[논문 Summary] GECO (Arxiv 24.05) "GECO: Generative Image-to-3D within a SECOnd"
[논문 Summary] GECO (Arxiv 24.05) "GECO: Generative Image-to-3D within a SECOnd"
논문 정보 (Citation, 저자, 링크)
Citation : 2024.11.10 일요일 기준 4회
저자 (소속) : ( Chen Wang, Jiatao Gu, Xiaoxiao Long, Yuan Liu, Lingjie Liu ) [ University of Pennsylvania, Apple, The University of Hong Kong]
논문 & Github 링크 : [ Official ] [ Arxiv ] [ 공식 Github ]
논문 Summary
3D 생성의 2가지 접근법의 장점과 단점
score distillation은 인상적인 결과를 나타내지만, 시간 효율성이 제한된 광범위한 per-scene optimization을 요구함.
reconstruction 기반 접근법은 효과적인 방법이지만 불확실성을 다루는 능력의 제한으로 타협된 품질을 보임.
위 언급한 방법들로 구성된 2 단계 접근법 기반 GECO 모델을 통해 균형잡히고 효율성과 품질 모두를 잡은 결과를 도출.
0. 설명 시작 전 Overview
1. Introduction

3D digital assets은 중요도 대비 만들어내는데 노동 집약적이고 전문적인 스킬이 필요한 영역인 문제가 존재
이에 본 논문에서는 효율적으로 고품질 3D assets을 단일 이미지로 생성함과 동시에 빠르고 신뢰도 높은 재구성이 가능하도록 하고자 함.
기존 방법 1) score distillation을 활용한 pretrained 2D diffusion을 통한 3D neural representation distillation
단점 : 고품질 3D asset을 생성하지만, 단일 object의 최적화에 최소 30분 이상 걸림
기존 방법 2) reconstruction-based 방법을 통한 3D 생성 가속화 (e.g. PixelNeRF, LRM, TripoSR)
deterministic feed-forward model 훈련, 최소 1초 이내 생성
단점 : 근원적으로 풀수 없는 uncertainty issue (blurriness, 기하학적 불일치)
uncertainty issue를 해결하기 위해 text-to-3D generation 에 대한 diffusion model 생성 모델 통합 e.g. InstantMesh
장점 :reconstruction-based 방법보다 좋은 결과
단점 : multiple network inference 필요, 생성 7초 이상 걸림
저자들은 1초 이내 고품질 3D object 생성 가능한 GECO 제안
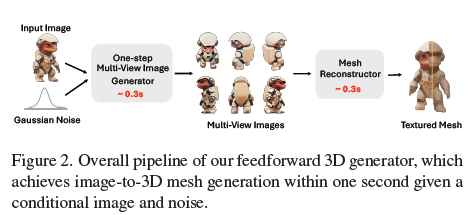
two-stage distillation approach 진행
1단계 : learn a single-step multi-view generator directly from a pre-trained multi-view diffusion model
2단계 : fine-tuning a pretrained reconstruction-based method with outputs of the single-step multi-view diffusion model from the first stage.
Our contributions can be summarized as the following:
• We design a novel feed-forward model for single-image-to-3D generation that, for the first time, handles the uncertainty
issue while achieving high efficiency.
• We propose a two-stage distillation method that efficiently distills a pre-trained multi-view diffusion model and a reconstruction-based model into a feed-forward image-to-3D generation model.
• Extensive experiments demonstrate that GECO achieves high-quality 3D generation within one second, outperforming
reconstruction-based methods in terms of quality and existing diffusion-based methods in generation speed.
