PR-206 "PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud" Review (2019 CVPR)(3D Object Detection)
PR-206 "PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud" Review (2019 CVPR)(3D Object Detection)
1. Citations & Abstract 읽기
Citations : 2022.05.02 기준 937회
저자
Shaoshuai Shi, Xiaogang Wang, Hongsheng Li - The Chinese University of Hong Kong
Abstract

2. 발표 정리
공식 논문 링크
Arxiv
https://arxiv.org/abs/1812.04244
PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
In this paper, we propose PointRCNN for 3D object detection from raw point cloud. The whole framework is composed of two stages: stage-1 for the bottom-up 3D proposal generation and stage-2 for refining proposals in the canonical coordinates to obtain the
arxiv.org
Presentation Slide
https://drive.google.com/file/d/1FDqJRsk8Ie8PGF4iWo6IlV3RM5v4MSrL/view
PR206_PointRCNN.pdf
drive.google.com
Contents
Related Work & Information

카메라 없이 point cloud를 통한 3D object detection을 가능하게 한 논문
자율주행자동차를 위한 3D 인식
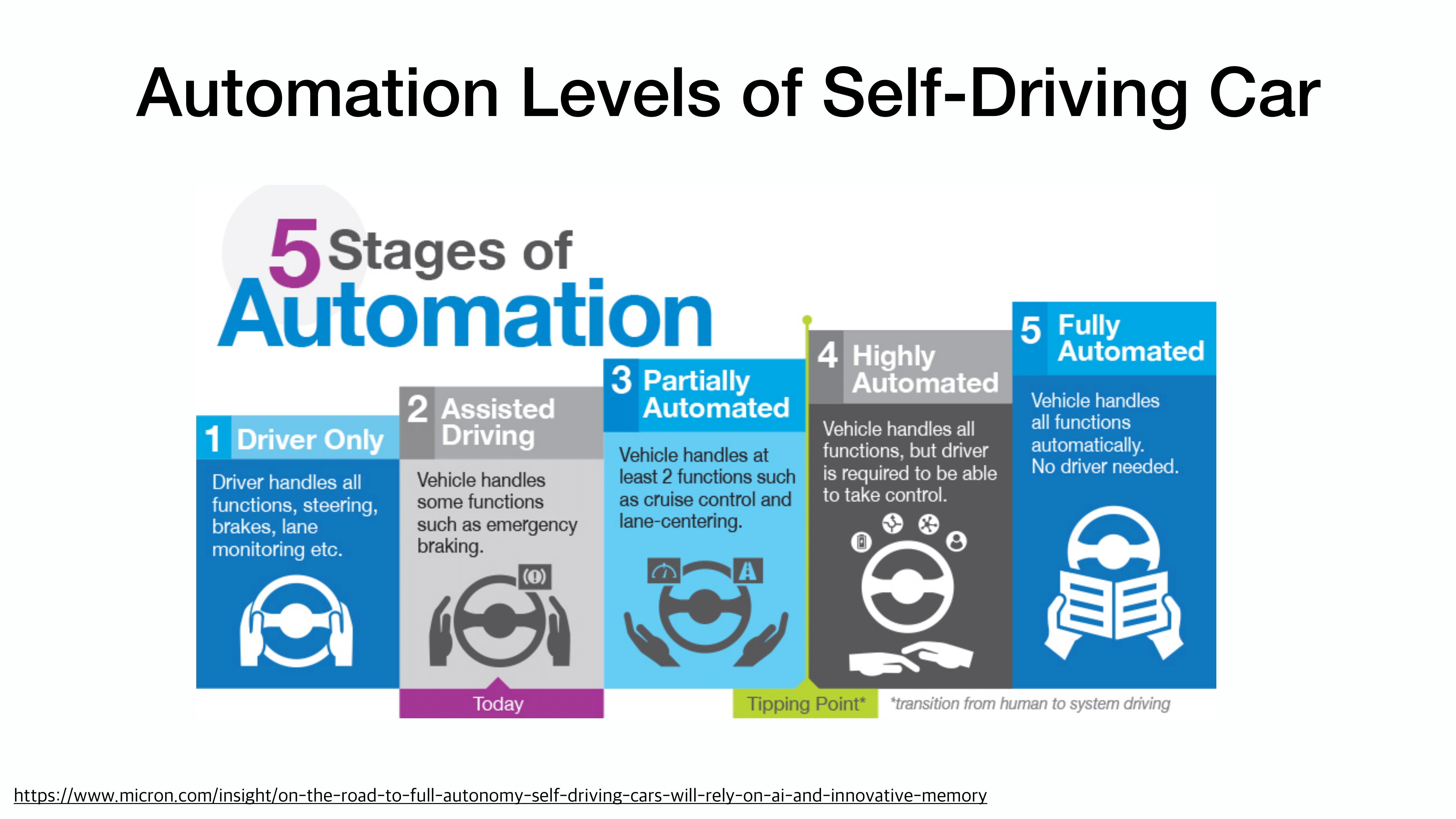
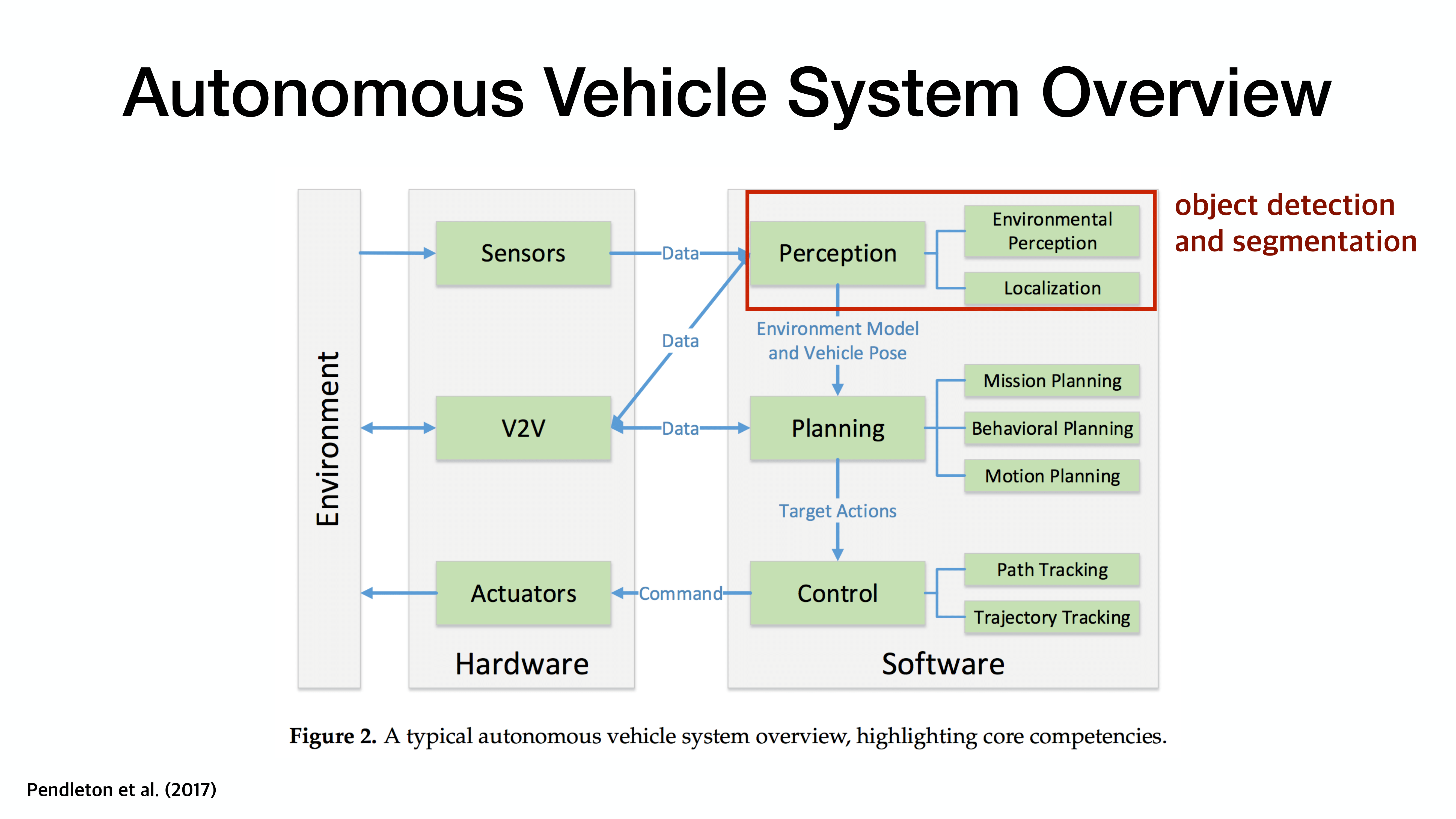
여러 sensor들을 기반으로 인지(perception)를 진행하고 이에 따른 물체 탐색을 진행함.
