[논문 Summary] Generative Image Dynamics (CVPR 2024 Best Paper Award) "Generative Image Dynamics"
[논문 Summary] Generative Image Dynamics (CVPR 2024 Best Paper Award) "
Generative Image Dynamics"
논문 정보 (Citation, 저자, 링크)
Citation : 2025.03.08 토요일 기준 56회
저자 (소속) : ( Zhengqi Li, Richard Tucker, Noah Snavely, Aleksander Holynski ) [ Google Research ]
논문 & Github 링크 : [ Project page ] [ Arxiv ] [ 대체 Github ]
논문 Summary
0. 설명 시작 전 Overview

1. Introduction
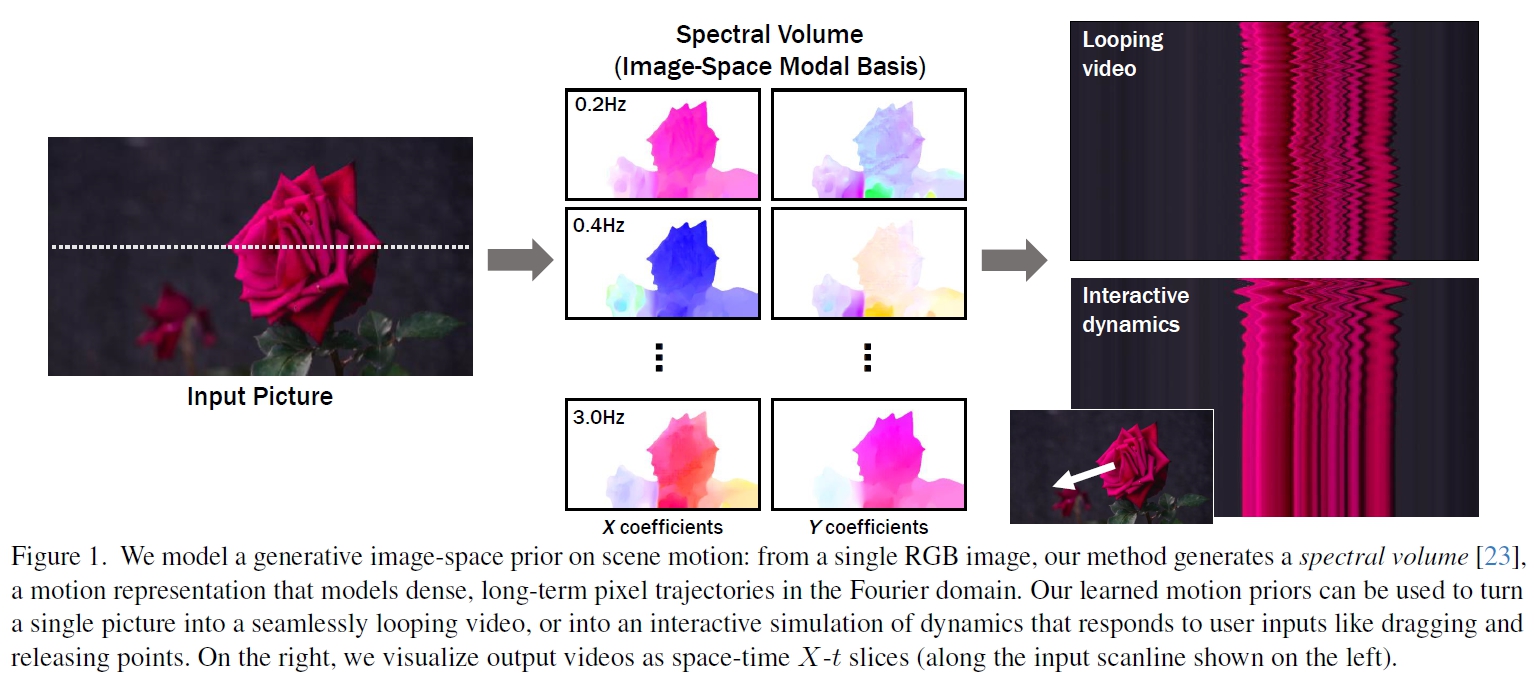
배경설명
실제 세계는 정적인 장면처럼 보여도, 미세한 진동이나 바람·물결 등에 의해 모든 것이 움직인다.
사람이 단일 이미지를 봐도 쉽게 움직임을 상상할 수 있는 것과 달리, 컴퓨터가 물리 법칙 전반을 학습하고 실제처럼 움직이게 만드는 것은 쉽지 않다.
