[논문 Summary] PointRCNN (2019 CVPR) "PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud"
[논문 Summary] PointRCNN (2019 CVPR) "PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud"
논문 정보
Citation : 2022.05.03 화요일 기준 937회
저자
Shaoshuai Shi, Xiaogang Wang, Hongsheng Li - The Chinese University of Hong Kong
논문 링크
Arxiv
https://arxiv.org/abs/1812.04244
PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
In this paper, we propose PointRCNN for 3D object detection from raw point cloud. The whole framework is composed of two stages: stage-1 for the bottom-up 3D proposal generation and stage-2 for refining proposals in the canonical coordinates to obtain the
arxiv.org
논문 Summary
Abstract

본 논문을 통해 날 것의 point cloud로부터 3D object detection을 할 수 있는 PointRCNN을 제안한다.
이를 위해서 2 단계를 거쳐야한다.
stage 1: bottom-up 3D proposal generation
stage 2: 최종 탐지 결과를 얻기 위해 canonical coordinate에서의 proposal을 정제(refine)
기존의 방법 : RGB image / bird view 또는 voxel로의 point cloud project에서 proposal을 생성
stage 1: point cloud로부터 고품질의 3D proposal을 소량 직접 생성한다.
stage 2: 보다 나은 local spatial feature를 학습하기 위해 각 proposal의 pooled point를 canonical coordinate로 변환한다. 이때 정확한 박스 정제와 신뢰도 예측을 위해 stage 1에서 학습한 각 point의 global semantic feature들과 결합한다. (이해를 위해 Figure 2 참조)
1. Introduction
2D 기반의 object detection은 많은 발전이 이뤄졌다. 그러나 point cloud를 이용한 3D object detection은 irregular data format / 3D 물체의 6 Degree-of-Freedom(DoF) 자유도의 큰 search space때문에 어려움을 겪는다.

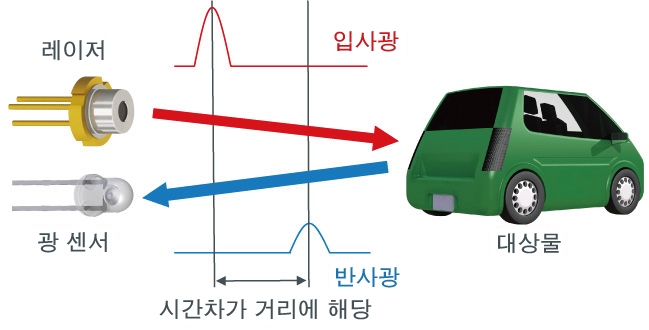
자율주행차에서 가장 많이 사용하는 3D sensor는 LiDAR로 3D point cloud를 통해 3D 구조물에 대해 포착한다. 이와 관련한 선행 연구는 AVOD와 Frustum-Pointnet이 있다.
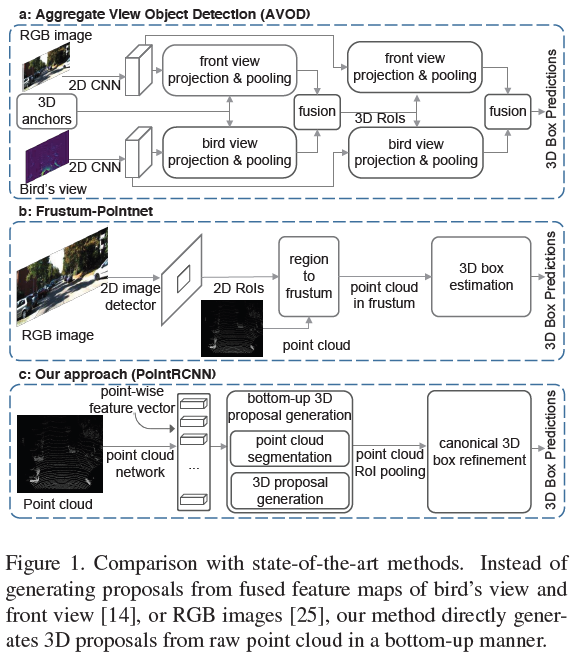
Figure 1 (a) AVOD와 (b) Frustum-Pointnet은 proposal을 생성한 후 feature를 통해 bird view, frontal view, voxel 등을 통한 projection으로 3D 추정시 point를 사용한다.
