[논문 Summary] LayoutVLM (24.12 arxiv) "LayoutVLM: Differentiable Optimization of 3D Layout via Vision-Language Models"
[논문 Summary] LayoutVLM (24.12 arxiv) "LayoutVLM: Differentiable Optimization of 3D Layout via Vision-Language Models"
논문 정보 (Citation, 저자, 링크)
Citation : 2025.01.19 일요일 기준 4회
저자 (소속) : ( Fan-Yun Sun, Weiyu Liu, Siyi Gu, Dylan Lim, Goutam Bhat, Federico Tombari, Manling Li, Nick Haber, Jiajun Wu ) [Standford, Google]
논문 & Github 링크 : [ Official ] [ Arxiv ] [ 공식 Github ][ Project page ]
논문 Summary
0. 설명 시작 전 Overview
본 논문은 user prompt, 3D asset이 주어졌을 때 가장 물리적으로 납득할 수 있으며 의미론적으로도 합당한 배치를 위한 모델을 제안하고 있다.
다른 모델과 달리 최적화 과정을 거쳐야하지만, 다른 비교 모델 대비 우월한 정량적, 정성적 결과를 가져왔다.
실제로 project page에서는 우월한 결과를 보여줌
코드 기대 중
1. Introduction
Spatial reasoning(공간 추론)과 Planning(계획)은 물리적 세계의 제약 조건 내에서 3D 공간에서 객체를 이해, 배열, 조작하는 것을 포함.
전통적인 scene synthesis(장면 합성) 및 layout generation 방법은 사전 정의된 객체 카테고리와 배치 패턴 제한함.
최근 open universe layout generation 연구 내 LLM을 활용한 방법들을 소개함.
그러나 physical plausibility & semantic coherence를 동시 달성 어려움
e.g.
LayoutGPT: 숫자 기반 객체 위치 예측에서 객체 간 충돌과 경계 외부 배치 문제 발생.
Holodeck: 객체 간 공간적 관계 예측 및 제약 최적화 시도를 통한 physical plausibility를 향상시켰음에도 불구하고, 많은 객체가 있는 장면에서 실행 가능한 솔루션 부족.
LayoutVLM: open universe layout generation 방법, physical plausibility과 semantic alignment 달성
초기화: 최적화 과정의 초기값으로 수치적 물체 배치 예측
최적화 목표:
물리적 목표: 물리적 타당성 보장
공간 관계: 레이아웃의 의미 보존
시각적 마킹: 정확한 물체 배치 허용
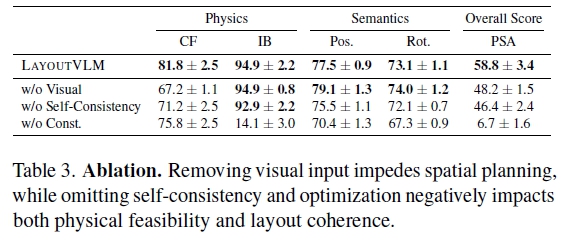
자기 일관성 디코딩 프로세스: 의미 있는 공간 관계 집중
Contribution
1) differentiable optimization을 통합한 새로운 scene layout representation(numerical pose estimates & spatial relations) 도입
2) VLM을 통한 시각적 마킹 기반 장면 표현 생성
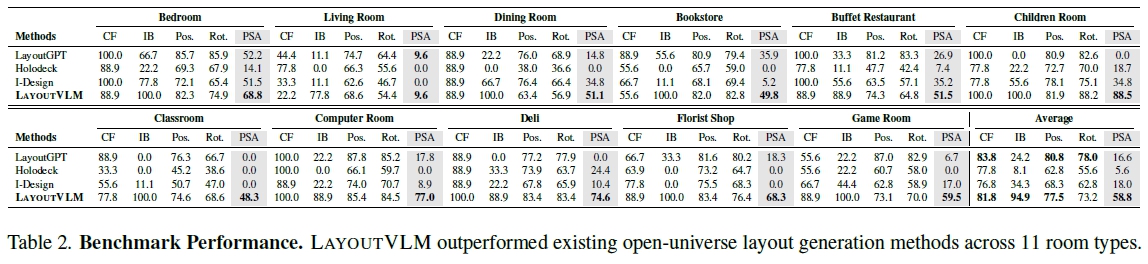
3) 11개 방 유형에 대한 평가를 통한 성능 개선
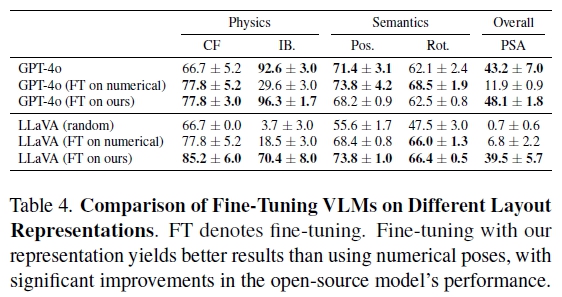
4) 합성 데이터로 오픈 소스 모델 fine-tuning을 통한 성능 향상
2. Related work
레이아웃 생성 및 실내 장면 합성 (Layout Generation & Indoor Scene Synthesis):
- 이미지 생성 모델 사용: Neural Radiance Fields (NeRFs)나 Gaussian splats와 같은 모델을 사용하여 장면을 생성하지만, 이 방식은 개별적으로 조작 가능한 객체나 표면을 제공하지 않아 로봇 응용에 적합하지 않습니다.
