[논문 Summary] SeeSR (CVPR 2024) "SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution"
[논문 Summary] SeeSR (CVPR 2024) "SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution"
논문 정보 (Citation, 저자, 링크)
Citation : 2024.06.23 일요일 기준 12회
저자 (소속) : ( Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, Lei Zhang ) [The Hong Kong Polytechnic University, OPPO Research Institute, ByteDance]
논문 & Github 링크 : [ Official ] [ Arxiv ] [ 공식 Github ]
논문 Summary
0. 설명 시작 전 Overview
T2I 모델 기반 Real-World Image Super-Resolution 방법을 진행함.
이때, semantic Prompt를 활용함으로써 더 좋은 성능을 얻어냄.
2단계에 걸쳐 진행됨
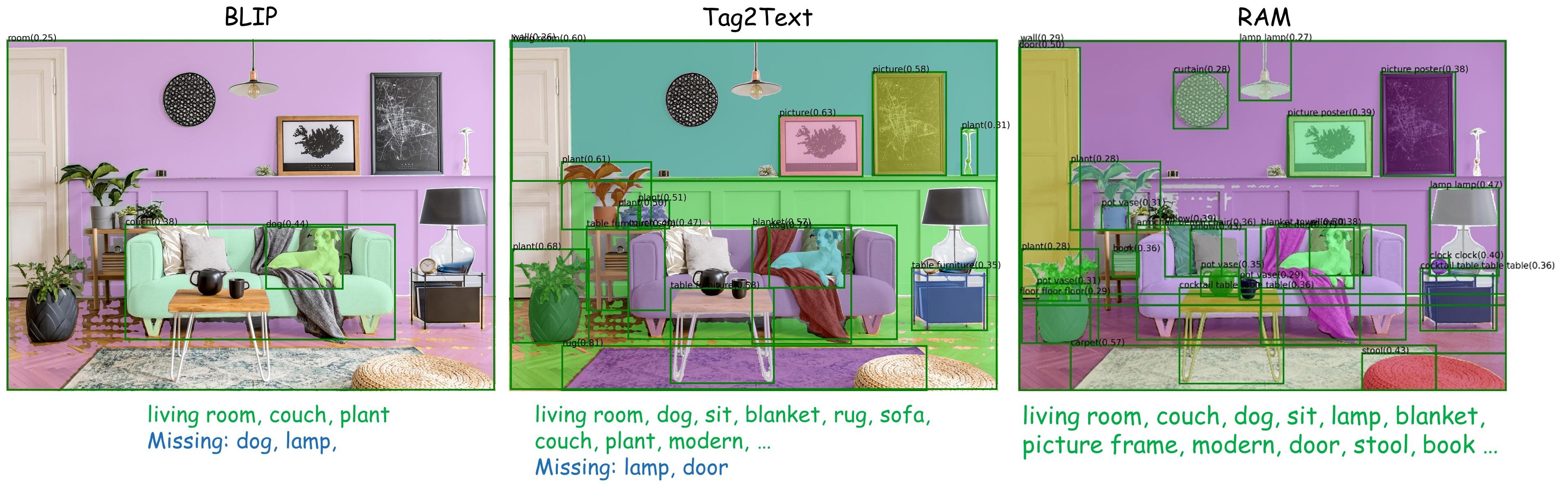
1단계) Tag를 잘 뽑는 RAM 모델을 활용하여 이를 Teacher 형식처럼 Finetuning하는 Module 구성
- 이를 통해 LR에서도 tag를 잘 뽑는 module 구성 (DAPE : Degradation-Aware Prompt Extractor )
2단계) DAPE 기반 module을 통해 추출된 값을 토대로 ControlNet 기반 T2I 모델로 다시 Finetuning
- 이를 통해 고품질 SR 이미지 생성
결과 굳.
1. Introduction
Image Super Resolution(ISR)이라고 불리는 분야에서 전통적인 방식은 잘 알려진 방식으로 degradation이 된 LR 저해상도 이미지를 기반으로 HR 고해상도 이미지를 만드는 것이 목적이다.
전통적인 방식은 과도하게 부드러운 결과 이미지를 산출하기 때문에 GAN 기반 방법이 도입되었다. 이 방법을 통해 지각적으로 훨씬 사실적인 이미지를 생산할 수 있었지만, 이 또한 artifact가 생기는 단점이 존재한다.
여기서 Real-world LR 이미지는 기존 LR 이미지와 달리 실제 세상 속에서 사용하는 알 수 없는 방식의 degradation이 진행되기 때문에 더 어려운 부분이 있다. 이를 극복하기 위해 연구자들은 real-world LR-HR 이미지 pair를 수집하거나 기초 degradtion 방식을 랜덤하게 조합한 시뮬레이션 방식을 채택하는 등 여러 방안을 제안했다. BSRGAN, Real-ESRGAN, 기타 등등의 방식을 통해 상당히 정확한 디테일을 살릴 수 있었지만, 이 또한 GAN 기반이기에 적대적 학습이 가지는 artifact 문제가 존재했다.
Diffusion에서도 inverse image restoration 문제를 푸는 방식을 활용하는데 여기에 large-scale pretrained text-to-image (T2I) model을 활용하여 image prior로 활용하고자 하는 접근 방식이 제안되었다.
대표적 예로 StableSR, PASD, DiffBIR 등이 제안되나 이들은 LR 이미지에만 의존한 방식을 채택할 뿐 semantic text 정보에 대해서는 간과한다.
semantic text 정보를 활용하기 위해 2가지 기준을 제안
1) prompt는 최대한 많은 object를 다뤄야 한다.
2) prompt는 degradation임을 인지한 상태로 추출되어야만 한다
여기서 본 논문은 Semantic prompt 정보를 적극 활용하는 Semantic-aware SR(SeeSR) 방식을 제안한다.
2가지 단계를 거친다.
1) semantic prompt exteractor를 fine-tuning
2) pristine semantic prompt와 LR이미지를 조합하여 HR 진행
3. Methodology
3.1 Motivation and Framework Overview
Motivation