Top-down 방식 : RoI 생성 후 point 활용
Bottom-up 방식 : point로부터 RoI를 바로 생성
제안한 PointRCNN은 2 단계를 거침
stage 1에서는 3D bounding box proposal에 대한 생성을 목적으로 foreground point segmentation과 bounding box proposal을 생성한다.
stage 2에서는 canonical 3D box refinement를 수행한다.
Contribution
1) point cloud로 foregound 물체와 배경으로 분류하여 높은 품질의 3D proposal을 생성할 수 있게 하는 point cloud 기반 bottom-up 3D bounding box proposal generation algorithm을 제안한다.
2) 제안한 canonical 3D bounding box refinement는 1단계에서 생성된 높은 recall box proposal의 이점을 활용하고 강건한 bin-based loss로 canonical coordinate의 box coordinate refinement 예측을 학습함.
3) 2018.11월 기준 KITTI 3D detection 관련 SOTA보다 뛰어난 성과를 보임.
2. Related Work
AVOD(2018 IROS), Pointnet(2017 CVPR), Pointnet++(2017 NIPS), Frustum pointnets(2018 CVPR), Voxelnet(2017 CVPR)
PR-206 참조(Related Work를 아우르는 설명이 곁들여진 영상)
정리 : https://aigong.tistory.com/410
3. PointRCNN for Point Cloud 3D Detection
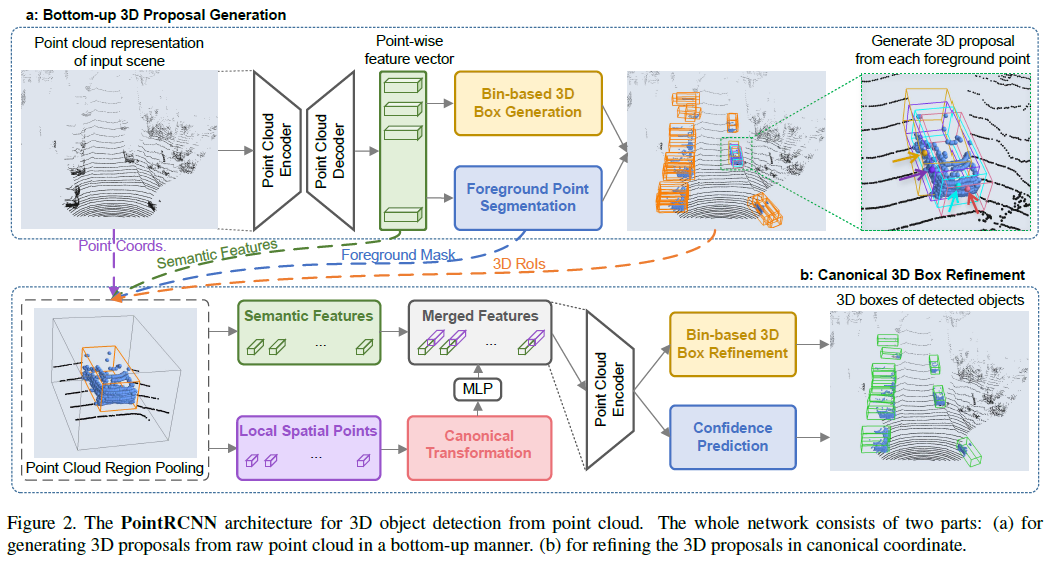
Figure 2에서 보이는 바와 같이 PointRCNN은 2 단계가 존재.
stage 1. Bottom-up 3D Proposal Generation
stage 2. Canonical 3D Box Refinement
3.1 Bottom-up 3D proposal generation via point cloud segmentation
stage 1은 multi-scale grouping을 포함하는 PointNet++을 backbone으로 활용한다.
