[논문 Summary] StyleGAN2 (2020 CVPR) "Analyzing and Improving the Image Quality of StyleGAN"
[논문 Summary] StyleGAN2 (2020 CVPR) "Analyzing and Improving the Image Quality of StyleGAN"

논문 정보
Citation : 2022.05.14 토요일 기준 1545회
저자
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila - NVIDIA
논문 링크
Official (10 pages)
CVPR 2020 Open Access Repository
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 8110-8119 The style-based GAN architecture (StyleGAN) yields state-of-
openaccess.thecvf.com
Arxiv (권장, Appendix 포함 21 pages)
https://arxiv.org/abs/1912.04958
Analyzing and Improving the Image Quality of StyleGAN
The style-based GAN architecture (StyleGAN) yields state-of-the-art results in data-driven unconditional generative image modeling. We expose and analyze several of its characteristic artifacts, and propose changes in both model architecture and training m
arxiv.org
논문 Summary
Abstract

0. 설명 시작 전 Overview
본 논문에서 제안하는 방법들을 요약하면 다음과 같습니다. (Table 1)
1) 물방울 모양의 artifacts들이 생겨 AdaIN을 포함하는 Generator의 전반적 수정 (위치, 구조, Normalization 개선)
2) 이미지 개선을 위한 Path length regularization 활용
3) Progressive growing의 문제점(Phase artifact)을 개선하기 위한 새로운 모델 구조 제안
4) Capacity 문제를 해결하기 위한 상위 layer의 feature map 증가
5) Latent Space(잠재 공간)로의 Projection (Inversion)
필수 논문 : 이전 논문인 StyleGAN
권장 논문 : WGAN, WGAN-GP, SNGAN, BigGAN, PGGAN(ProGAN)
SNGAN : https://aigong.tistory.com/371
PGGAN : https://aigong.tistory.com/65
StyleGAN : https://aigong.tistory.com/422
1. Introduction
[StyleGAN 요약 - 중략]
StyleGAN에서 characteristic artifacts를 발견할 수 있어왔다. 이에 저자들은 2가지 원인이 있다고 판별하고 이를 제거하기 위한 구조적 변화를 기술한다.
1) blob-like artifact (물방울 같은 artifact)를 흔히 발견할 수 있었는데 이는 Generator가 구조적 디자인 결함을 회피하기 위해 발생시키는 것이라 발견하였다. 이에 normalization을 다시 구성하여 이를 해소한다. (Section 2)
2) progressive growing과 관련된 artifact (phase artifact)를 분석하고 새로운 대체 디자인을 제안하여 전체적인 구조는 변화시키지 않으며 동일한 목표를 이룰 수 있는 효율적인 모델을 구성한다. (Section 4)
본 논문에서 FID, Precision and Recall(P&R)은 이미지 질을 정량하는 지표로 활용한다. 그러나 이 지표들은 shape보다 texture에 집중하기 때문에 이미지의 질을 모든 방면으로 정확히 평가하기 어렵다.
PPL(Perceptual Path Length) 지표는 모양의 안정성과 일관성과 연관이 깊기에 이를 regularizer로 활용함으로써 이미지의 질적 향상을 이룰 수 있다. (Section 3)
cf) PPL은 StyleGAN에서는 disentanglement를 판별하기 위해 linearity를 추정했다.
마지막으로 잠재 공간 $\mathcal{W}$로의 이미지 Projection시 상당히 잘 작동하는 것을 확인할 수 있었다. (Section 5)
2. Removing normalization artifacts


StyleGAN에서는 blob-shaped artifact (=droplet-like artifact)가 발생한다. 이는 64x64 해상도에서부터 나타나기 시작하고 점진적 해상도가 높아질수록 더 강해진다.
이는 각 feature map의 mean과 variance를 개별적으로 normalize함으로써 feature map간 상대적 차이에서 나오는 크기 정보를 잠재적으로 파괴하는 AdaIN의 문제로 발생한다고 본다
저자들의 가정 : (실제 데이터 기반의) 통계 기반의 강력하고 localized된 spike를 만듬으로써 Generator가 다른 원하는 곳에 효과적인 신호를 줄 수 있다고 판단.
실제로 AdaIN 부분의 normalization을 Generator에서 제거했을 때 artifact가 완전히 사라짐.