- 중간 표현 사용: 장면 그래프나 장면 레이아웃과 같은 중간 표현과 자산 저장소를 결합하여 장면을 생성하는 방법. 이러한 접근 방식은 대규모 다중모달 모델 (LMMs)을 이용한 오픈 보카바리 3D 장면 합성을 지원합니다.
LayoutGPT, Holodeck, Lay-A-Scene, AnyHome, InstructScene
비전-언어 모델을 이용한 3D 추론 (Vision-Language Models for 3D Reasoning):
최근 연구들은 비전-언어 모델(VLM)의 공간 추론 능력을 탐구하고 있습니다. 몇몇 연구는 포인트 클라우드나 메시와 같은 표현을 가진 3D 비주얼 인코더를 훈련하여 3D 장면 이해, 질문 응답, 내비게이션 및 계획 등의 작업 개선.
그러나 기존 연구들은 주로 인식 과제에 중점을 두고 있으며 3D 구조 생성을 위한 연구는 부족.
이 논문의 연구는 2D VLM을 사용하여 3D 레이아웃 생성을 목표로 하며, 원래의 공간 계획을 위한 기술을 활용.
이 모든 내용을 통해, LAYOUTVLM은 기존의 방법들이 해결하지 못했던 물리적 타당성과 의미적 정합성을 동시에 이루는 혁신적인 접근 방식을 제안.
3D-LLM, Chat-Scene, SpatialVLM, GPT-4o
3. Problem Formulation
3D layout generation 문제 정의 : 자연어 지침에 따라 3D 환경 내에서 자산을 배치하는 것
목표: 주어진 텍스트 설명을 충실히 표현하는 3D 장면을 생성하는 것
가정 :
레이아웃 기준 ($ \ell_{layout} $) : 4개의 벽과 N개의 3D mesh로 구성
입력된 3D 객체들이 똑바로 세워져 있음
Vision-Language Model (VLM)(e.g. GPT-4o)를 사용해 객체의 front-facing orientation(전면 방향) 판단
+ 각 객체의 짧은 텍스트 설명($ s_i $) 제공.
+ x축으로 회전한 후 bbox 차원 구하기 $ b_i \in R^3 $ (각 객체의 크기와 관련된 벡터, 세 개의 차원(x, y, z))
출력: 각 객체의 pose($ p_i = (x_i, y_i, z_i, \theta_i) $) 결정
4. LayoutVLM
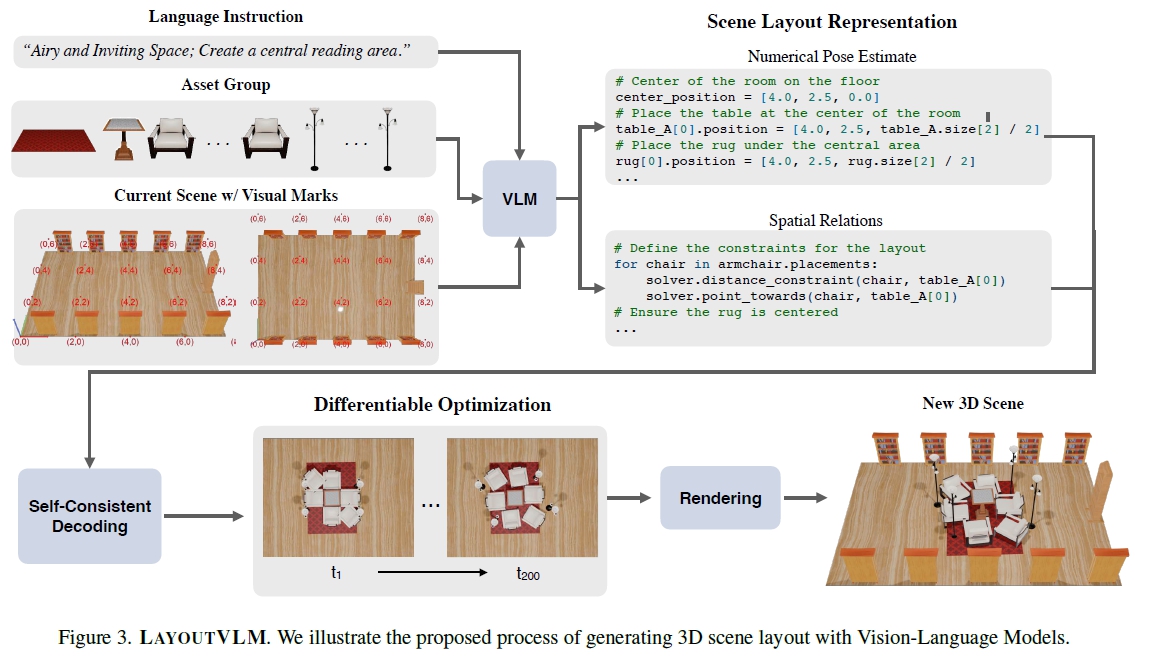
LayoutVLM : unlabel 3D 자산의 physically plausible arrangement 가능한 방법

$L_{\text{semantic}}$: Scene Layout Generation에서 파생된 objective function
$L_{\text{physics}}$: physical plausiblility를 보장하기 위해 물체 간의 물리적 관계를 고려한 objective function