Point Cloud Encoder와 Decoder를 통해 Point-wise feature vector를 뽑는다. 이후 이를 통해 Bin-based 3D Generation과 Foreground Point Segmentation을 진행한다.
Foreground point segmentation
foreground point들은 물체의 위치와 방향을 예측하는데 풍부한 정보를 제공한다.
foreground인지를 분류하는 것과 3D box proposal generation을 동시에 수행할 수 있게 디자인됨.
Foreground Point Segmentation은 foreground인지 background인지를 분류하는 문제로 background가 foreground에 비해 훨씬 많기 때문에 불균형이 일어나고 이 때문에 focal loss를 활용한다.

Bin-based 3D bounding box generation
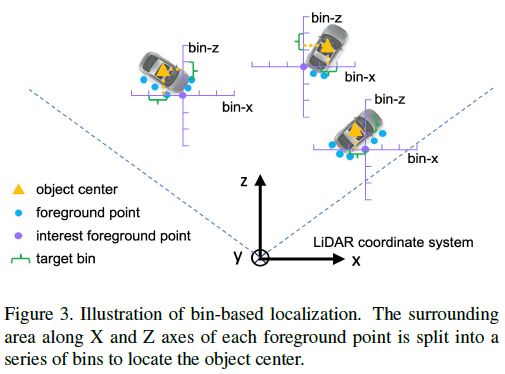
3D 물체의 bounding box를 추정하기 위해 bin-based regression loss를 도입.
Figure 3에서 나와있는 바와 같이 X와 Z축에 따라 bin을 분할
cross entropy loss를 포함하는 bin-based classification을 활용 (단순 L1 regression loss보다 더 정확하고 강인한 center localization이 가능)
localization loss : bin-based classification, residual regression
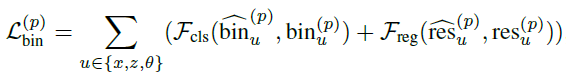
$x, z, \theta$에 대해 localization loss를 수행
수행에 있어 필요한 bin과 regression은 다음과 같은 식으로 구함.

orientation $\theta$는 $2\pi$를 n개의 bin으로 쪼개 bin 안의 residual을 regression함.
center location $y$와 object size $(h,w,l)$는 L1 loss를 활용함. 특히 object size는 전체 훈련 데이터 세트에 대한 각 클래스별 물체 사이즈의 평균과 관련한 residual을 계산하여 regression을 구함.

전체적인 bin-based regression loss는 eq 3과 같다.
$\mathcal{F}_{cls}$는 cross-entropy loss
$\mathcal{F}_{reg}$는 L1 loss
training 시 0.85 IoU threshold / NMS 300 proposal을 stage 2로 넘김
inference 시 0.8 IoU threshold / NMS 100 proposal을 stage 2로 넘김
3.2. Point cloud region pooling
3D bounding box proposal을 획득한 이후 생성된 box proposal을 기반으로 box location과 orientation을 refine하는 것을 목표로 한다.
3D point와 이에 상응하는 point feature들을 pool함.
h, w, l에 대해 $\eta$만큼의 상수 값을 확장하여 context information을 포함하도록 encode함.
1) 3D point coordinates $(x,y,z)$
2) laser reflection intensity $r$
3) predicted segmentation mask $m$ (Foreground Mask)
4) point feature representation $f$ (PointNet++를 통해 얻은 Semantic Feature)
3.3. Canonical 3D bounding box refinement
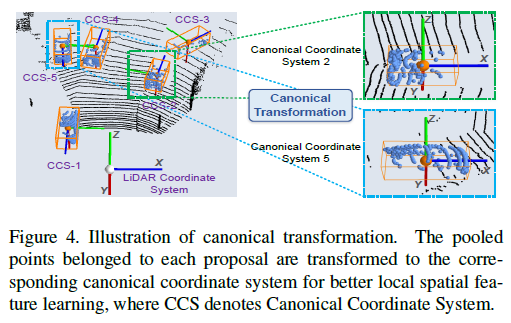
Canonical transformation
각 proposal에 속한 pooled point를 canonical coordinate system의 proposal로 변화시키는 것.