그러나 실제 2D 영상으로부터 픽셀 레벨의 움직임(trajectory)만 충분히 파악해도, 물리적 속성(질량·탄성 등)을 직접 계산하지 않고도 그럴듯한 동적인 결과물을 생성할 수 있다.
본 논문은 diffusion model을 통해 이러한 2D 모션을 학습함으로써, 단일 이미지를 바탕으로 자연스러운 ‘진동적(oscillatory) 움직임’을 재현할 수 있는 프레임워크를 제안한다.
.Method
저자들은 단일 이미지의 픽셀 단위 움직임(image-space scene motion)에 대한 확률적 사전 분포(generative prior)를 학습. 대규모 실제 영상(나뭇잎, 꽃, 촛불 등)에서 추출된 밀도높은 긴 모션 궤적 (motion trajectory) 을 스펙트럴 볼륨(Spectral Volume)로 변환 후 모델을 훈련. 스펙트럴 볼륨(Spectral Volume) 기반 표현을 사용하여, 주파수 대역에서 주로 발생하는 자연스러운 ‘진동 모션( oscillatory dynamics motion)’을 효과적으로 모델링.
cf) Motion Texture 개념 조사 정리
Motion Texture는 이미지의 각 픽셀에 대한 움직임 벡터를 시간 순서대로 나열한 것. 각 픽셀은 특정 시점에서 특정 방향으로 얼마나 이동하는지에 대한 정보를 담고 있으며, 이러한 정보는 2D 변위 맵 형태로 표현함. 이러한 변위 맵들을 시간 순서대로 연결하면, 이미지 전체의 움직임을 나타내는 Motion Texture가 됨.
결과
기존의 Raw RGB를 직접 생성하는 방법과 달리, 모션만 따로 예측하고 이미지를 합성함으로써 더 일관되고 긴 영상 생성이 가능할 뿐 아니라 animation에 있어 더 섬세한 제어가 가능함.
이에 따라 아래 방법론이 가능
- Seamless Looping Video: 일정 프레임 수 후 되돌아와도 이질감이 없는 루프형 영상 생성
- Motion Editing: 예측된 모션을 원하는 방식으로 편집·조정
- Interactive Dynamic Image: 사용자가 이미지를 드래그해 물체를 당기면, 그 뒤 ‘진동’하는 듯한 반응이 일어나는 시뮬레이션
2. Related work
Generative synthesis & Animating images
사실적인 이미지를 생성하는 텍스트-이미지 모델을 확장하여 비디오 시퀀스를 생성하는 연구들이 진행 중.
이미지 텐서를 시간 temporal dim으로 확장하는 방식을 사용
하지만 이러한 방법들은 생성된 비디오에서 움직임이 부자연스럽거나 텍스처가 일관성 없이 변화하거나 물리적 제약(예: 질량 보존)을 위반하는 문제점 생김.
한계 극복을 위해 외부 source( video, motion, 3d geometry priors, annotations )를 기반한 motion generation을 진행
motion field를 통한 이미지 animating 또한 일관성 뛰어난 영상을 만들지만 추가적인 guidance나 움직임 표현에 제약 존재.
Motion models and motion priors
oscillatory 3D motion
Fourier domain에서 노이즈를 조작하여 시간 영역의 모션 필드를 생성하는 방식과, 시스템의 역학을 분석하는 modal analysis에 기반한 접근 방식들
Visual vibration analysis[23]에 가장 큰 영감을 받음.
특히, frequency-space spectral volume motion representation 차용
최근 optical flow motion estimate에 근간한 prediction task를 통해 motion representation도 활발히 진행됨.
Videos as textures
Dynamic Texture 또는 Video Texture라 불리는 접근에서는, 움직이는 장면(예: 물결, 나뭇잎, 불꽃)을 ‘시공간적 확률 분포’로 간주하고, 그 패턴을 반복·연장해 무한히 재생 가능한 영상을 만들곤 함.
하지만 이러한 방법들은 대체로 주어진 동영상이 있어야 하거나, 사용자 지정(영상 프레임을 어떻게 연결할지 결정)에 대한 의존도가 높아, 임의의 정지 이미지에 적용하기가 쉽지 않음
3. Overview
입력 : Input Image $I_0$
목표 : 단일 이미지 $I_0$가 주어졌을 때, oscillatory motion이 가능한 비디오 를 생성하는 것
2개의 모듈 : Motion Prediction Module, Image-based Rendering Module
방법
1) Spectral Volume $\mathcal{S} = (S_{f_0}, S_{f_1} , S_{f_2} , \cdots, S_{f_{K-1}} )$ 예측을 위한 LDM 사용
2) 예측한 spectral volume은 Inverse Discrete Fourier Transform을 통해 motion texture $ \mathcal{F} = (F_1, F_2, \cdots, F_T)$로 변환.
