[논문 Summary] Nerfies (2021 ICCV) "Nerfies: Deformable Neural Radiance Fields"
논문 정보
Citation : 2024.01.27 토요일 기준 871회
저자
Keunhong Park, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Steven M. Seitz, Ricardo Martin-Brualla
- University of Washington, Google Research
논문 링크
Official
Arxiv
https://arxiv.org/abs/2011.12948
공식 Github
https://github.com/google/nerfies
논문 Summary
Abstract
핸드폰을 사용해서 찍은 사진이나 비디오를 활용하여 사실적인 defromable scene을 재구성할 수 있는 방법 제안.
deformable scene (변형할 수 있는 장면)
→ 장면 속 객체나 요소, 환경과 같은 것들이 유연하게 형태가 변형되거나 조절될 수 있음을 나타낸다.
NeRF를 확장하여 deformation field를 만뜰 때 local minima에 빠지는 문제가 있어 coarse-to-fine optimization 방법으로 보다 강건한 최적화가 가능하게 한다.
여기에 기하학적 처리와 물리적 시뮬레이션의 원리를 적용하는 elastic regularization을 deformation field에 제안하여 더 강건하게 한다.
결과적으로 임의의 viewpoint에서도 사실적인 객체 rendering 결과를 확인할 수 있는 방법을 제안.
1. Introduction
고품질 3D human scanning은 엄격히 통제된 특화된 lab에서만 진행될 수 있었지만, 저자들은 휴대폰 카메라로 사실적인 모델을 만드는 방법에 대한 동기로 시작했다.
휴대폰을 통해 사람을 모델링할 때 2가지 어려움이 존재한다.
1) nonrigidity (유연성이라고 해석되지만 여기서는 고정되지 않는 불안정성정도로 해석 가능. 이는 휴대폰을 움직일 때, 객체가 고정되지 않음을 표현하기 위한 단어. 아무리 움직이지 않으려고 해도 작은 떨림이 발생하게 되기 때문.)
2) 머리, 안경, 귀걸이 같은 물질의 재구성에 대한 어려움

여기에 저자들은 free-viewpoint 시각화가 가능한 높은 신뢰도를 가지는 3D 재구성 모델을 NeRF를 통해 제안하고, nerfies(NeRF + Selfies)라 명명한다.
NeRF의 radiance field와 같이 deformation field를 MLP를 통해 표현하지만, 엄격한 제한없이 사용하면 왜곡이나 overfitting이 발생한다.
이에 elastic energy formation을 도입하지만, 여기서는 간단한 regularization 방식을 도입한다.
또한, deformation field 최적화 robust를 위해서 새로운 coarse-to-fine optimization scheme를 제안한다.( positional encoding)
Summary
1) an extension to NeRF to handle non-rigidly deforming objects that optimizes a deformation field per observation
2) rigidity priors suitable for deformation fields defined by neural networks
3) a coarse-to-fine regularization approach that modulates the capacity of the deformation field to model high frequencies during optimization
4) a system to reconstruct free-viewpoint selfies from casual mobile phone captures.
2. Related work
Non-Rigid Reconstruction
Domain-Specific Modeling
Coordinate-based Models
Concurrent Work
3. Deformable ENeural Radiance Fields

3.1 Neural Radiance Fields
(생략 : NeRF 설명)
서로 다른 카메라로부터 교차하는 2개의 ryas는 반드시 동일 color를 산출해야한다는 사실에 기반한 NeRF 훈련 절차가 필요하지만, 실제로는 정적이지 않은 많은 scene때문에 어렵다.
3.2 Neural Deformation Fields

정적이지 않는 장면들의 한계를 극복하기 위해 NeRF를 확장하여 활용.
직접적으로 ray를 쏘는 방식 대신 장면의 표준 template를 사용한다. 표준 template는 장면에 대한 상대적 구조와 appearance를 포함한다. 기존방식 DynamicFusion & Neural Volumes는 deformation을 mesh point와 voxel grid에 각각 정의했지만, 여기서는 MLP로 모델링함.
방식은 간단.
n장의 관찰된 frame에 대해서 observation-to-canonical deformation 수행
즉, 미리 학습한 i번째 프레임별 latent deformation code $w_i$를 조건으로 하는 $T$ mapping을 통해 observation-space coordinate $x$ → canonical-space coordinate로 변환한다.