(1) box proposal의 중심은 원점에 위치한다.
(2) local $X^{\prime}, Z^{\prime}$은 ground plane에 평행하게 위치. $Z^{\prime}$은 $X^{\prime}$에 수직이 되도록 설정.
(3) $Y^{\prime}$는 LiDAR coordinate system과 동일하게 유지
canonical coordinate system을 사용하는 것은 box refinement stage에서 각 proposal의 local spatial feature를 더 잘 학습하도록 한다.
Feature learning for box proposal refinement
stage 1 Semantic Features : Global Semantic Features
stage 2 Local Semantic Features
canonical transformation을 통해 강건한 Local Semantic Feature learning이 가능하지만 depth 정보를 잃게 된다.
예) LiDAR에서 거리가 멀수록 point 수가 적은 것.
이를 보완하기 위해 sensor의 거리를 point의 feature마다 포함시킴.
$$d^{(p)} = \sqrt{ (x^{(p)})^2 + (y^{(p)})^2 + (z^{(p)})^2 }$$
local spatial feature, r, m ,d를 concat한 후 fully-connected layer를 통해 encode
local spatial feature와 global semantic feature를 concat
Losses for box proposal refinement
stage 2에서 3D bounding box refinement를 위한 loss와 관련 사항은 아래와 같다.
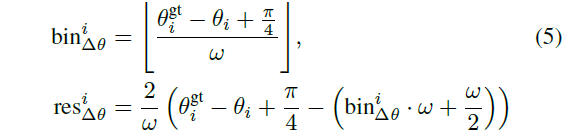

4. Experiments
3D object detection benchmark : KITTI dataset 활용
4.1. Implementation Details
중략
4.2 3D Object Detection on KITTI
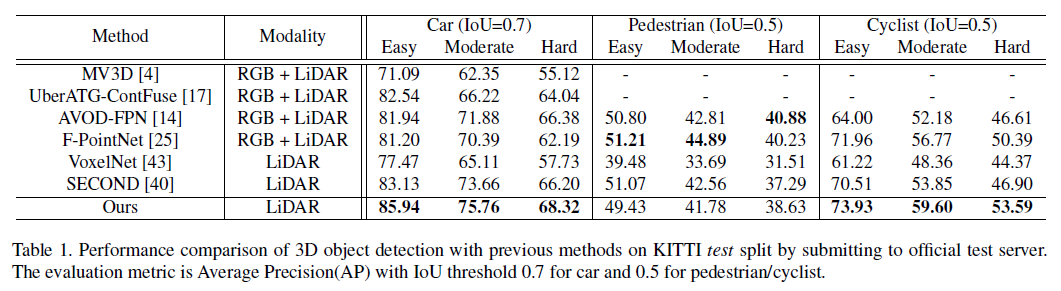
car, cyclist에 대해서는 우수한 성과를 보임.
그러나 pedestrian에 대해서는 살짝 나쁜 성과를 보임. 이는 아마 point cloud 자체가 sparse하다보니 작은 객체인 pedestiran에 대해 성과가 잘 나오지 않은 것으로 예상.