해당 motion은 모든 future time step에서 각 입력 픽셀의 위치를 결정함.
3) Motion Texutre가 주어졌을 때, image-based Rendering 기술을 활용하여 RGB 이미지에 애니메이션 적용
4. Predicting motion

4.1. Motion representation
Motion Texture 정의: 시간 변화에 따른 2D 변위 맵의 시퀀스 $ F = \{F_t | t = 1, ..., T\} $로 정의됩니다. 여기서 $ F_t(p) $는 입력 이미지 $ I_0 $의 각 픽셀 좌표 $ p $에서 미래 시간 $ t $에서의 픽셀 위치를 나타내는 2D 변위 벡터
$$ I_t'(p + F_t(p)) = I_0(p). $$
$ I'_t(p + F_t(p)) = I_0(p) $ : 미래 프레임 $ t $를 생성하기 위해 입력 이미지 $ I_0 $의 픽셀들을 해당 변위 맵 $ F_t $를 사용하여 이동(splat)시켜 얻는 forward-warped 이미지 $ I'_t $를 나타냅니다.
단순히 motion texture로 video를 생성할 수 있으나 video 길이에 따른 motion texture의 사이즈도 커진다.
e.g. T개의 output frame을 위해서 T 개의 displacement field가 필요
이를 회피하기 위한 2가지 방법(Autoregressively video frame을 생성, 추가 time embedding을 통해 독립적으로 예측) 또한, 장기 temporal consistency에 대한 제약이 발생함.
자연스러운 움직임은 여러 주파수, 진폭, 위상을 가진 조화 진동자들의 중첩으로 표현될 수 있습니다. 이러한 움직임은 quasi-periodic하기 때문에 주파수 영역에서 모델링하는 것이 효과적입니다. 따라서 이 논문에서는 spectral volume 이라는 주파수 공간 표현을 도입합니다. spectral volume 은 비디오에서 추출한 픽셀별 궤적(trajectory)을 시간 축에 대해 푸리에 변환한 것입니다
수식 (2)는 픽셀의 모션 궤적 $ F(p) = \{F_t(p) | t = 1, 2, ..., T\} $와 스펙트럴 볼륨 $ S(p) = \{S_{f_k}(p) | k = 0, 1, .., \frac{T}{2} - 1\} $ 사이의 관계를 고속 푸리에 변환(FFT)을 통해 나타냅니다:
$$ S(p) = \text{FFT}(F(p)) $$
스펙트럴 볼륨은 자연스러운 움직임이 주로 저주파 성분으로 구성된다는 점을 활용하여, 적은 수의 주파수 성분만으로도 효과적으로 모션을 표현할 수 있습니다.
모션 예측 문제는 입력 이미지를 스펙트럴 볼륨으로 변환하는 다중 모달 이미지-대-이미지 변환 작업으로 공식화됩니다.
LDM을 사용하여 4K 채널의 2D 모션 스펙트럼 맵으로 구성된 스펙트럴 볼륨을 생성하며, 여기서 K는 모델링된 주파수 개수이고, 각 주파수에서 x 및 y 차원에 대한 복소 푸리에 계수를 나타내는 네 개의 스칼라가 필요
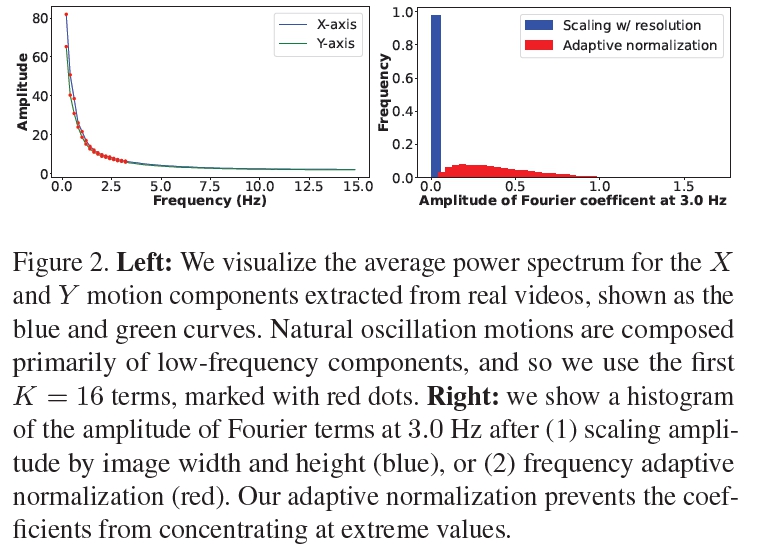
K개의 출력 주파수를 선택하는 방법으로, 자연스러운 진동 움직임이 주로 낮은 주파수 성분으로 구성된다는 기존 연구
실제 비디오 클립에서 추출한 움직임의 평균 파워 스펙트럼을 분석했습니다.