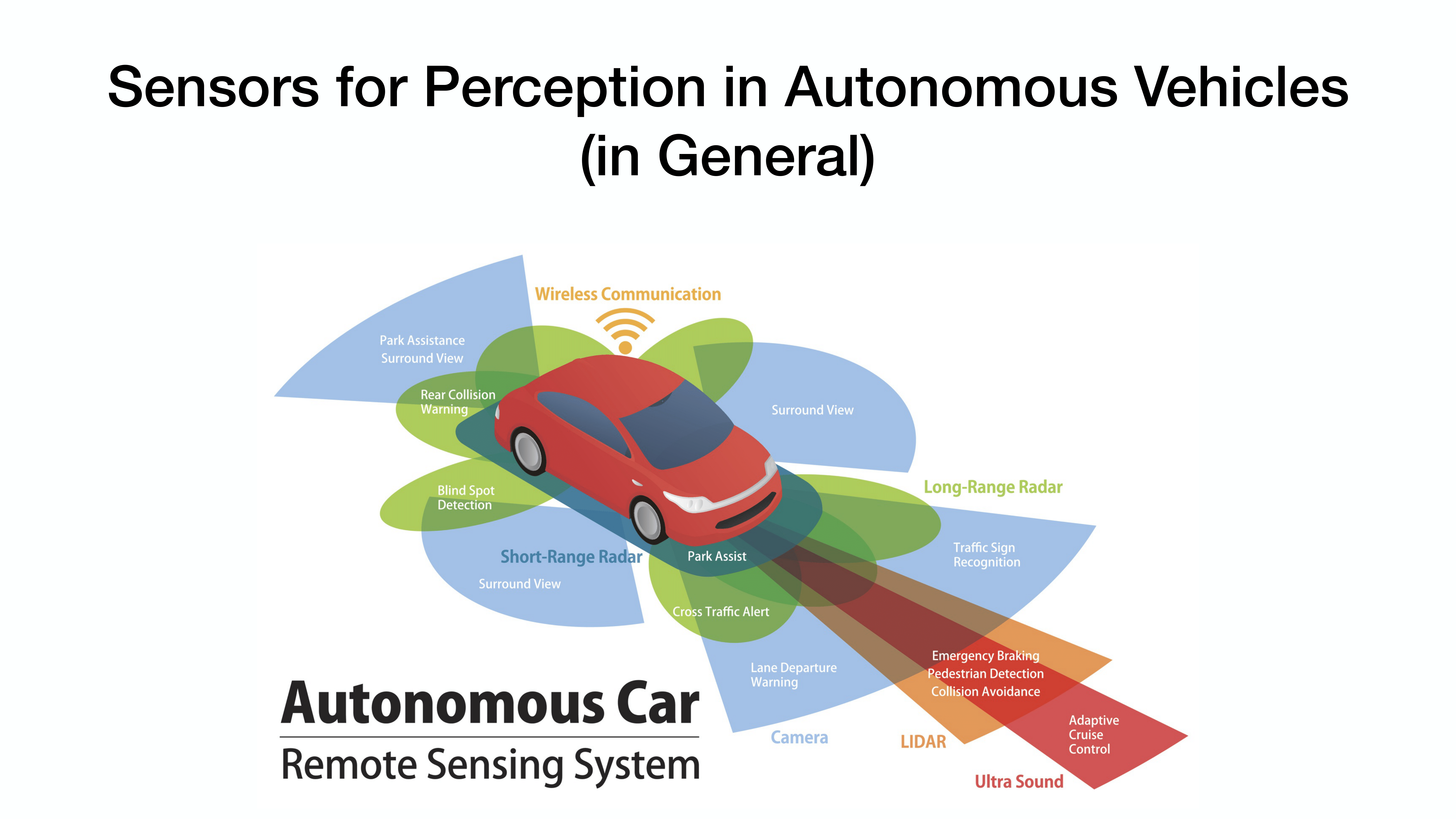
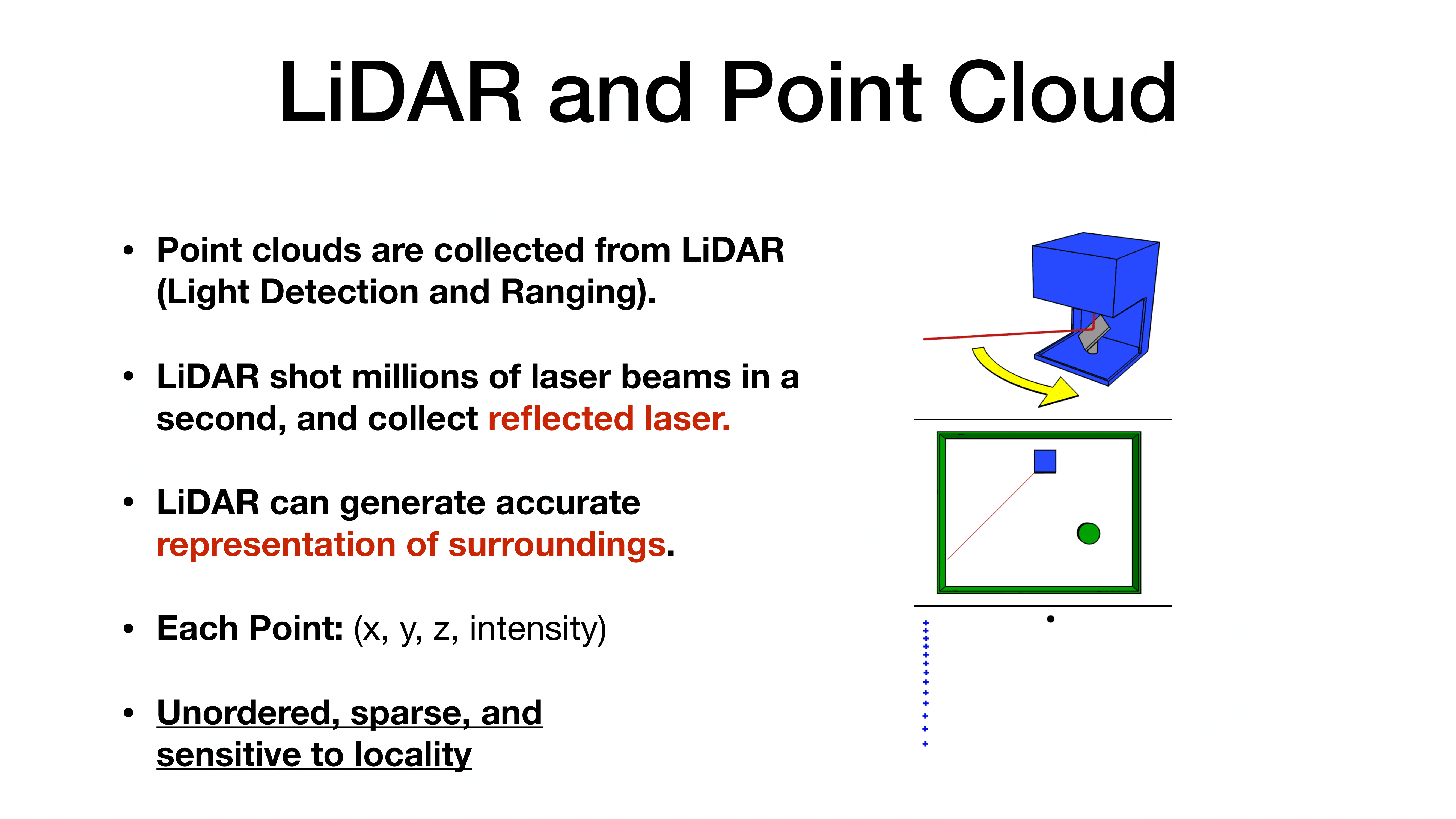
LiDAR를 통해 수집된 point cloud를 활용.
