[논문 Summary] MVDream (ICLR 2024 Poster) "MVDream: Multi-view Diffusion for 3D Generation"
[논문 Summary] MVDream (ICLR 2024 Poster) "MVDream: Multi-view Diffusion for 3D Generation"
논문 정보 (Citation, 저자, 링크)
Citation : 2024.11.03 일요일 기준 358회
저자 (소속) : ( Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, Xiao Yang ) [ByteDance, University of California, San Diego]
논문 & Github 링크 : [ Official ] [ Arxiv ] [ 공식 Github ] [ Project page ]
논문 Summary

0. 설명 시작 전 Overview
1. Introduction
3D Object Generation의 3가지 Types
(1) template-based generation pipeline
(2) 3D generative models
(3) 2D-lifting methods
(1), (2) 한계 : 3D model과 대규모 3D 데이터 복잡도로 인해 임의의 객체 생성을 효율적으로 일반화하는데 어려움이 있음.
(3)은 pre-trained 2D diffusion model을 사용하여 3D를 생성하는 방식으로 특히 SDS(Score distillation sampling)을 통한 3D 표현 최적화 진행.
e.g. Dreamfusion & Magic3D
(3) 한계 : score distillation 도중 포괄적인 multi-view knowledge 혹은 3D-awareness의 부족으로 문제 발생

(3) - (1) : multi-face Janus issue
(3) - (2) : content Drift across different view
이에 대한 이유로 사람은 객체에 대해 여러 각도에 대해 평가할 수 있지만, 2D diffusion model은 다양한 각도에서 객체를 평가할 수 없어 중복적이거나 일관적이지 않은 content 생성된다.
그럼에도 불구하고 large scale 2D data로 학습시킨 2D diffusion model은 3D 생성 일반화에 중요한 역할이기 때문에 3D prior를 기반한 3D 표현 multi-view diffusion model인 MVDream을 제안
방안 :multi 3D view images와 2D image-text pair data 기반으로 모델 학습 + score distillation
이를 통해 더 안정적이며 일반화 성능을 높일 수 있음
2. Related work
2.1 3D Generative Models
Dreamfusion, Magic3D, Rodin, Point-E, HoldDiffusion, Shap-E, ProlificDreamer
2.2 Diffusion Models for Object Novel View Synthesis
SparseFusion, Zero-1-to-3, GeNVS, Viewset Diffusion, MVDiffusion
2.3 Lifting 2D diffusion for 3D Generation
DreamFusion, SJC(Score Jacobian Chaining), Magic3D, Make-it-3D, Fantasia3D, ProlificDreamer, Dreamtime
3. Methods
3.1 Multi-view Diffusion Model