낮은 주파수 성분: 자연스러운 진동 움직임은 대부분 낮은 주파수 성분으로 이루어져 있다는 점을 활용합니다.
파워 스펙트럼 분석: 1,000개의 실제 비디오 클립에서 추출한 움직임의 평균 파워 스펙트럼을 계산하여, 주파수가 증가함에 따라 모션의 파워 스펙트럼이 지수적으로 감소하는 것을 확인했습니다.
K=16: 실험 결과, 처음 16개의 Fourier 계수(K=16)만으로도 실제 비디오에서 원래의 자연스러운 움직임을 충분히 재현할 수 있음을 발견했습니다.
4.2. Predicting motion with a diffusion model
논문에서 제시된 LDM의 학습 손실 함수 (loss function)는 다음과 같습니다.
$\qquad L_{LDM} = \mathbb{E}_{n \in U[1, N], \epsilon_n \in N(0, 1)} [||\epsilon_n - \epsilon_\theta(z_n; n, c)||^2]$
$L_{LDM}$: LDM의 손실 함수를 나타냅니다.
$\mathbb{E}_{n \in U[1, N], \epsilon_n \in N(0, 1)}$: $n$은 1부터 $N$까지의 균등 분포에서 추출된 값이고, $\epsilon_n$은 평균이 0이고 분산이 1인 정규 분포에서 추출된 잡음입니다. 이 기호는 해당 분포에서 추출된 값들에 대한 기댓값을 계산한다는 의미입니다.
$||\epsilon_n - \epsilon_\theta(z_n; n, c)||^2$ : 모델이 예측한 잡음과 실제 잡음 간의 차이의 제곱을 나타냅니다.
Frequency adaptive normalization
문제점:
1) Spectral Volume의 진폭은 0~100이며 주파수가 증가함에 따라 지수적으로 감소
2) diffusion model은 안정적인 학습과 출력값이 -1~1 사이가 되도록 normalize할 필요가 있음
3) coefficient를 0~1로 만들경우 고주파 성분이 대부분 0에 가까워 예측 오차가 크게 나타날 수 있음.
해결책 순서
1) Independently normalize Fourier coefficient at each frequency: 각 주파수 $f_j$에 대해, 훈련 세트에서 계산된 통계(95th percentile 백분위수)를 기반으로 Fourier 계수를 독립적으로 정규화합니다. 이 값을 주파수별 스케일링 요소 $s_{f_j}$로 사용합니다.
2) Power Transformation: 스케일링된 Fourier 계수에 power Transformation을 적용하여 값이 극단적인 값으로 치우치지 않도록 합니다. 실험적으로 제곱근 변환이 로그나 역수와 같은 다른 비선형 변환보다 성능이 더 좋습니다.
-> $x^\lambda$= x to the power of lambda / $\lambda$ = power or exponent
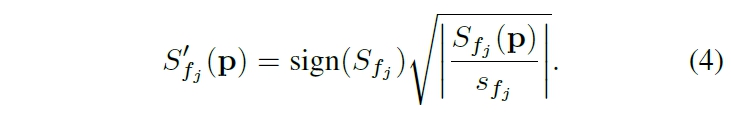
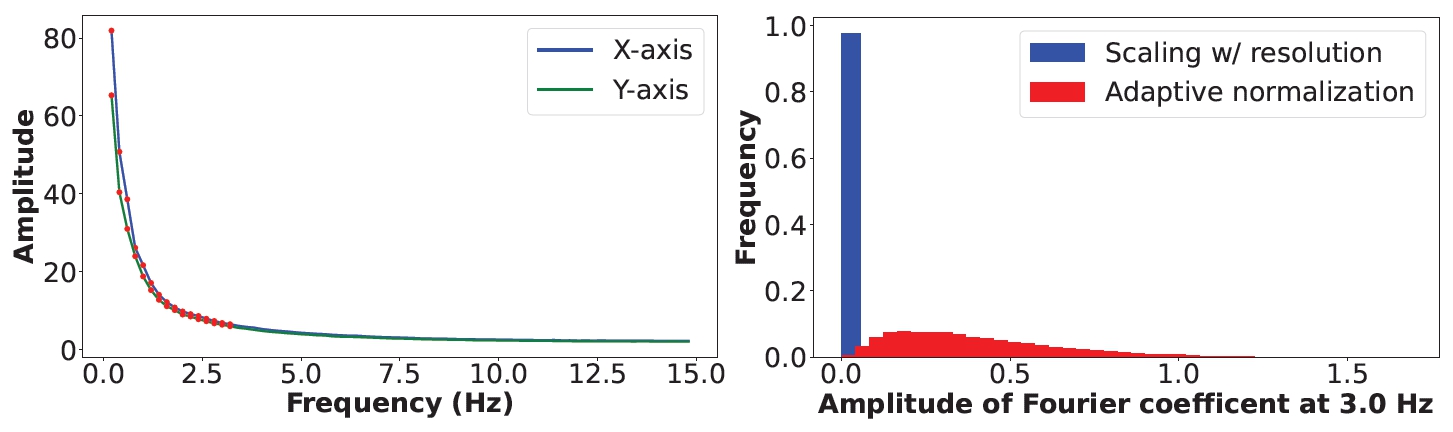
frequency adaptive normalization 적용 후, spectral volume coefficient distribution이 고르게 분포하게 됨.