번외) Figure 15에서 보이듯 초기 resolution feature map에서 droplet이 없는 경우 (2행), overshoot, currupted image(심각하게 문제되는 이미지)가 발생되지만 1행과 같이 droplet이 지속적으로 생기는 경우 일부분만이 문제가 된다.
2.1. Generator architecture revisited

1) bias와 noise operation을 Style Block 밖으로 뺀다.
2) normalization과 modulation에 표준편차(std)만을 사용하는데 충분하다.
3) 초기 constant input에 적용하는 bias, noise, normalization을 제거해도 큰 문제가 생기지 않기에 제거한다.
2.2 Instance normalization revisited
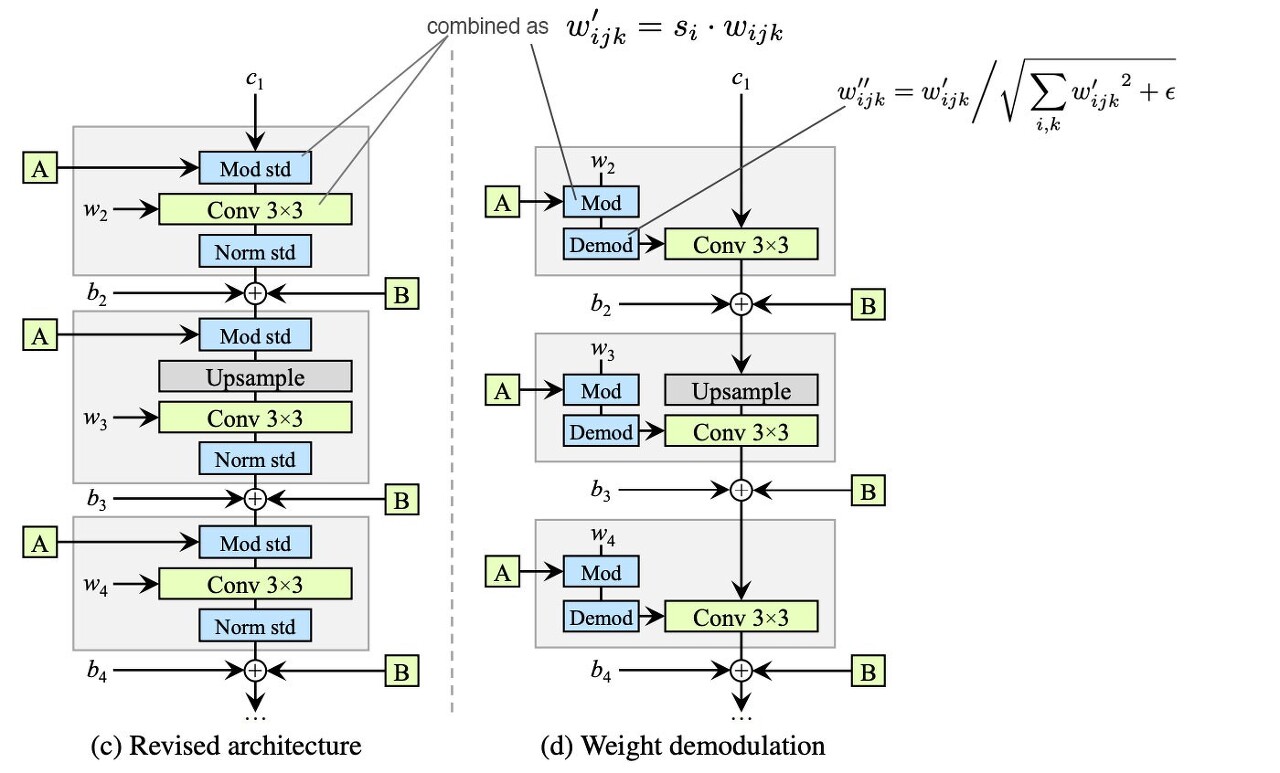
주요 아이디어는 명시적 강제없이 들어오는 feature map의 expected statistics(예측 통계)를 기반으로 normalization을수행하는 것이다.
(즉, conv 연산에 직접적인 modulation을 적용하지 않는 것)
Figure 2. (c)에서 Style block은 modulation, convolution, normalization으로 구성된다.
1) Modulation 시 convolution weight scaling (기존 AdaIN은 feature map의 평균 분산을 normalizing에서의 scaling)
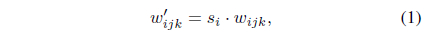
2) 모든 input activation이 unit std를 가지는 i.i.d random variable일 때의 output activation std
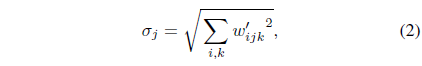
3) Demodulation (weight normalization)