4.1 Scene Layout Representation
유의미론적이며 납득할수 있는 물리적 정확성 표현은 두 가지 주요 요소를 포함
(a) numerical estimates of object poses ${\hat{p_i}^N_{i=1}}$
(b) spatial relations with differentiable objective
객체 초기 위치 추정치는 최적화를 위한 시작점을 제공하고 초기 layout이 최적화 과정에서 key 역할.
공간적 관계는 레이아웃의 의미를 보존하도록 조정되는 과정에서 필수적
Differentiable Spatial Relations
목표:
(a) 입력 언어 지시의 의미를 포착하는 것
(b) 최적화 과정에서 물리적 실행 가능성을 유지하는 것
예시:
"식탁을 세팅하라"는 지시의 경우, 비전-언어 모델(VLM)은 초기적으로 의자와 테이블이 겹치는 자세를 생성.
특정 공간 관계는 최적화 과정에서 overlap을 방지하고, 의자가 식탁 근처에 위치해야 한다는 필수적인 의미를 유지하도록 조정.
공간 관계의 5가지 유형:

positional objectives
Distance: 객체 간의 거리가 특정 범위 내에 있어야 함
On top of: 하나의 객체를 다른 객체 위에 배치
Orientational objectives:
Align with: 두 객체를 지정된 각도로 정렬
Point towards: 한 객체가 다른 객체를 바라보도록 정렬
wall related objective:
Against wall: 객체를 벽에 맞춰 배치
특징:
공간 관계는 고정된 기준 프레임에 의존하지 않으며, 각 공간 관계는 가변적인 매개변수를 가짐
예를 들어, 거리 목표는 객체 간 거리가 특정 범위를 벗어나면 높은 손실을 부여
4.2. Generating Scene Layout Representation with Vision-Language Models
Visual Prompting
기존 연구를 통해 시각적 단서가 VLM의 object recognition과 saptial reasoning을 향상한다는 근거를 기반한 입력 제공
1) 3D scene의 렌더링된 이미지
2) 개별 asset view
이때, 2가지의 visual annotation input 같이 제공
1) 3D 공간에서 2m 간격으로 배치된 좌표 포인트 : VLM이 차원과 scale을 이해하고 일관된 공간 참조 유지에 도움
2) 객체별 방향성 화살표를 포함한 정면 방향 annotate : 회전 제약 조건 생성에 필수
자산 배치 및 그룹화 실질적 사용 (컨텍스트 길이 제한 문제 해결을 위한 사용)
1) LLM 사용하여 각 asset별 텍스트 설명에 따른 그룹화
2) 그룹별 자산을 하나씩 배치
- 그룹 생성 전, VLM의 비어있는 곳을 파악하기 위해 3D 장면을 다시 재렌더링.