참조) 왜 95th percentile을 사용할까
95번째 백분위수는 데이터 세트에서 상위 5%에 해당하는 값을 의미한다. 평균이나 표준편차를 사용하는 대신 이 값을 선택하는 주된 이유는 이상치에 덜 민감하기 때문이다. 가령 예를 들어 비디오 데이터에는 예기치 않은 큰 움직임이나 노이즈로 인해 매우 큰 Fourier 계수 값을 가질 수 있으므로 이러한 이상치는 평균값을 크게 왜곡시켜 정규화 과정을 불안정하게 만들 수 있다.그러나 95번째 백분위수를 사용하면 이러한 극단적인 값의 영향을 줄여 정규화 과정을 더 안정적으로 만들 수 있다.
Frequency-coordinated denoising
문제점:
1) K frequency band의 spectral volume 예측시 4K Channel tensor 출력하는 경우: 많은 채널 생성으로 인해 결과물이 흐릿해지고 부정확해질 수 있다는 이전 연구 결과 존재.
2) frequency embedding 주입을 통해 각 frequency slice를 독립적으로 예측시: frequency 영역에서 상관 관계가 없는 예측을 초래하여 부자연스러운 움직임이 생성될 수 있다.
제안 전략: Frequency-coordinated denoising strategy
순서 1) LDM(Latent Diffusion Model)을 학습시켜 Spectral volume $S_{f_j}$의 단일 4채널 frequency slice를 예측. 이때, time-step embedding을 따라 추가적인 frequency embedding을 LDM에 주입.
순서 2) 학습된 LDM의 파라미터 freeze
순서 3) 2D spatial layer와 attention layer를 K frequency band에 걸쳐 교차로 배치(interleave)한 후 fine-tuning. 이를 통해 frequency attention layer가 모든 frequency slice를 조정하여 일관성 있는 스펙트럴 볼륨을 생성하도록 한다.
K frequency band에 걸쳐 교차로 배치(interleave) 예시)
2D spatial layer
Attention layer
2D spatial layer
Attention layer
... (K frequency band에 걸쳐 반복)
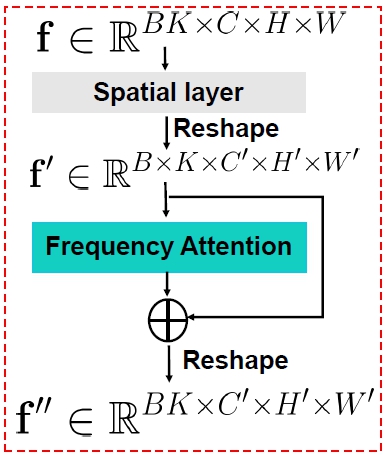
Frequency attention layer의 목표는 개별 frequency slice들이 서로 독립적으로 생성되지 않고, 전체 스펙트럴 볼륨 내에서 일관성 있는 관계를 유지하도록 하는 것.
e.g. 특정 frequency에서 큰 움직임이 예측되었다면, 인접한 frequency에서도 유사한 움직임이 나타나도록 조정하는 것
Frequency-coordinated denoising 모듈을 사용했을 때 VAE의 reconstruction error가 0.024에서 0.018로 감소했고, 비디오 생성 품질 또한 향상
5. Image-based rendering
입력 이미지 $ I_0 $에서 예측된 Spectral volume $ S $을 사용하여 미래 시점 $ t $에서의 frame $ \hat{I}_t $을 render 방법 소개.