이를 통해 AdaIN의 기능을 대체하는 것이 가능하다.
제안한 새로운 디자인은 characteristic artifact를 제거하고 완전한 제어권을 유지, 보유한다.
(코드를 통해 추후 살펴볼 필요가 있음. 추후 설명 보강 필요)


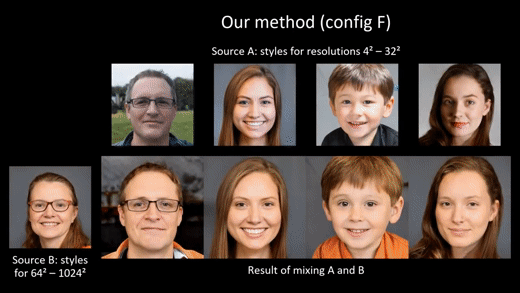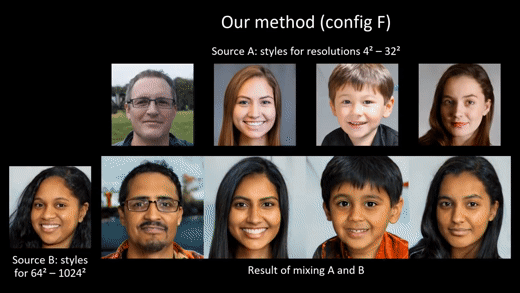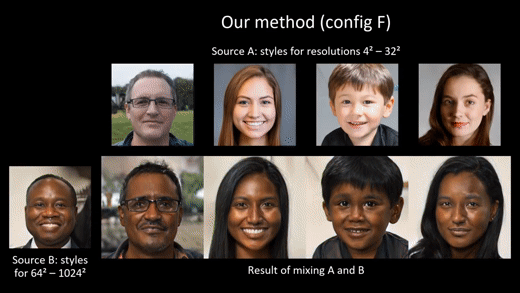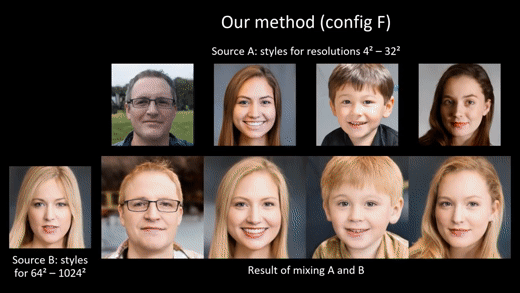
3. Image quality and generator smoothness
Metric으로 사용하는 FID, Precision, Recall(P&R)들은 이미지 평가에 있어 부족한 점이 존재한다.
Image quality와 Perceptual path Length(PPL)간의 상관관계가 존재한다.

낮은 PPL은 전반적인 이미지 quality가 좋아짐을 확인할 수 있다.
이에 대한 저자들의 해석
- 훈련시 discriminator는 나쁜 이미지에 대해 가짜로 판별내려서 쓰지 못하게 만들고, generator는 좋은 이미지를 창출하는 latent space 영역을 확장하고 나쁜 quality 이미지는 작은 latent space 영역을 줄여버리는 방식으로 성능을 개선한다고 가정.