Semantic prompt를 추출할 수 있는 3가지 방법 : classification style, caption-style, tag-style
그러나 각 방법에는 장점들도 존재하지만, semantic 처리에는 한계점이 존재
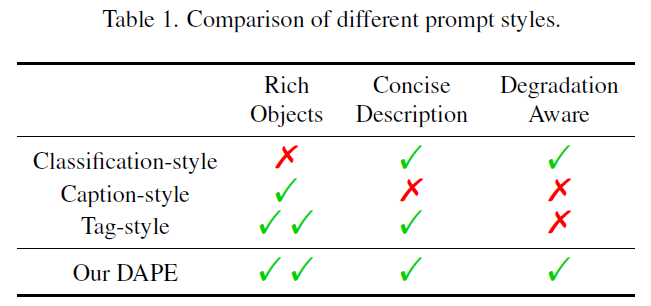
단점
classification style : local object에 대한 판별 불가.
caption-style : 중복된 전치사와 부사, 열화상태에서의 semantic 정보 추출 불가.
tag-style : 열화상태에서의 semantic 정보 추출 불가
Framework Overview

2 단계에 걸쳐 진행됨.
Stage 1) Degration-Aware Prompt Extractor (DAPE) finetuning
Stage 2) Stage 1에서 학습시킨 DAPE를 통해 LR 이미지의 feature representation과 tag 추출 후 LR이미지의 재구성 진행
3.2 Degradation-Aware Prompt Extractor (DAPE)
Recognize Anything(RAM) (23.06) 기반 DAPE finetuning 진행
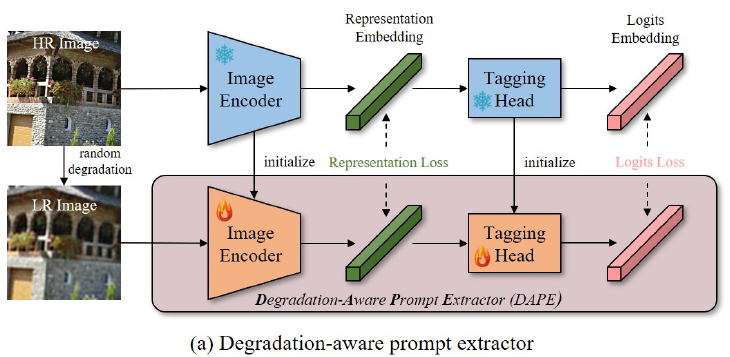
DAPE의 목적은 LR로부터 semantic한 prompt 추출할 수 있는 능력을 갖추는 것으로 이를 위해 RAM을 활용.
Training objective
1) HR을 통과해 얻은 Representation embedding과 LR을 통과해 얻은 DAPE의 Representation embedding간의 MSE (Representation Loss)
2) Tagging Head에서 얻어낸 Logit Embedding과 DAPE 내 Tagging Head를 통과한 Logit Embedding간의 Cross-entropy loss (Logits Loss)
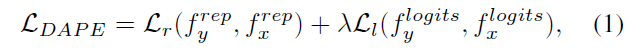
x : HR, y : LR
여기서 2가지 prompt를 추출 : hard prompt(tag texts from the tagging head : 분홍색 bar) & soft prompt (representation embeddings from the image encoder : 초록색 bar)
soft prompt는 hard prompt를 보완하기 위해 존재
3.3 Training of SeeSR Model