데이터의 순서가 존재하지 않고, 공간적으로 희소(Unordered, sparse)

RGB는 밀집되나 point cloud는 sparse한 환경에서도 특징을 뽑고 작업 수행이 가능.

3D object detection은 localization만 진행하는 2D와 달리 orientation까지 고려해야함.
3차원의 box
예측 output의 수가 많아짐.
3D object detection이 어려운 이유
1) Point cloud는 irregular data 형태
2) 6 degree-of-freedom의 큰 탐색 공간
3) point cloud의 sparse representation
PR-012 Faster R-CNN와 유사

3차원이 다루기 힘들기 때문에 Bird-Eye 즉, 위쪽에서 관찰된 것을 기반으로 object detection으로 진행
3D -> 2D

이미지에서 bounding box를 추정한 후 이에 대한 3D box를 추정하는 방법.
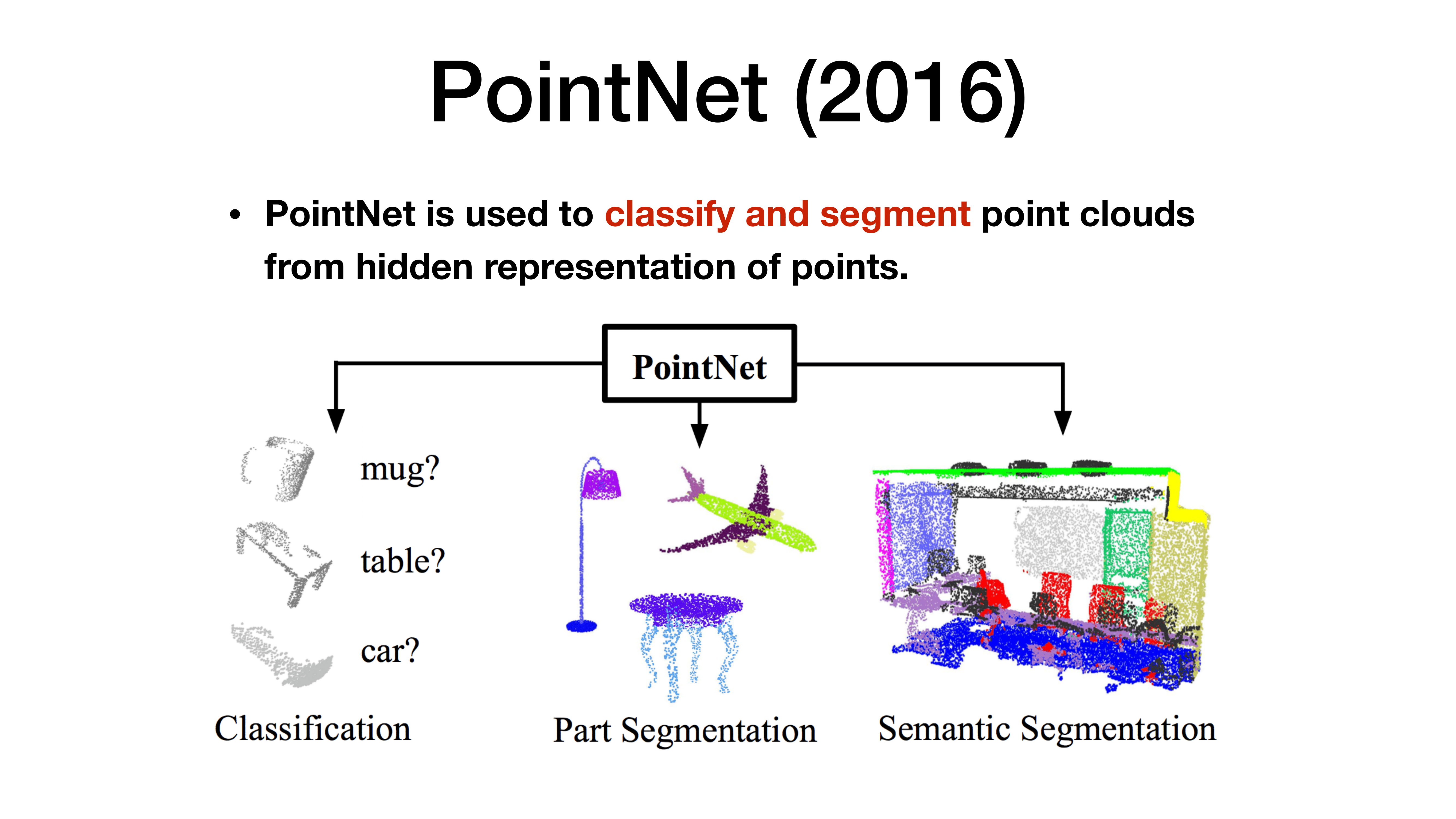
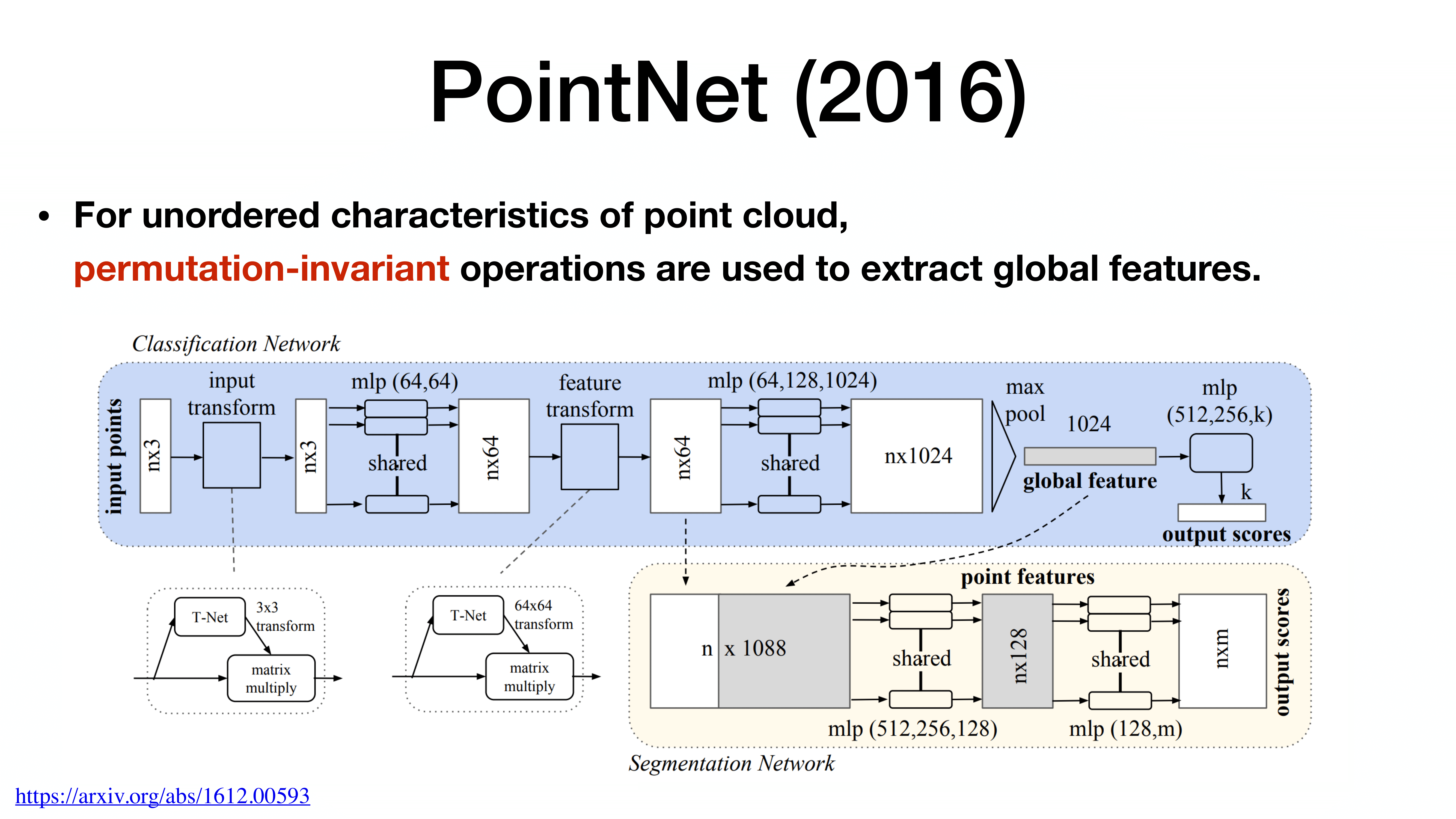
Point cloud는 sparse하고 unordered되기 때문에 2D처럼 사용하기 힘들다. 이에 따라 위와 같은 구조를 가질 수 밖에 없다.