같은 FID, 비슷한 P, R임에도 PPL이 낮은 것이 더 좋은 이미지를 생성함을 확인할 수 있다.
3.1 Lazy regularization
computation cost와 전반적인 memory 사용량을 줄이기 위해 main loss function보다 더 적은 횟수로 regularization을 계산함. (대략 16 mini-batch마다 한번의 regularization 수행.)
3.2 Path length regularization
gradient들은 $w$나 무작위로 전진하는 이미지 공간의 방향과 무관하게 최대한 동일한 길이를 가져야 한다.
이를 위한 regularizer는 다음과 같다.

이 식은 어느 $w$에 대해서도 $J_w$가 orthogonal할 때 최소가 된다. (추구하는 방향)
Orthogonal matrix는 길이를 보존하고 어느 차원을 따라서도 squeeze되지 않는다.
Jacobian matrix를 구할 때는 명시적 계산이 아닌 standard backpropagation을 사용하는 계산가능한 식을 통해 구한다.
$$J_w^T y = \nabla_w (g(w) \cdot y)$$

Path Length Regularization을 사용하는 StyleGAN2가 StyleGAN 대비 더 낮은 PPL을 가지고 분포 역시 좁혀진다.
이렇게 구성된 smoother generator는 Section 5에서 이야기하는 inversion이 잘 된다.
자세한 식에 대한 내용은 Appendix C 참조.
spectral normalization을 generator에 사용하지 않은 이유도 기술(결론: 좋은 효과 없어서 안 씀. Appendix E 참조.)
4. Progressive growing revisited

Progressive growing 구조는 안정적인 고해상도 이미지 합성에 성공적인 방법이지만 characteristic artifacts가 야기된다. 특히, Phase artifacts(strong location preference)가 나타나는데 예를 들어 치아나 눈이 특정 위치에 고정된다.
저자들은 이것이 각 resolution이 output resolution에 대해 최대 frequency detail을 생성하고자 했기 때문이라고 본다.
즉, 낮은 해상도에서 maximum frequency detail을 생산해내고 이를 통한 위치적 고정이 일어났고 다음 해상도에서 이를 기반으로 이미지를 합성, 생성할 때 참조했기 때문에 이런 문제가 발생했다고 보는 것

4.1 Alternative network architectures
skip connection, residual network, hierarchical method를 기반으로 generator와 discriminator의 architecture를 변경.

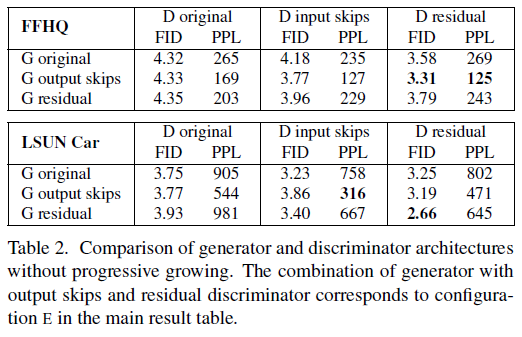
Table 2에서 확인할수 있듯
1) Generator의 경우 skip connection을 사용한 경우 PPL이 크게 개선 (Figure 7.(b) 위)
2) Discriminator의 경우 residual net을 사용하는 경우 좋은 결과를 얻음 (Figure 7. (c) 아래)
4.2 Resolution usage
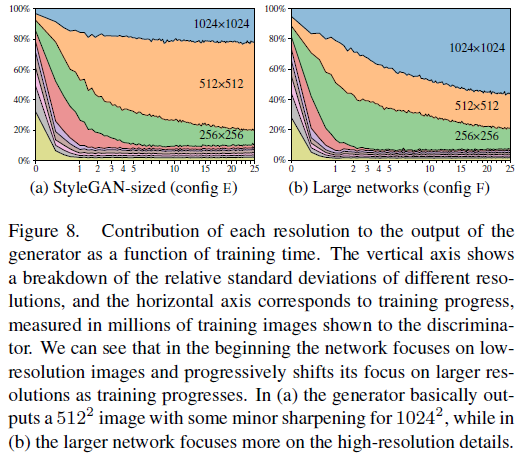
Figure 8은 각 tRGB layer에 의해 생성된 pixel value의 standard deviation을 normalize한 것
Figuree 8 (a)에서 볼 수 있듯 1024 해상도에 대한 pixel value detail이 부족하다.
이는 capacity problem으로 보고 양 network(generator, discriminator)의 feature map을 2배 증가한다.
이를 통해 Figure 8 (b)와 같이 1024에 대한 detail을 잘 살릴 수 있다.