예시)
user text instruct : "거실에 소파와 커피 테이블을 배치하고, 벽난로 옆에 책장을 두세요"
asset 선택 : 시스템은 다양한 3D 자산 데이터베이스에서 조회하여 소파, 커피 테이블, 벽난로, 책장 등 관련 자산을 찾습니다.
그룹 생성: 지침에 따라, 시스템은 이 자산들을 그룹으로 묶습니다. 예를 들어, "소파와 커피 테이블"을 하나의 그룹으로 묶고, "벽난로와 책장"을 또 다른 그룹으로 묶을 수 있습니다.
LLM(대형 언어 모델) 사용: 그룹을 생성하는 과정에서 LLM이 각 자산의 텍스트 설명을 기반으로 자산들을 분류합니다. 예를 들어, 소파와 커피 테이블은 '거실 가구' 그룹에, 벽난로와 책장은 '장식/저장' 그룹에 포함될 수 있습니다.
자산 배치: 시스템은 각 그룹을 하나씩 배치합니다. 먼저 "소파와 커피 테이블" 그룹을 설정하고, 이후 "벽난로와 책장" 그룹을 배치합니다. 또한, 소파가 벽에서 적당한 거리를 두고 배치되도록 하고, 커피 테이블은 소파 앞에 올바른 간격으로 위치합니다.
장면 다시 렌더링: 각 그룹을 배치한 후, VLM은 3D 장면을 다시 렌더링하여 현재 배치 상태를 평가합니다. 어떤 자산이 중복되거나 잘못 배치된 경우, 유효한 공간을 식별하여 나머지 자산을 적절하게 배치할 수 있도록 지원합니다
Self-Consistent Decoding
VLM은 공간 계획에서 어려움. 특히, 전체 레이아웃의 일관성을 고려하는 데 실패하는 경향이 있음.
자기 일관된 공간 관계(Self-consistent spatial relation)는 최적화 동안 더 나은 물리적 납득을 위하기 위해 보존해야 할 필수 의미를 나타냄.
Self-consistent decoding을 통해 최적화 손실의 의미론적 부분을 공식적으로 설명.
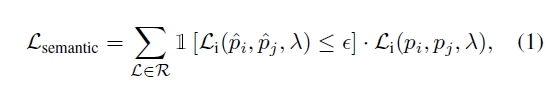
여기서 $ \hat{p}_i $와 $ \hat{p}_j $는 초기 추정된 포즈, $ \lambda $는 함수의 추가 매개변수, $ \epsilon $는 초기 추정에서 차별화 가능한 공간 관계 $ L $이 만족되는지 결정하는 임계값.
개인 요약 : 각 객체간 공간적 semantic 관계성을 고려한 loss를 최적화하는 방향으로 user prompt와 실제 배치의 유의미성을 갖추기 위한 단계라고 이해하면 쉬울 듯. 일종의 clip similarity
4.3. Differentiable Optimization
물건들의 3D oriented bounding box를 활용한 Distance-IoU loss를 통해 최적화
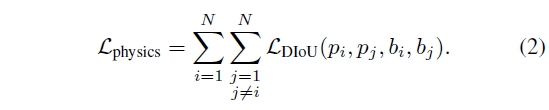
projected gradient descent (PGD) 사용
이를 통해 boundary에 대한 제약을 주어 교차가 없도록 함.
4.4. Finetuning VLMs with Scene Datasets
물리적으로 유효하고 의미론적으로 의미 있는 다양한 3D 레이아웃을 모델링 방안 제시
VLM Fine-tuning을 통해 특정 레이아웃 유형을 생성하도록 신속하게 적응.
이 과정은 특정 유형의 레이아웃을 보다 효과적으로 생성하기 위해 VLM을 조정하는 것으로, 미리 수집된 장면 데이터셋에서 추출한 정보를 사용하여 VLM의 성능을 향상시키고 해당 표현에 대한 이해도를 높입니다. 이는 4.2와 4.3을 통한 최적화 이후 진행하는 단계로 파악됨.
3D-Front dataset의 9000개 방에 대한 훈련 데이터를 추출 & 사용.
자동으로 추출한 장면 표현을 활용하여, 객체의 텍스트 설명 및 방향성 경계 상자를 생성하고 이를 VLM의 훈련 데이터로 사용
레이아웃 생성 작업을 위해 두 개의 VLM(GPT-4o 및 LLaVA-NeXT-Interleave)을 Fine-tuning
5. Experiments