2. Related work (생략)
Acceleration of Diffusion Models
3D Generation with Diffusion Models
Efficient 3D Generation
3. Preliminaries (생략)
3.1 Multi-view Diffusion Models
Diffusion Models
Multi-view Diffusion Models
3.2 3D Reconstruction Models
4. Method
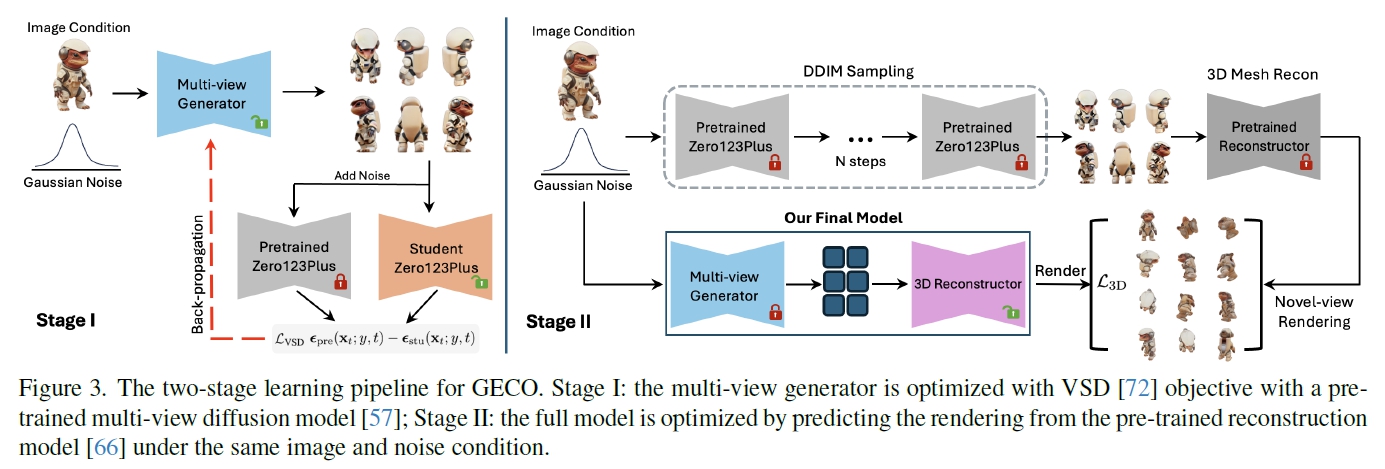
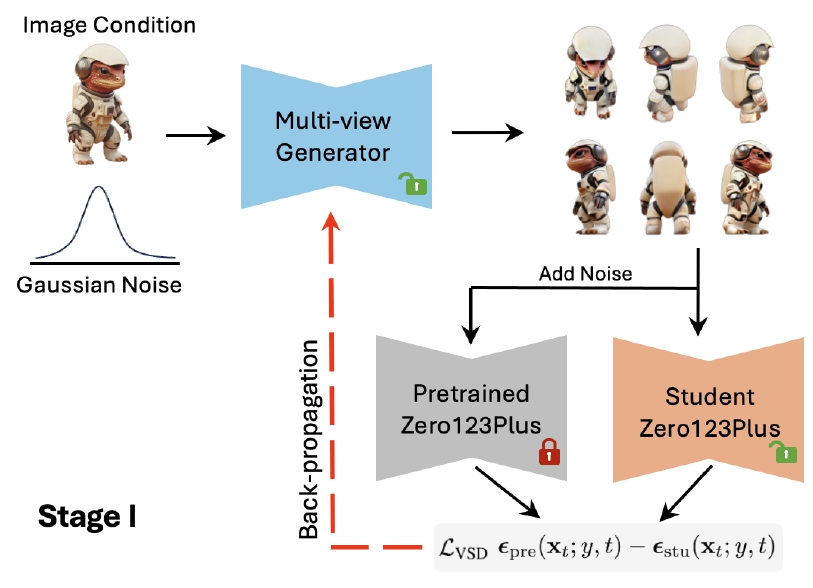
Stage 1 : 단일 이미지 + random noise $z$가 주어졌을 때, Single-Step Generator(Fig 3. Student Zero123Plus)를 학습시켜 3D representation.
Stage 2 : pretrained multi-view diffusion과 reconstruction가 주어졌을 때, distillation을 통한 모델 학습 진행. 이후 3D consistent distillation 알고리즘을 통해 fine-tuning
4.1 Stage 1: Multi-view Score Distillation
Variational Score Distillation (VSD)
VSD는 DreamFusion에서 제안한 SDS(Score Distillation Sampling)의 확장 버전으로 ProlificDreamer에서 제안.
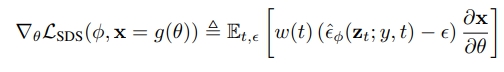
pretrained diffusion model : $p(x|y)$
3D rendering distribution (Multi-view Generator) : $q(x|y)$
둘 간의 KL divergence $D_{KL} (q(x|y)||p(x|y))$ 최소화를 통해 직접적으로 분포 $\theta$ 최적화 진행
첨언) Multi-view Generator가 pretrained Zero123Plus의 3D 모델 이미지를 생성할 수 있도록 Student model이 도와주는 것
Generative Modeling with VSD
ProlificDreamer는 고정된 particle 숫자를 통해 3D 분포를 매개변수화했지만 이 경우 새로운 샘플 생성 불가.
이 때문에 learnable generator $G(\theta)$ 도입.