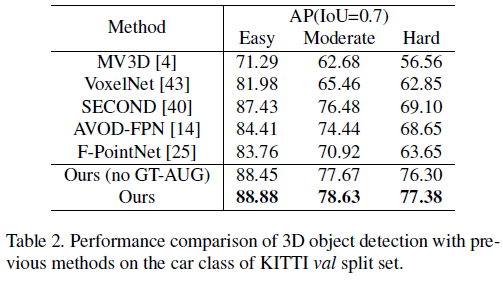
제안된 모델이 가장 좋은 AP 결과를 보임
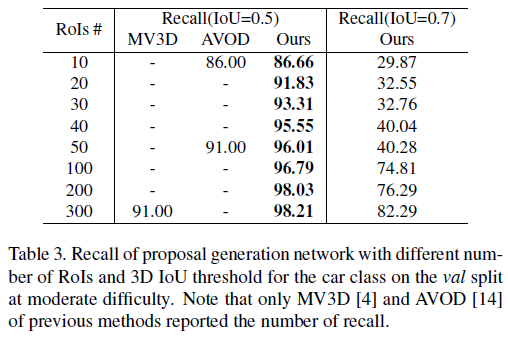
4.3 Ablation Study
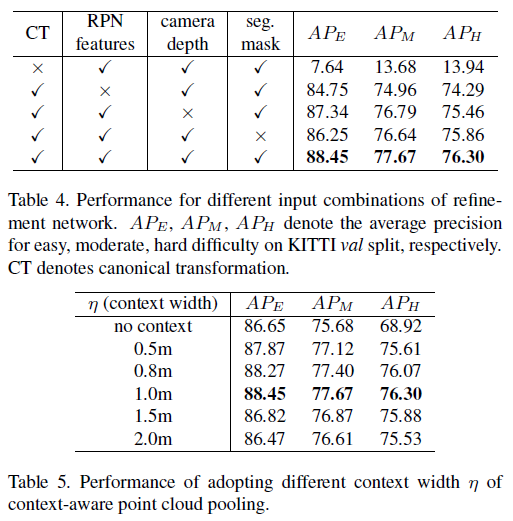
Table 4. ablation study 결과 모두 활용하는 것이 가장 좋은 성과를 얻음
Table 5. $\eta$ 크다고 좋은 것은 아니며 좋은 결과를 얻는 값이 존재 1m
Losses of 3D bounding box regression
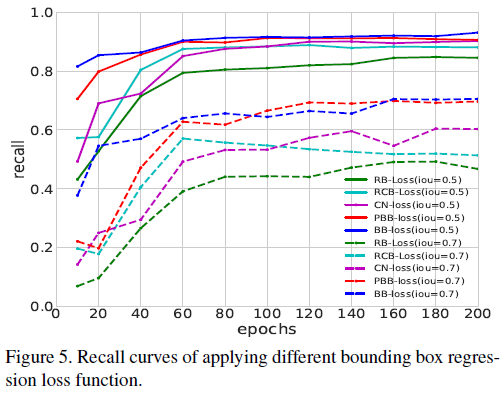
full bin-based loss (BB-loss)가 상대적 IoU 상태에서 모두 좋은 성과를 보임.

Reference
공식 Github
https://github.com/sshaoshuai/PointRCNN
GitHub - sshaoshuai/PointRCNN: PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud, CVPR 2019.
PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud, CVPR 2019. - GitHub - sshaoshuai/PointRCNN: PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud, CVPR 2019.
github.com
도움이 되는 YouTube 1. PR-206
블로그
https://velog.io/@intuition/PointRCNN
[Paper Review] PointRCNN: : 3D Object Proposal Generation and Detection from Point Cloud
두 번째로 다룰 3D object detection 논문은 CVPR 2019에 나왔던 PointRCNN입니다. 첫 번째로 다루었던 VoxelNet이 1-stage였던 것에 반해 PointRCNN은 대표적인 2-stage detector입니다.
velog.io
https://www.programmersought.net/article/342610152.html
[3D target detection] PointRCNN - ProgrammerSought
Code Papers 1. Thesis idea This paper proposes a two-stage 3D detection model PointRCNN. The model of the paper is divided into two stages. In the first stage, PointNet++ is used as a foreground segmentation model, and the foreground is segmented as a 3D p
www.programmersought.net