순서 1) 픽셀별 Inverse temporal FFT를 적용하여 time domain motion texture $ \mathcal{F}(p) $를 얻습니다.
$$ \mathcal{F}(p) = \text{FFT}^{-1}(S(p)) $$
$ F(p) $: 모션 텍스처(motion texture)입니다. 이는 픽셀 위치 $ p $에서의 시간에 따른 변위(displacement)를 나타내는 함수입니다. 즉, 입력 이미지의 각 픽셀이 미래 시점에서 어디로 이동하는지를 나타내는 2D 변위 벡터들의 시퀀스입니다.
$ S(p) $: 스펙트럴 볼륨(spectral volume)입니다. 이는 픽셀 위치 $ p $에서의 모션 궤적을 주파수 영역으로 표현한 것입니다. 스펙트럴 볼륨은 해당 픽셀의 시간에 따른 움직임을 Fourier 변환하여 얻어지며, 다양한 주파수 성분들의 크기와 위상을 포함합니다.
$ \text{FFT}^{-1} $: 역 푸리에 변환(Inverse Fourier Transform)입니다. 이 연산은 주파수 영역의 스펙트럴 볼륨 $ S(p) $를 시간 영역의 모션 텍스처 $ F(p) $로 변환하는 데 사용됩니다.
순서 2) Deep Image-based Rendering Technique을 활용한 예측된 모션 필드 $ F_t $로 입력 이미지 $ I_0 $를 forward-warp 수행. 이때, feature pyramid softmax splatting strategy 수행
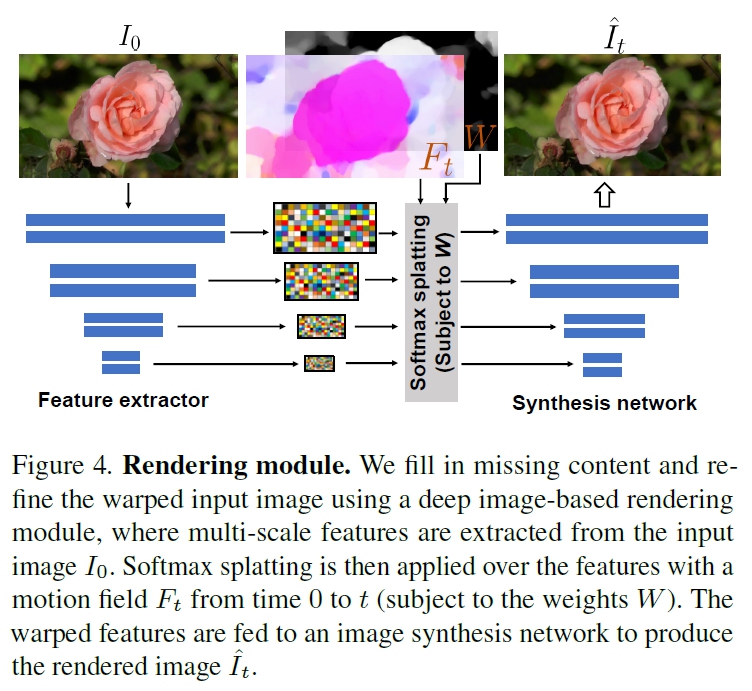
순서 1) Feature Extractor Network를 통한 $I_0$ multi-scale feature map 추출
순서 2) scale j에 따른 해상도별 Motion Field $F_t$ resize & scale
순서 3) 예측된 Flow Magnitude를 Depth Proxy로 사용하여 각 소스 픽셀의 가중치 $W$ 결정
3)-(1) Depth Proxy로서의 Flow Magnitude 준비 (Davis et al. [22]의 방법 참고)
단일 이미지에서 정확한 깊이 정보를 얻는 것은 어려운 문제이기에 예측된 flow magnitude (움직임의 크기)를 depth의 proxy로 사용
3)-(2) Per-pixel 가중치 계산:
픽셀별 가중치 $W(p)$를 motion texture의 평균 magnitude로 계산.
$$ W(p) = \frac{1}{T} \sum_{t} ||F_t(p)||^2 $$
여기서 큰 움직임은 전경 객체에, 작거나 0에 가까운 움직임은 배경에 해당한다고 가정.
Motion-drived weights(학습 X)를 사용하는 이유는 단일 시점에서는 학습 가능한 가중치가 disocclusion ambiguities를 해결하는 데 효과적이지 않기 때문입니다. 즉, 움직임 정보를 통해 가려진 영역을 더 자연스럽게 추론하고자 하는 것입니다.