$G$ Training Objective
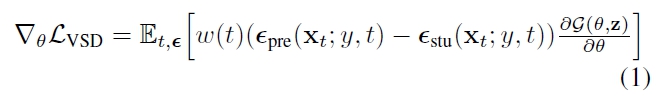
student model Objective
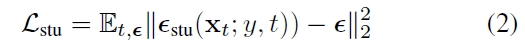
Multi-view Distillation
목표 1) random noise를 통해 VSD를 사용하는 3D representation mapping이 가능한 3D generator 학습하는 것
3D inductive bias 학습 향상을 위해 teacher model로 pretrained multi-view diffusion model을 활용
그러나 처음부터 학습시키면 mode collpase가 발생
이 문제에서 회피하기 위해 GECO는 Zero123Plus와 같은 pretrained multi-view diffusion model을 teacher model로 사용해, multi-view image를 중간 표현으로 먼저 학습.
Zero123Plus는 photorealistic하고 일관성을 높게 유지하는 6개의 뷰 이미지를 생성
기존 Zero123Plus가 noise image의 self-attention concatenate를 위한 reference attention 사용 대신 self-attention을 clean condition image에 직접 사용하여 정보 보존함.
$v$-prediction ~ $x_0$-prediction conversion 적용한 pretrained Zero123Plus로 generator 초기화
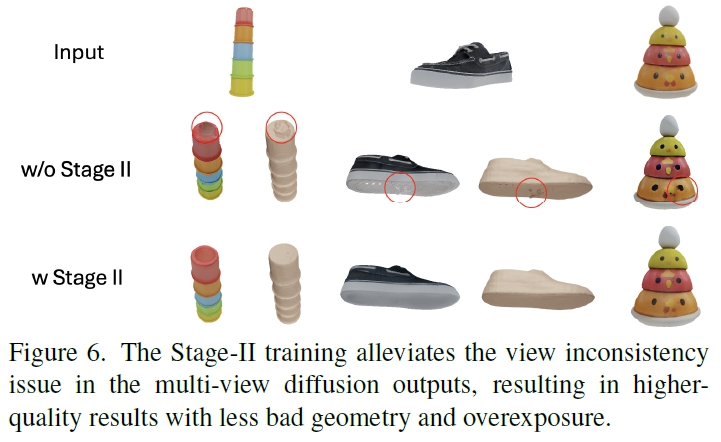
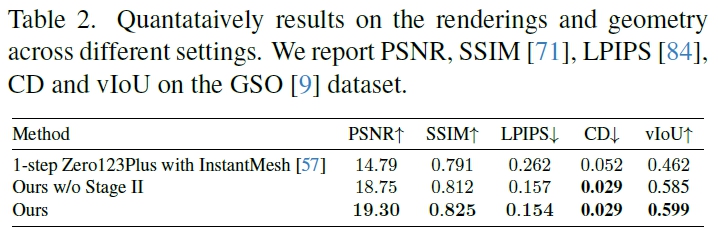
4.2 Stage 2: 3D Consistent Distillation
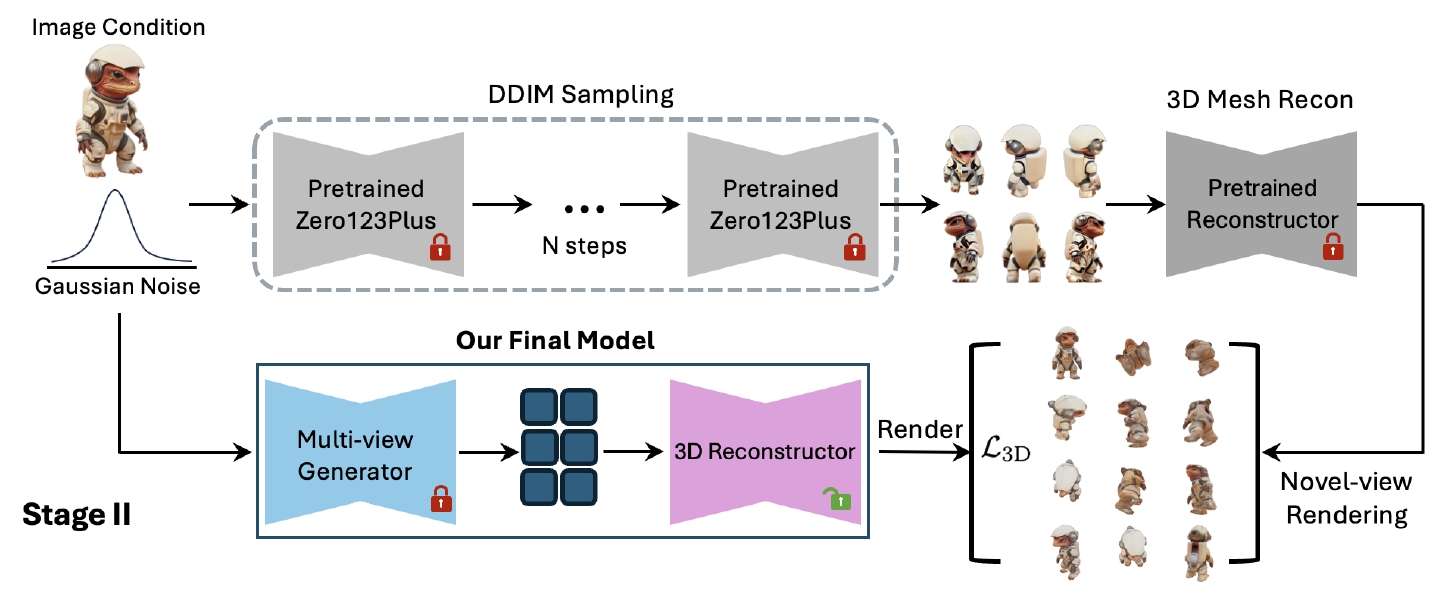
multi-view image로부터 object의 3D representation 추정해야하지만, one-step multi view generator $G(\theta)$는 원본 multi-view 이미지 대비 일관성이 낮을 수 있음.