Table 3은 이를 뒷받침하는 metric 비교이다.
resolution이 낮을 때조차 FID와 PPL의 성능이 StyleGAN 대비 StyleGAN2가 더 좋다.
5. Projection of images to latent space
1) 더 복잡한 latent space를 찾기 위해 optimization 동안 latent code에 rampled-down noise를 더한다.
2) StyleGAN generator의 stochastic noise 입력을 최적화하여 신호 간 간섭을 막도록한다.
Appendix D 참조

Figure 9는 생성된 이미지를 latent space로 projection한 후, 다시 이미지를 생성한 결과
StyleGAN2는 생성된 이미지가 원본과 같게 복원한다. 심지어 배경도 같음.
그러나 StyleGAN은 배경 및 일부 이미지가 달라진다.
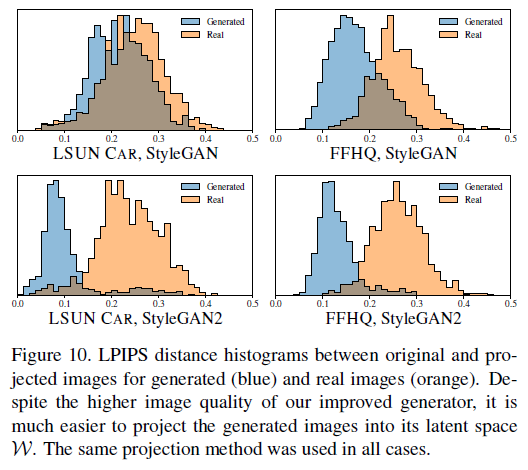
LPIPS distance를 통해 확인한 결과 역시 StyleGAN보다 StyleGAN2가 원본과 생성된 이미지간 구별을 더 잘 한다.
즉, Projection에 대하여 StyleGAN2가 더 월등한 성능을 보여준다.
총평

Baseline StyleGAN을 기반으로 앞서 언급한 방법론들을 하나씩 추가할 때마다 더 좋은 성과를 확인할 수 있다.

실험 GPU
NVIDIA DGX-1 with 8 Tesla V100 GPUs
Reference
공식 Github (Tensorflow)
https://github.com/NVlabs/stylegan2
GitHub - NVlabs/stylegan2: StyleGAN2 - Official TensorFlow Implementation
StyleGAN2 - Official TensorFlow Implementation. Contribute to NVlabs/stylegan2 development by creating an account on GitHub.
github.com
공식 Video
공식 블로그
Synthesizing High-Resolution Images with StyleGAN2 | NVIDIA Technical Blog
This new project called StyleGAN2, presented at CVPR 2020, uses transfer learning to produce seemingly infinite numbers of portraits in an infinite variety of painting styles.
developer.nvidia.com
도움이 되는 YouTube 1. 나동빈님 정리 유튜브
도움이 되는 블로그 1. Paper Review Blog by Jihye Back(조사일 기준 Naver Webtoon)
https://happy-jihye.github.io/gan/gan-7/
[Paper Review] StyleGAN2 : Analyzing and Improving the Image Quality of StyleGAN 논문 분석
기존의 stylegan을 발전시킨 nvidia research의 StyleGAN2에 대해 알아본다.
happy-jihye.github.io
Pytorch 버전 StyleGAN2 코드 by Kim Seonghyeon (조사일 기준 Naver CLOVA )
https://github.com/rosinality/stylegan2-pytorch
GitHub - rosinality/stylegan2-pytorch: Implementation of Analyzing and Improving the Image Quality of StyleGAN (StyleGAN 2) in P
Implementation of Analyzing and Improving the Image Quality of StyleGAN (StyleGAN 2) in PyTorch - GitHub - rosinality/stylegan2-pytorch: Implementation of Analyzing and Improving the Image Quality ...
github.com
0000