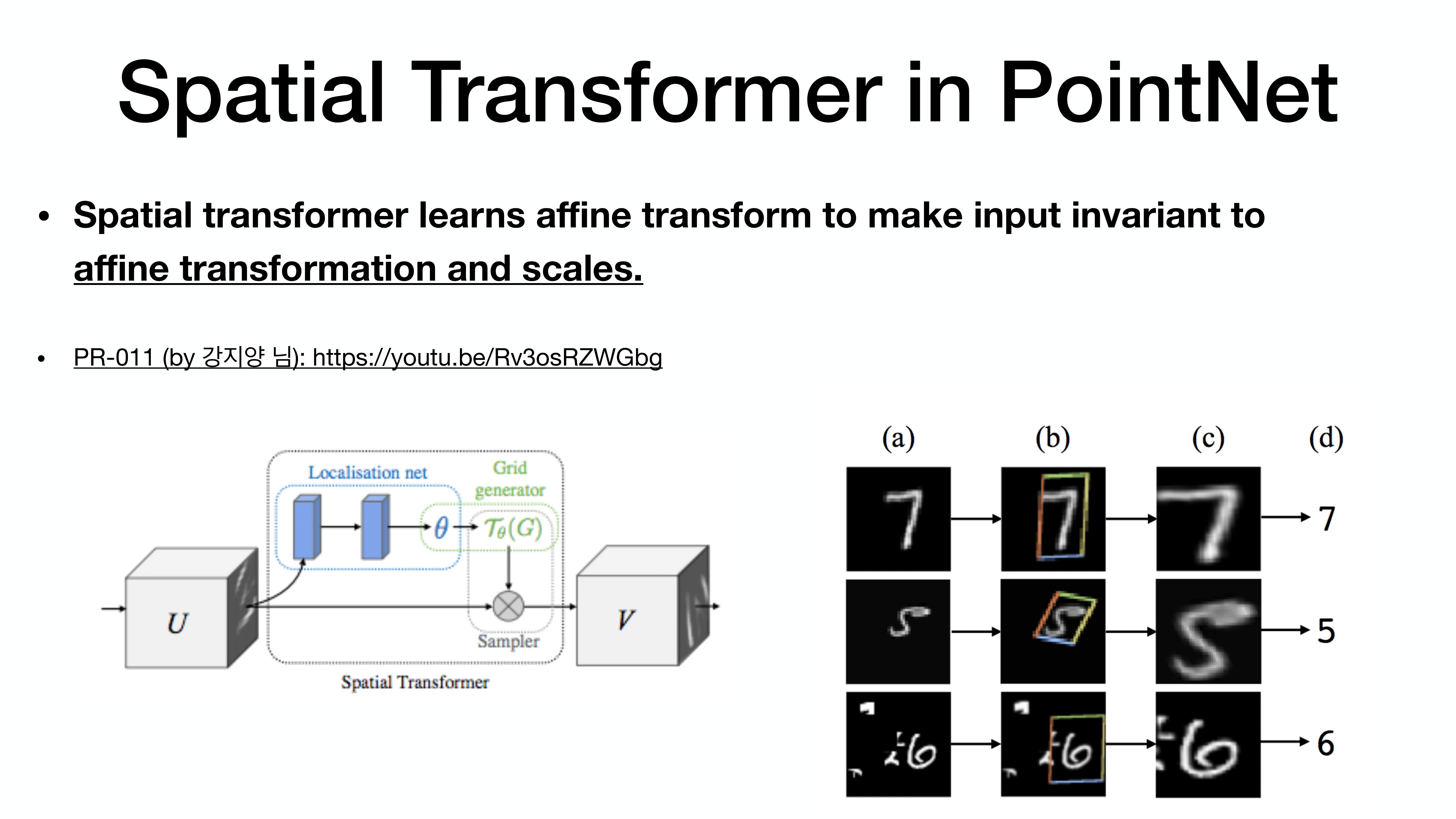
spatial transformer
PR-011 혹은 Pytorch Tutorial 참조
https://pytorch.org/tutorials/intermediate/spatial_transformer_tutorial.html
Spatial Transformer Networks Tutorial — PyTorch Tutorials 1.11.0+cu102 documentation
Note Click here to download the full example code Spatial Transformer Networks Tutorial Author: Ghassen HAMROUNI In this tutorial, you will learn how to augment your network using