때문에 이후 3D Reconstructor $R$의 입력으로 받아도 기하학적으로 문제 발생
이에 reconstruction model을 finetuing하는 distillation 단계를 통해 inconsistency 문제 해결하고자 함.
Zero123Plus의 DDIM sampling을 통해 획득한 $x_{mv}$
pretrained 3D reconstructor 통과 : $R(x_{mv})$ (Fig 3 윗 줄)
Stage 1에서 만든 one-step multi view generator와 3D Reconstructor 통과 (Fig 3 아랫 줄)
여기서 RGB loss와 LPIPS loss 계산을 통해 fine-tuning.
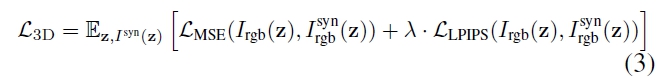
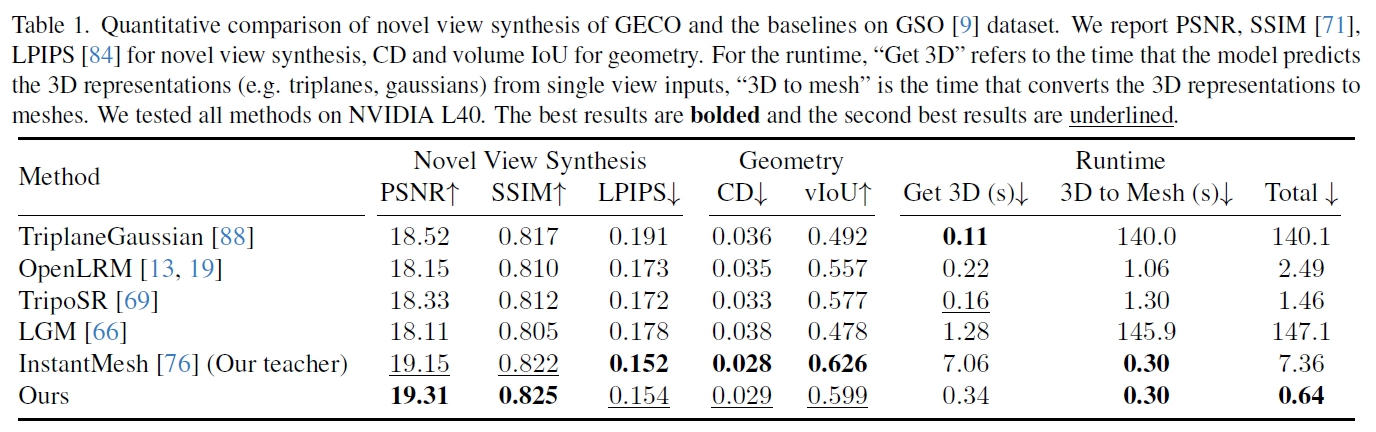
5. Experiments
Datasets
Objaverse dataset (46,000 objects) 중 LVIS
Multi-view Score Distillation
pretrained teacher Zero123Plus model & student Zero123Plus model
train the generator and student model on a single NVIDIA L40 GPU(80G) for 5, 000 steps.
fixed guidance scale of 4
3D Consistent Distillation
InstantMesh - our reconstruction network
Zero123Plus - deterministic 75-step DDIM scheduler
Inference
0.64s - each scene to generate 3D meshes on a single NVIDIA L40 GPU
1) 0.28s - for multi-view image generation
2) 0.06s for flexicube reconstruction
3) 0.30s for mesh extraction
10 GB GPU