAE decoder, … to create a subject-specific custom model used for inference.
sample-specific finetuning is essential to preserving the identity of the input image’s person and garment, as well as maintaining a consistent appearance across frames.
However, simply training on a single frame and pose pair quickly leads to artifacts
To prevent this, we augment the image-and-pose pair at each step, such as by adding random cropping.

finetuning the VAE decoder is crucial for recovering sharper, more photorealistic details in the synthesized output frames
4.4 Pose and Image Classifier-Free Guidance

$c_I$ : image conditioning
$c_p$ : pose conditioning
dual classifier-free guidance prevents overfitting
two guidance weights : $s_I, s_p$
large $s_I$ : high appearance fidelity
large $s_p$ : ensure alignment to the input pose
prevent overfitting
5. Experiments
5.1 Implementation Details
512x512 해상도 2개의 NVIDIA A100으로 훈련
Training
1) finetune our base model UNet on the full training dataset for a total of 5 epochs at a learning rate of 5e-6.
batch size of 16
dropout scheme where null values replace the pose input 5% of the time, the input image 5% of the time, and both input pose and input image 5% of the time during training.
2) finetune the UNet on a specific sample frame for another 500 steps with a learning rate of 1e-5 and no dropout.
3) finetune the VAE decoder only for 1500 steps with a learning rate of 5e-5.
Inference
use a PNDM sampler for 100 denoising steps
5.2 Dataset
UBC Fashion dataset
Dwnet: Dense warp-based network for poseguided human video generation, 2019 BMVC
https://github.com/zpolina/dwnet
339 training and 100 test videos.
a frame rate of 30 frames/second, 12 seconds long
training, randomly sample pairs of frames from the training videos
6. Results
6.1 Comparisons
quantitatively & qualitatively
Motion Representations for Articulated Animation (MRAA) [39]
Thin-Plate Spline Motion Model (TPSMM) [53].
UBC Fashion Dataset에 동일한 script와 epoch로 처음부터 학습시킨 것을 비교
We run PIDM and our method with 100 denoising steps.
6.1.1 Quantitative Analysis

test all models on the UBC Fashion test set, consisting of 100 unique fashion videos, at 256px resolution
extract 50 frames for testing
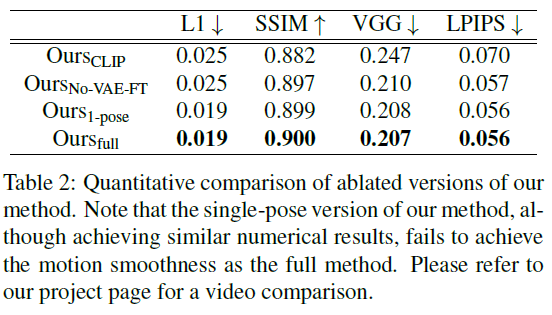
the full DreamPose model quantitatively outperforms both methods in all four quantitative
metrics
6.1.2 Qualitative Analysis

With MRAA and TPSMM, note that the person identity, fabric folds, and fine patterns are lost in new poses, whereas DreamPose accurately retains those details. Plus, during large pose changes, MRAA may produce disjointed limbs.

PIDM synthesizes realistic faces
both the identity and the dress appearance vary frame-to-frame
6.2 Ablation Studies
(1) $Ours_{CLIP}$: We use a pretrained CLIP image encoder, instead of our dual CLIPVAE encoder
(2) $Ours_{No-VAE-FT}$ : We do subject-specific finetuning of the UNet only, not the VAE decoder
(3) $Ours_{1-pose}$ : We concatenate only one target pose, instead of 5 consecutive poses, to the noise
(4) $Ours_{full}$ : Our full model, including subject-specific VAE finetuning, CLIPVAE encoder, and 5-pose input.
Quantitative Analysis
100 predicted video frames selected from each of the 100 test videos of the UBC Fashion dataset
Qualitative Analysis
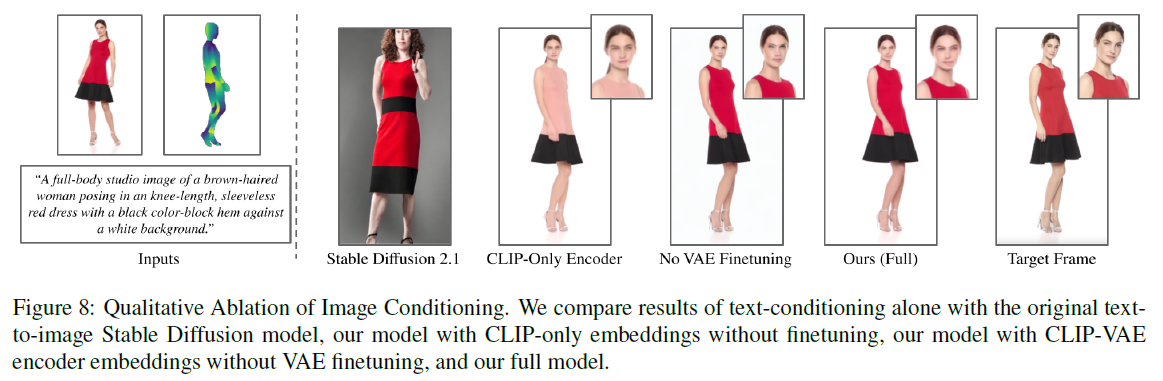
- CLIP text encoder를 통한 text-only conditioning은 의류나 사람의 identity 보존이 어려움.
- 단순히 text encoder를 CLIP image encoder로 바꾸는 것만으로도 더욱 나은 이미지 디테일을 살릴 수 있지만, 외형에 대한 정보 손실이 존재.
- DreamBooth와 같은 방식의 Subject-specific UNet finetuning은 얼굴과 의류의 사실적인 디테일 보존에 중요
- the VAE decoder를 fine-tuning하는 것은 detail을 더욱 선명하게 만들어주고 input pose에 대해 overfitting이 일어나지 않는다.
6.3 Multiple Input Images

additional input images of a subject increase the quality and viewpoint consistency
7. Limitations & Future Work
한계 : limbs disappearing, hallucinated dress features, directional misalignment
개선 방법 가능성 : some of these failures could be alleviated with improved pose estimation, a larger dataset, or a segmentation mask.
Future Work(temporal consistensy) : Achieving better temporal consistency on such patterns, ideally without subject-specific finetuning, is left to future work
Future Work(Time ): Fine-tuning the model on a specific subject takes approximately 10 minutes for the UNet and 20 minutes for the VAE decoder, in addition to an 18 second per-frame rendering time.
Reference
공식 Github
https://github.com/johannakarras/DreamPose
GitHub - johannakarras/DreamPose: Official implementation of "DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion"
Official implementation of "DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion" - GitHub - johannakarras/DreamPose: Official implementation of "DreamPose: Fashion Image...
github.com
https://grail.cs.washington.edu/projects/dreampose/
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
Given an image of a person and a sequence of body poses, DreamPose synthesizes a photorealistic, temporally consistent fashion video that maintains the fine details of the input image and follows the poses.
grail.cs.washington.edu