순서 4) Softmax Splatting 적용:
Motion field $F_t$와 가중치 $W$를 사용하여 각 스케일의 Feature map에 softmax splatting을 적용하여 warped feature를 생성합니다.
순서 5) Image Synthesis Decoder에 Warped Feature 주입하여 최종 rendering 이미지 생성:
Warped feature를 image synthesis decoder의 해당 블록에 주입하여 최종 렌더링된 이미지 $\hat{I_t}$를 생성합니다.
학습
실제 비디오에서 랜덤하게 샘플링한 시작과 target frame을 사용하여 feature extractor와 synthesis network 모두 함께 학습
이때 추정한 flow field와 VGG perceptual loss 사용
6. Applications
Image-to-video (이미지에서 비디오 생성):
본 논문에서는 정지 이미지를 입력받아 움직이는 motion spectral volume을 예측하고, image-based rendering module을 통해 애니메이션을 생성하는 시스템을 제안합니다.
Scene motion을 명시적으로 모델링하여, motion texture를 선형 보간함으로써 슬로우 모션 비디오를 만들거나, spectral volume coefficients의 진폭을 조절하여 움직임을 확대/축소할 수 있습니다.
Seamless looping (끊김 없는 반복 비디오 생성):
끊김 없이 반복되는 비디오를 생성하기 위해, 일반 비디오 클립으로 학습된 motion diffusion model을 사용하여 motion self-guidance 기법을 적용합니다.
이는 각 픽셀의 위치와 속도가 시작 프레임과 끝 프레임에서 유사하도록 하여 자연스러운 반복 효과를 얻습니다.
기존의 appearance-based looping 알고리즘 [58]과 비교했을 때, 본 논문에서 제안하는 방법이 왜곡이 적고 더 나은 결과를 보여줍니다.

Interactive dynamics (상호 작용적인 움직임):
Spectral volume을 특정 공진 주파수에서 평가하여 image-space modal basis를 근사하고, 이를 통해 사용자가 정의한 힘에 대한 객체의 반응을 시뮬레이션합니다 (22).
Motion spectrum coefficients와 complex modal coordinates를 사용하여 2D motion displacement field를 계산하고, explicit Euler method를 통해 modal coordinates의 상태를 시뮬레이션합니다.
이 방법은 단일 이미지에서 상호 작용적인 장면을 생성할 수 있다는 장점이 있습니다. 기존 방법들은 비디오를 입력으로 요구했습니다.
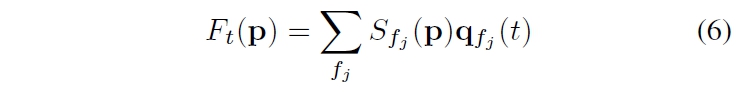
7. Experiments
Implementation details
모델 구조 및 학습:
**LDM (Latent Diffusion Model)**을 backbone으로 사용하며, 스펙트럴 볼륨을 예측하기 위해 **VAE (Variational Autoencoder)**를 사용합니다. VAE는 4차원의 연속적인 latent space를 가집니다.
VAE는 L1 reconstruction loss, multi-scale gradient consistency loss, KL-divergence loss를 사용하여 학습됩니다. 각 loss의 가중치는 1, 0.2, 10^-6 입니다.
LDM은 2D U-Net을 사용하여 iterative denoising을 수행하며, MSE loss를 사용합니다. Frequency-coordinated denoising을 위해 attention layer가 사용됩니다.
학습 환경:
VAE와 LDM은 256x160 크기의 이미지에 대해 처음부터 학습됩니다.
16개의 Nvidia A100 GPU를 사용하여 약 6일이 소요됩니다.
Motion diffusion model은 DDIM을 사용하여 250 step으로 실행됩니다.
데이터 해상도:
최대 512x288 해상도의 비디오가 생성됩니다. 이는 pre-trained image inpainting LDM 모델을 fine-tuning하여 얻습니다.
Feature 추출 및 렌더링:
IBR (Image-Based Rendering) 모듈에서 feature 추출기로 ResNet-34가 사용됩니다.
이미지 합성 네트워크는 conditional image inpainting 아키텍처를 기반으로 합니다.
렌더링 모듈은 Nvidia V100 GPU에서 실시간으로 25FPS로 실행됩니다.
Seamless Looping:
Seamless looping 비디오 생성을 위해 universal guidance가 사용됩니다. 가중치는 w = 1.75, u = 200으로 설정하고, 500 DDIM step과 2 self-recurrence iteration을 사용합니다.