다만, translation field에서의 포인트들의 회전은 각 포이트별 다른 translation이 필요
Ratation

Translation
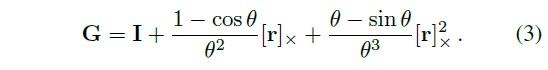
3.3 Elastic Regularization

deformation field는 최적화를 어렵게 하는 모호성을 추가한다. 이런 모호성은 제한이 덜한 최적화 문제를 야기하고 결국 설득력이 부족한 결과나 artifact가 생성된다.
고로 설득력있는 해결을 위한 prior 도입이 필요하다.
보통 geometry processing과 physics simulation에서 유연한 deformation을 모델링하기 위해서 elestic enegy를 사용한다.
- 여기서 elestic energy는 rigid motion에서의 local deformation 미분을 측정하는 방법을 의미.
저자들도 여기에서 영감을 받아 연속적인 deformation field의 맥락 속에서 비슷한 개념을 적용
Elastic Energy
위에서 언급한 Deformation Field $T$에 있어 한 점 $x$에서의 Jacobian $J_T(x)$는 변환에 있어 최선의 선형 근사를 나타낸다.
그러므로 저자들은 $J_T$를 통해 deformation의 local 행동 제어를 진행한다.
다만, 다른 방식들과 달리 MLP의 자동 미분을 통해 $J_T$를 직접적으로 계산한다.
이때, penalize를 위해 SVD ($\mathbf{J}_T = \mathbf{U} \boldsymbol{\Sigma}\mathbf{V}^T $)를 통해 closet rotaion으로부터의 미분을 penalize $\parallel \mathbf{J}_T - \mathbf{V} \mathbf{U}^T \parallel_F^2$
여기서 저자들은 $ \mathbf{J}_T $의 singular value를 사용하기로 하였는데 log를 취한 singular value는 수축과 확장에 있어 비슷한효과를 낸다고 보았기 때문이고 성능 역시 좋게 나타났다.

Robustness
아무리 사람이 대부분 경직된 상태로 있는다 하더라도 그 가정을 깨는 얼굴 표정과 같은 움직임이 존재한다. 그렇기에 저자들은 robust loss를 사용하여 정의하는 elestic energy로 remap한다.

여기서 $\rho$는 Geman-McClure robust error function으로 c=0.03을 설정한다.
이를 통해 loss에 대한 미분을 0으로 만들어 훈련동안 outlier에 대한 영향력을 감소시킬 수 있게 한다.
Weighting
저자들은 ray를 따라 각 sample에서 elastic penlaty를 weight.
3.4 Background Regularization
움직임으로부터 배경을 막는 regularization term을 추가
static 3D point로부터 움직임을 penalize

3.5 Coarse-to-Fine Deformation Regularization
registration과 flow estimation 동안 흔한 trade-off는 미세한 모델링과 과격한 움직임 사이의 선택이다. 이는 과도하게 부드러운 결과를 만들거나 정확하지 않은 registration이 발생한다.
이때문에 coarse-to-fine strategy가 이 문제들을 회피하기 위해 사용되었고 비슷한 문제를 저자들고 겪기에 이를 활용한다.

Tancik et al. positional encoding parameter m에서 작은 m은 low-frequency bias 큰 m은 high-frequency bias 가 발생하는 연구. (https://aigong.tistory.com/616)
Figure 5에서 작은 m은 smile의 미세한 움직임을 포착하지 못하고, 큰 m은 머리의 올바른 회전에 실패.
그 이유는 template가 덜 최적화된 deformation field의 overfit되었기 때문.
이를 극복하기 위해 low-frequency bias로 시작해서 high-frequency bias로 끝나는 coarse-to-fine 접근법 제안.
Tancik et al.에 따르면 positional encoding은 NeRF의 Neural Tangent Kernel(NTK) 관점에서 설명할 수 있는데 이는 kernel의 조율가능한 bandwith를 제어함을 보여준다.
작은 freq는 wide kernel을 유도하고 underfitting 초래
큰 freq는 narrow kernel을 유도하고 overfitting 초래
저자들은 positional encoding의 freq band를 window하는 parameter $\alpha$를 통해 NTK의 bandwith를 부드럽게 anneal할 수 잇는 방법 제안.

4. Nerfies: Casual Free-Viewpoint Selfies
Camera Registration
Foreground Segmentation
5. Experiments
5.1 Implementation Details
NeRF 도입 + Softplus activation $ln(1+e^x)$을 density로 사용
full HD (1920x1080) 256 크고 작은 ray sample 사용.
8 dim : latent deformation & appearance code
80k iterration
$L_{total} = L_{rgb} + 10^{-3}L_{elastic-r} + 10^{-3}L_bg$
8 V100 일주일동안 full HD
cf) 비교를 위한 16hours 절반 해상도 학습 진행
5.2 Evaluation Dataset
5.3 Evaluation
Quantitative Evaluation

Qualitative Resutls

Elastic Regularization

Depth Visualization

Limitation
Reference
도움이 되는 YouTube 1. Official Video
https://youtu.be/MrKrnHhk8IA?si=-65xhELJSNeWW6Jk
도움이 되는 YouTube 2. 가짜연구소
https://youtu.be/Eu7vVwnvkIU?si=OnEp6p03ZcWqzcWQ
0000