a visual attention mechanism called spatial transformer networks. You can re
pytorch.org
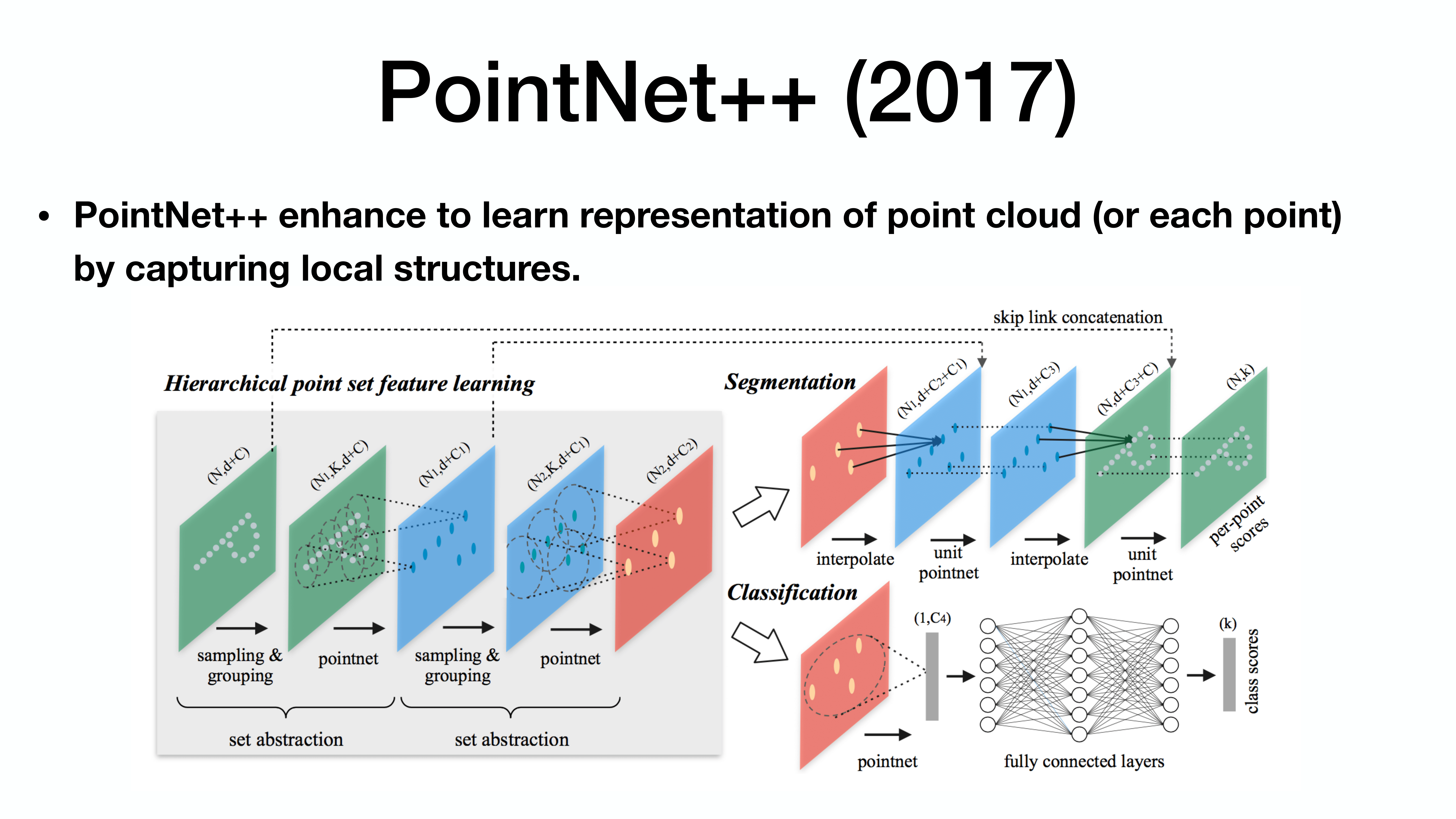
(grouping을 통한 maxpooling) 반복 + U-Net concat / Classification
PointRCNN
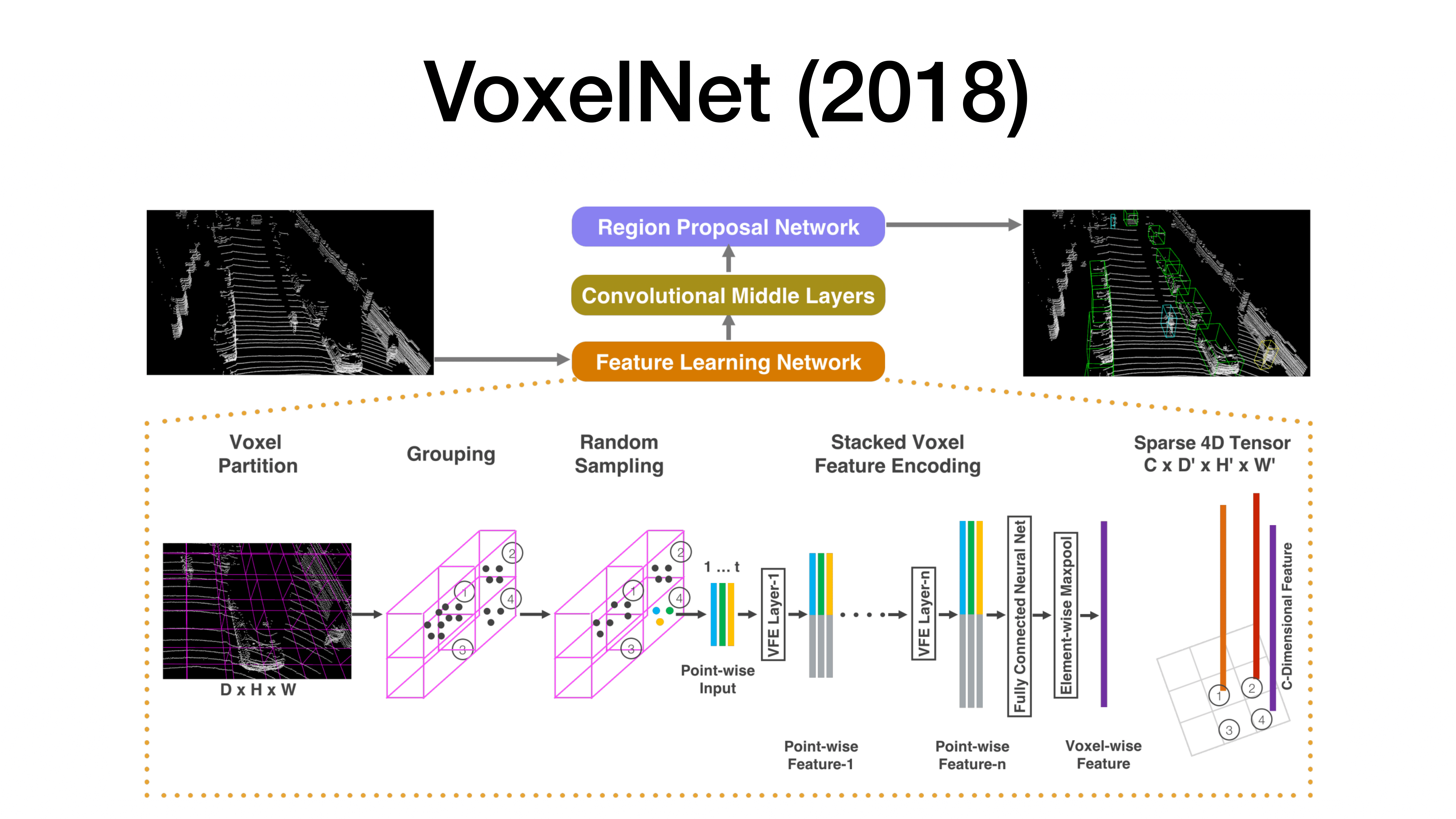
3D Object Detection의 가장 대표적인 방법은 VoxelNet으로 Point들에 대한 개수에 따라 3차원 공간의 Intensity를 구해 활용.
Voxel 혹은 Bird-Eye를 활용하는 것은 다루기는 쉽지만 기하학적 정보를 잃기 쉽다.
이런 방식의 전처리를 회피하고 바로 Point Cloud를 활용하는 방안을 고안하게 됨.