Data
연구진은 자연스러운 장면에서 oscillatory motions을 보이는 3,015개의 비디오를 온라인에서 수집하고 자체적으로 촬영하여 데이터 세트를 구축했습니다.
수집된 비디오 중 10%는 테스트용으로 보류하고, 나머지는 학습에 사용했습니다.
Ground truth motion trajectories를 추출하기 위해, 각 시작 이미지와 비디오의 미래 프레임 사이의 움직임을 coarse-to-fine flow method [10, 61]를 사용하여 추정했습니다.
학습 데이터로, 매 10번째 비디오 프레임을 입력 이미지로 사용하고, 그에 상응하는 ground truth spectral volumes을 계산된 motion trajectories를 기반으로 추출했습니다. 이때, 149 프레임에 걸쳐 움직임을 추적했습니다.
최종적으로 15만 개 이상의 이미지-모션 쌍으로 구성된 데이터 세트를 구축했습니다
7.1. Quantitative results

Our approach significantly outperforms prior single-image animation baselines
our much lower FVD and DT-FVD distances suggest that the videos generated by our approach are more realistic
and more temporally coherent
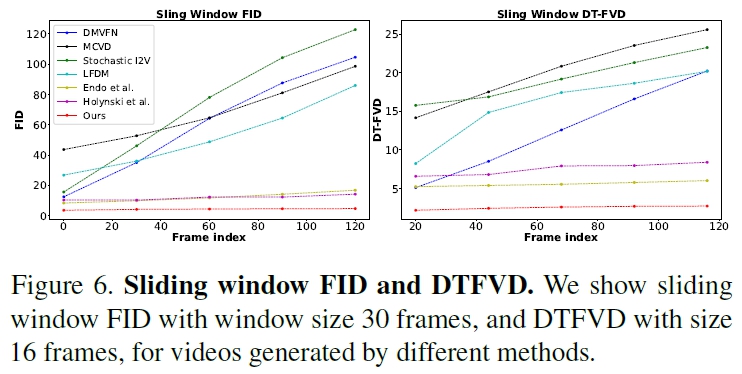
Thanks to the global spectral volume representation, videos generated by our approach do not suffer from degradation over time.
7.2. Qualitative results

comparisons between videos as spatio-temporal X-t slices of the generated videos
our generated video dynamics more strongly resemble the motion patterns observed in the corresponding real reference videos
7.3. Ablation study
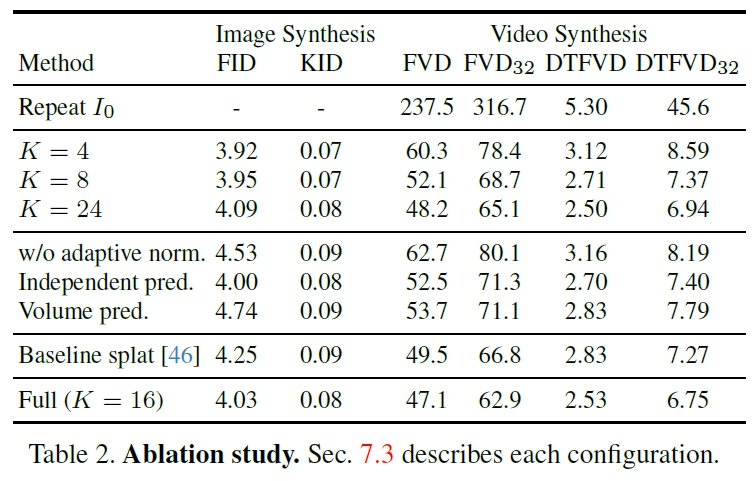
increasing the number of frequency bands improves video prediction quality
7.4. Comparing to large video models

ask users “which video is more realistic?”. Users report a 80.9% preference for our approach over others.
8. Discussion and conclusion
Limitations

한계 1)
이 모델은 spectral volume의 low frequency만 예측하기 때문에, non-oscillating motion 비진동 움직임이나 high frequency 고주파 진동을 모델링하는 데 실패할 수 있습니다.
한계 2)
생성된 video의 품질은 underlying motion trajectories의 품질에 의존하며, 이는 얇은 moving objects 또는 큰 displacement를 가진 objects가 있는 장면에서 저하될 수 있습니다.
Reference
도움이 되는 YouTube 1.
https://youtu.be/6e7xXVy06Fg?si=sB1kGUj1pHWrLy1O
도움이 되는 Blog.
https://lunaleee.github.io/posts/gid/
0000