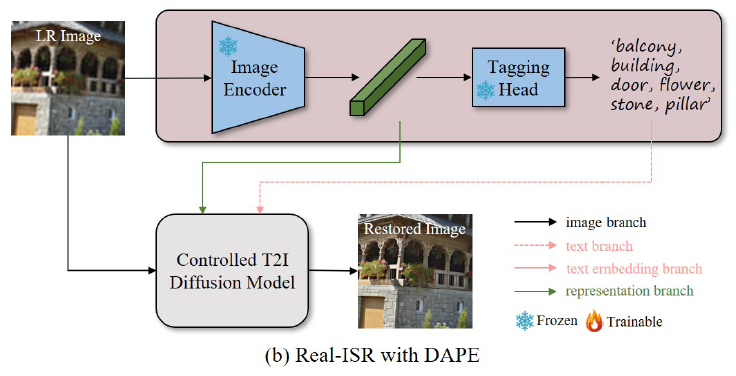
보이는 바와 같이 LR 이미지 + representation branch, Text branch 3가지를 ControlNet이 붙은 T2I Diffusion Model에 넣어 이미지 복원으로 활용한다.
이때, Stage 1에서 학습한 DAPE의 Image Encoder를 통해 도출된 representation embedding ( soft prompt )과 Tagging Head를 통과한 Text Prompt ( hard prompt )가 branch로 주입되는 형식

주입된 상황에서 T2I Unet은 freeze되고 ControlNet의 Encoder만 trainable하게 변함.
단, Representation cross-attention (RCA) module은 U-Net에서 trainable함.
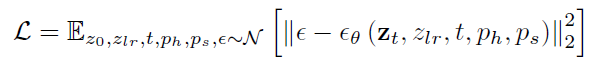
3.4 LR Embedding in Inference
training 단계에서 T2I는 이미지를 random Gaussian noise로 변환하지 않지만, Inference 단계에서는 random Gaussian noise를 시작 point로 잡음.

LRE 방식을 통해 시각적 품질 향상, 의미론적 일관성 유지, 과도한 디테일 생성 완화.
4. Experiments
4.1 Experimental Setup
Dataset : LSDIR, FFHQ 10K
Implementation
Stage 1)
DAPE 전체 finetuning을 위한 LoRA(r=8) 활용 (20 iters)
batch size, learning rate : 32, $10%{-4}$
Stage 2)
SD 2 base
150k iter
Adam
batch size, learning rate : 192, $5 \times 10%{-5}$
512x512
8 NVIDIA Tesla 32G-V100
spaced DDPM sampling(I-DDPM) - 50 steps
4.2 Comparisons with State-of-the-Art Methods
GAN 기반 : BSRGAN, Real-ESRGAN, LDL, FeMaSR, DASR
Diffusion 기반 : LDM, StableSR, ResShift, PASD, DiffBIR


User Study - 20명, 16 합성 set, 16 실제 set 설문지

4.3 Semantic Preservation Test
detection & segmentation