그것이 오늘 이야기할 PointRCNN


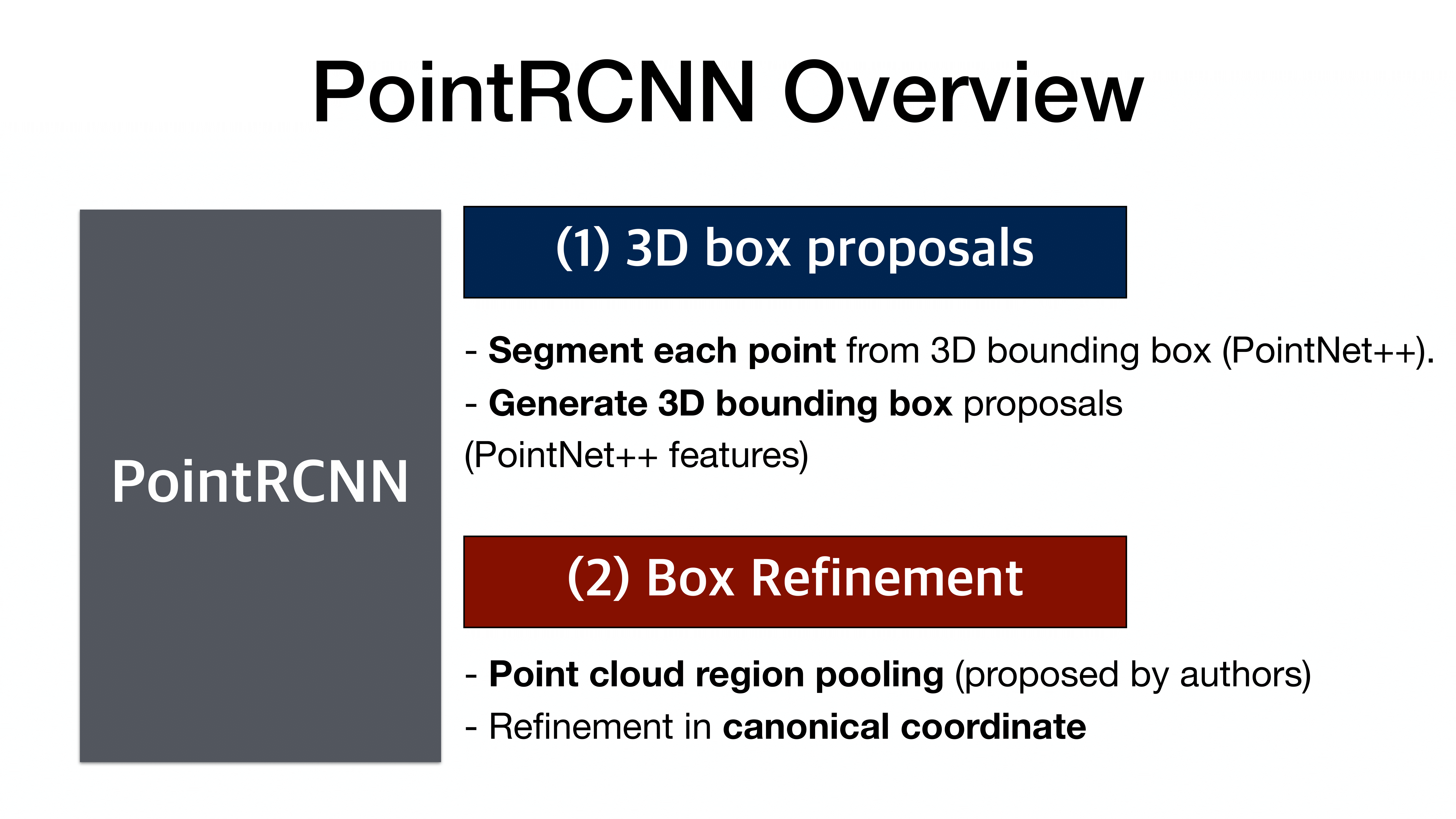
2 stage network
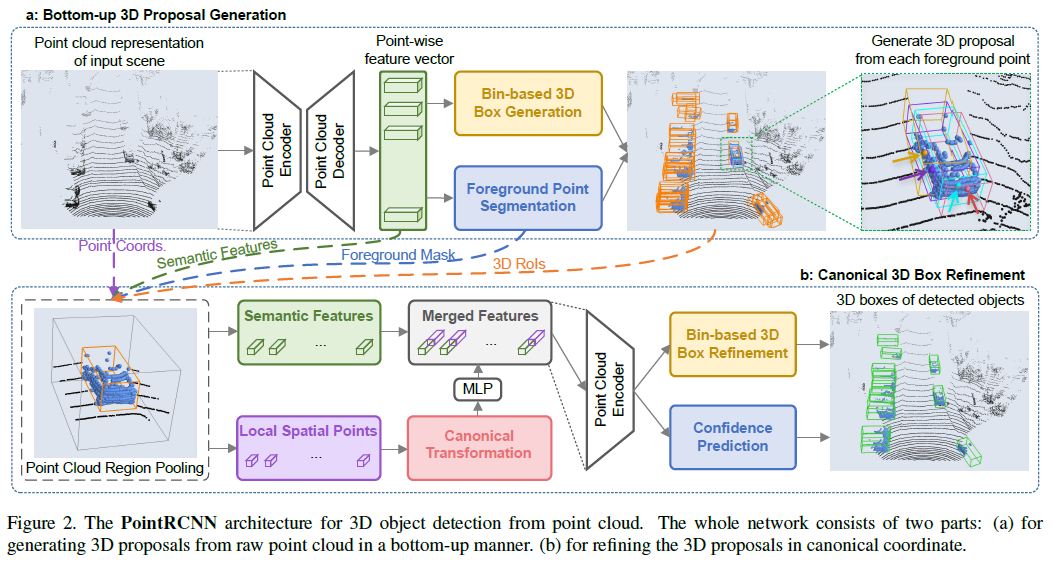
전반적인 구조
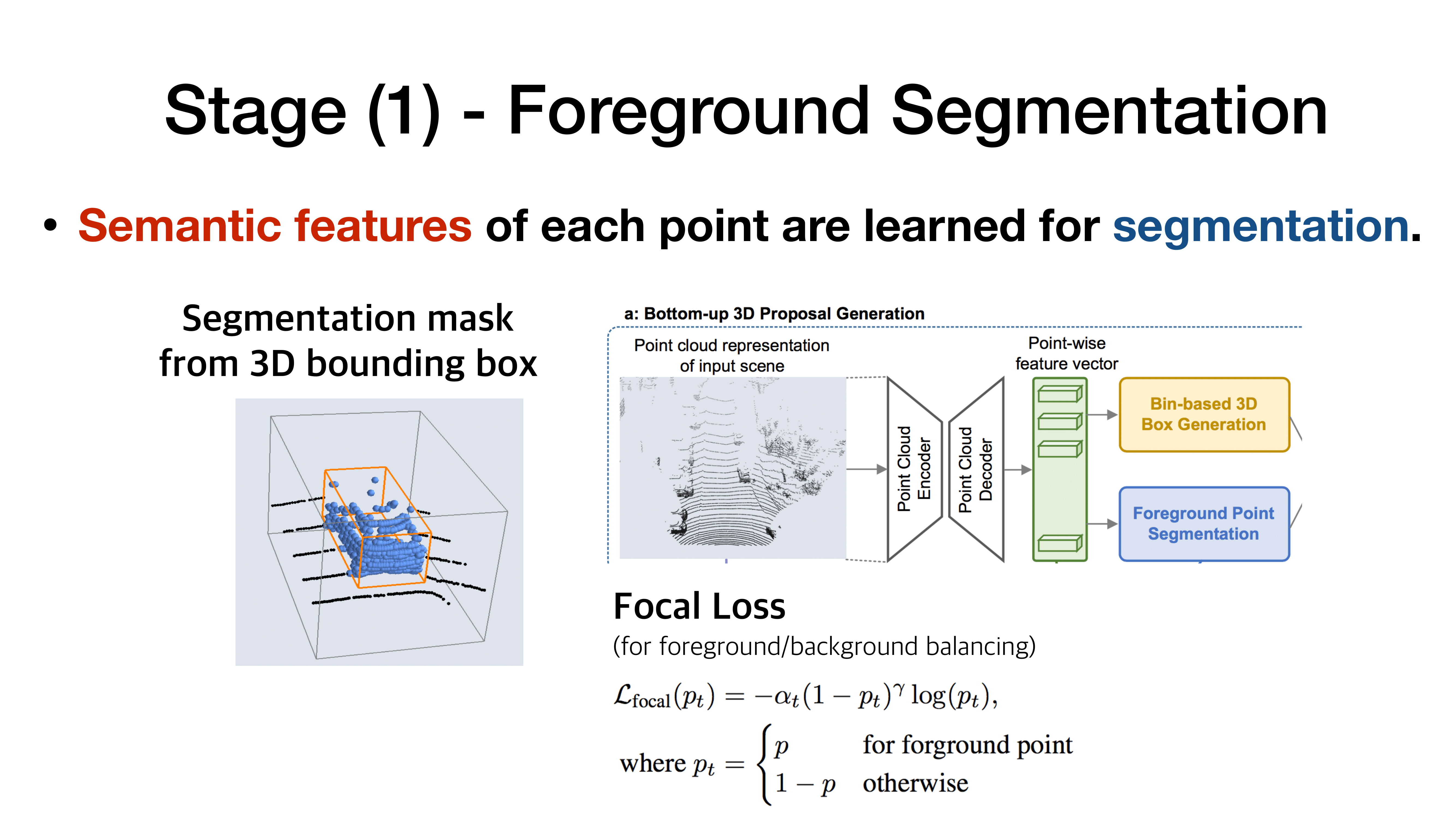
각 점마다 grouping -> FC
각 점마다의 feature vector를 활용하여 foreground/background인지를 분류
focal loss? (많이 사용)
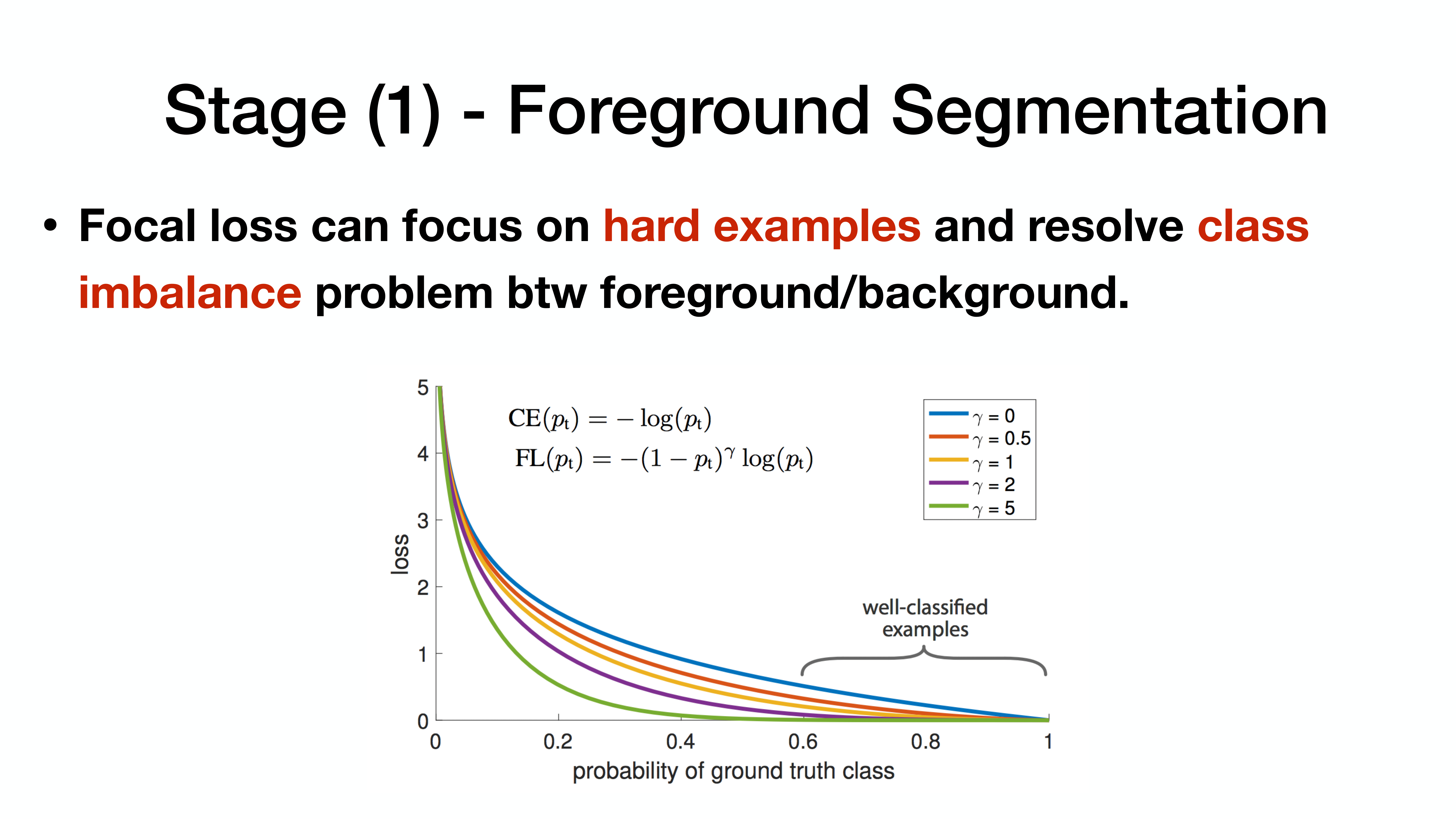
focal loss는 class imbalance 상황에서 cross entropy보다 더 좋은 성과를 보임.

XYZ에 대한 단순 regression이 아닌 Bin에 대한 위치 정보를 기반으로 classification 진행
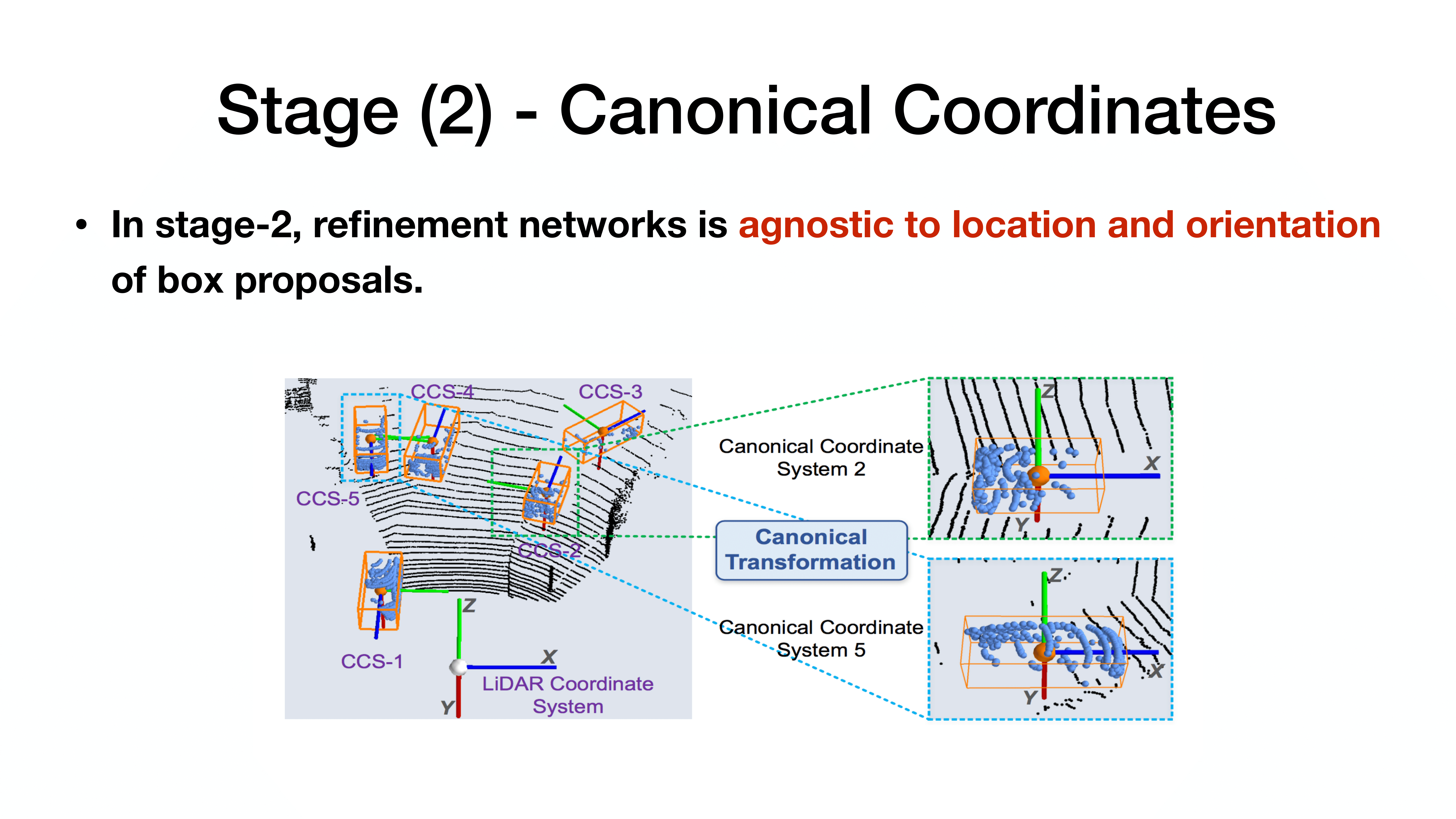
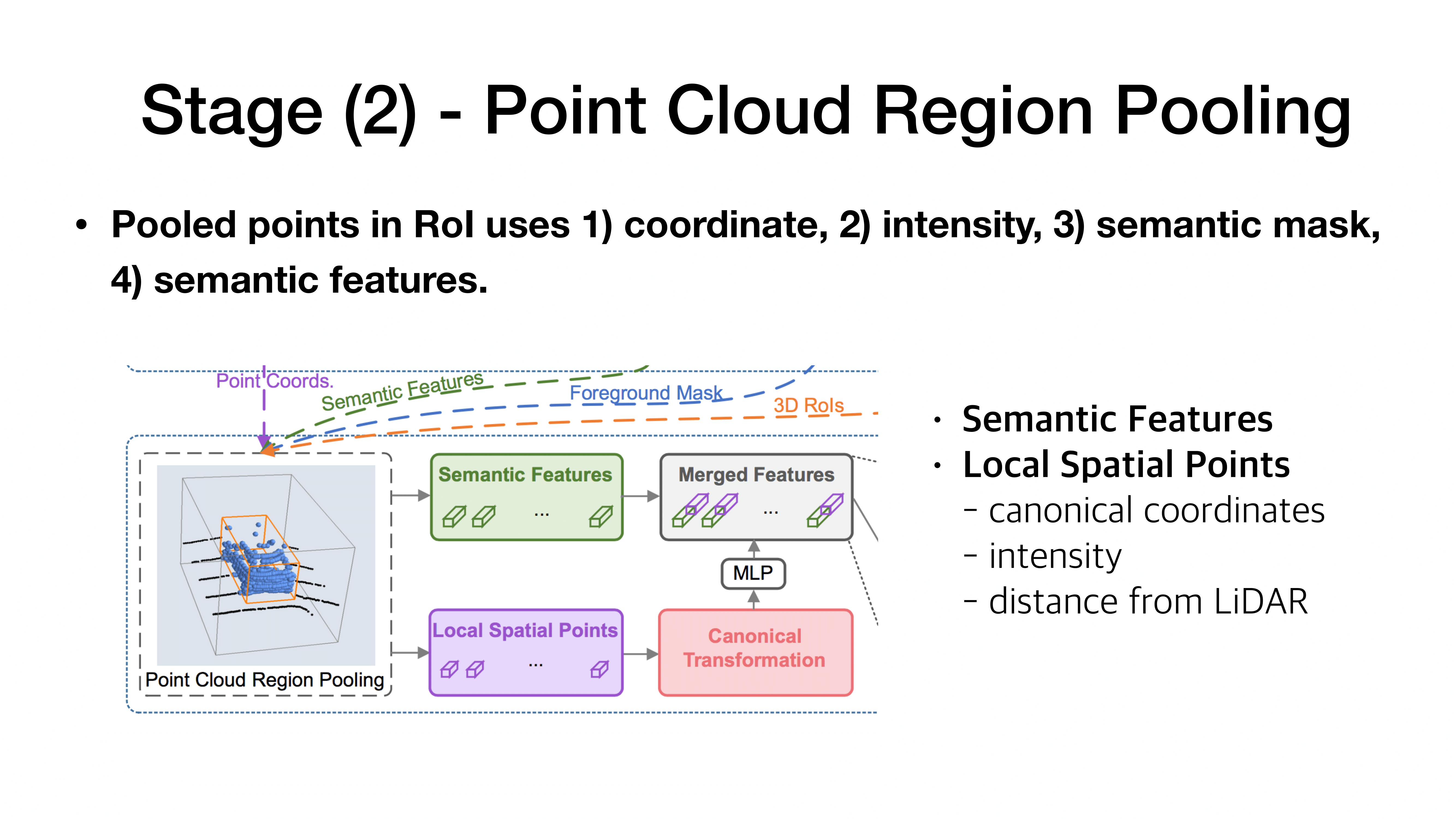
stage 2에서는 canonical coordinate를 기반으로 학습 진행.


Pedestrian에서는 성능이 조금 저하됨. object가 작아서? 사람이 LiDAR에서 detecting이 어려워서?
큰 object는 잘 작동하는 것을 확인할 수 있었음.
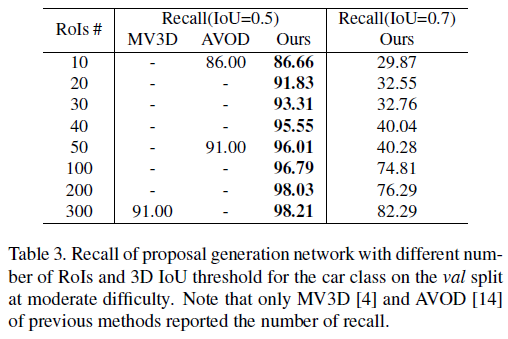
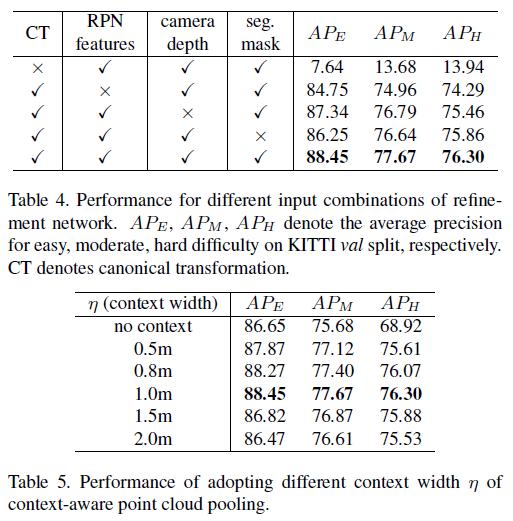
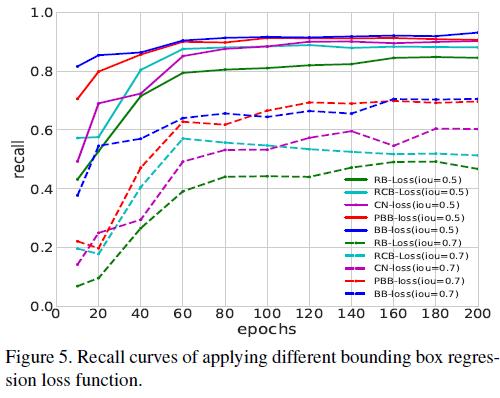
RB(Residual base)
BB(bin-based)
BB의 성능이 RB보다 더 낫다.

다수의 sensor에서 활용할 수 있는 부분도 고려해야함.
다양한 데이터 세트에 대한 적용이 가능한지 확인

class imbalance가 크게 문제될 것으로 보임. 이에 대한 고려 필수
참조
GitHub
https://github.com/sshaoshuai/PointRCNN
GitHub - sshaoshuai/PointRCNN: PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud, CVPR 2019.
PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud, CVPR 2019. - GitHub - sshaoshuai/PointRCNN: PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud, CVPR 2019.
github.com