2D lifting diffusion model의 multi-view consistency 향상을 위한 기존 전형적인 해결법은 viewpoint-awareness 향상 방안 제공이다. e.g. text condition viewpoint 묘사 추가(e.g. front view, bird's eye view, top view, aerial perspective etc), camera parameter 통합
그러나 이 방법들조차 문제를 해결하기에는 충분하지 않음.
영감 : video diffusion model
인간은 3D 센서 없이 모든 각도에서 물체를 관찰하며 3D 객체를 인식하듯이, video diffusion model도 temporally consistent content 생성을 위한 방법을 통해 장면을 생성
그러나 이 방식을 바로 3D 방식에 도입시
문제 (1) : temporal consistency 대비 geometric consistency의 유지 어려움으로 인해 content drift 문제가 발생.
문제 (2) : dynamic scene을 훈련한 video diffusion model 대비 static scene를 생성하는 domain gap에 발생
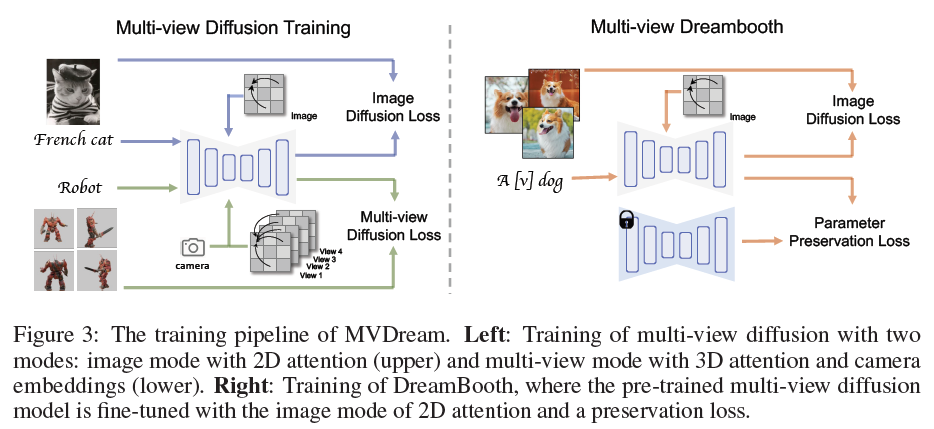
이에 따라 저자들은 3D render data를 활용하여 정확한 camera parameter로 static scene를 생성하도록 multi-view diffusion model 학습이 중요함을 발견. 3D dataset를 통해 consistent multi view image render 가능
Given
noisy image : $x_t \in R ^{F \times H \times W \times C}$
text prompt : $y$
extrinsic camera parameter (F different view angles) : $c \ in R^{F \times 16}$
After Multi-view Diffusion model Training, images : $x_0 \in R ^{F \times H \times W \times C} $
훈련 이후, 해당 model은 SDS와 함께 3D 생성을 위한 multi-view prior로 사용
2D diffusion model의 일반화 성질을 상속받기 위해 fine-tuning 진행 필요
그러나, 2D diffusion model은 한 번에 하나의 이미지를 생성 & camera condition을 입력으로 사용하지 않기에 아래 질문에 답을 해야함.
(1) how to generate a set of consistent images from the same text prompt (Sec. 3.1.1)
(2) how to add the camera pose control (Sec. 3.1.2)
(3) how to maintain the quality and generalizability (Sec. 3.1.3).
3.1.1 Multi-view Consistent Generation with Inflated 3D Self-Attention
video diffusion model과 같이
단순 temporal attention layer 적용 : multi-view consistency 학습 실패 & content drift 발생
3D attention 사용 (기존 2D self-attention 속 다른 view를 연결함으로써 3D로 inflate)
입력 tensor : $B \times F \times H \times W \times C$ -> $B \times FHW \times C$
기존 Self-Attention weight 상속
cf) 새로운 3D Self-Attention을 사용하는 방식은 품질 저하가 나타남을 실험을 통해 확인
3.1.2 Camera Embeddings
다른 view를 구분하기 위해 position encoding 필요
relative position encoding, rotary embeddings, absolute camera parameter 중 2 layer MLP embedding camera parameter 성능이 가장 좋음
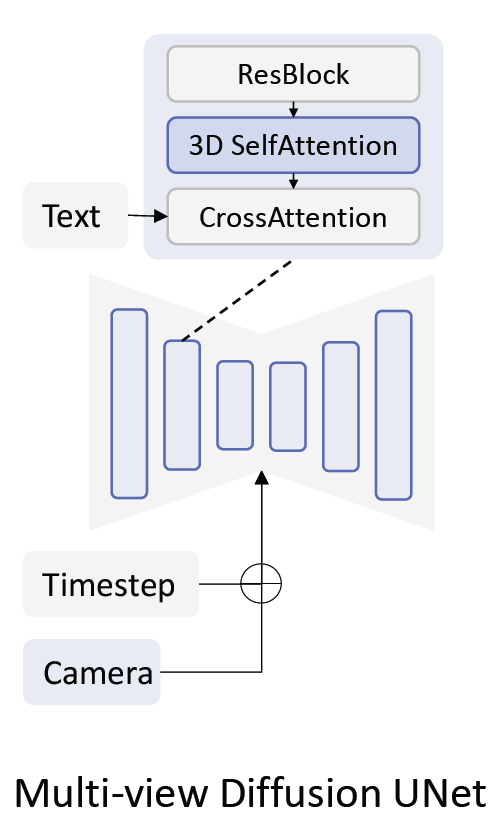
2가지 embedding 방식
(1) adding camera embeddings to time embeddings as residuals
(2) appending camera embeddings to text embeddings for cross attention.
(1) 방법이 text와 덜 묶이기(less entangled) 때문에 더 강건함을 보임
3.1.3 Training Loss Function
일반화 성능을 높이기 위해, 3D 렌더링 데이터와 대규모 2D 텍스트-이미지 데이터(예: LAION 데이터셋)를 결합하여 훈련
Fine-tuning
base model : Stable Diffusion v2.1 base model (512x512 -> 256x256)
setting : 기존 optimizer, $\epsilon$-prediction 유지
$\mathcal{X}$ : text-image dataset
$\mathcal{X}_{mv}$ : multi-view dataset

70% : 3D 렌더링 데이터로 훈련
30% : 3D attention과 camera embedding을 꺼둔 상태로 LAION dataset로 2D text-to-image model 훈련
3.2 Text-to-3D Generation
3D 생성을 위한 multi-view diffusion model 활용 2가지 방안 고려
(1) 생성된 multi-view 이미지를 few-shot 3D reconstruction 입력으로 사용하는 것
(2) SDS의 prior로 multi-view diffusion model을 사용하는 것
강건한 few-shot 3D reconstruction 필요성에 의해, 본 논문은 (2)에 초점을 맞춰 진행.
SDS pipeline 내 SD model을 저자들의 multi-view diffusion model로 교체.
수정 2가지
(1) camera sampling strategy 변경
(2) camera parameter를 입력으로 주입
- direction-annotated prompt를 사용했던 Dreamfusion과 달리 추출한 text embedding의 original prompt 사용
content 풍성함와 texture 품질 향상을 위한 추가 기술 3가지 제안
(1) SDS를 위한 최대, 최소 timestep linearly annealing (최적화 목적)
(2) SDS를 위한 소수의 고정 negative prompts 추가 (저품질 3D 모델 스타일 생성 방지)
(3) dynamic thresholding 또는 CFG rescale과 같은 clamping techniques 적용 (color saturation 완화 목적)
$x_0$ reconstruction loss

$x_0$ reconstruction loss는 기존 SDS와 동일하게 작동할 뿐 아니라 CFG rescale trick 적용후 color saturation 완화할 수 있음.
자세한 내용 : Appendisx A.2 x0 reconstruction loss for SDS 참조

다른 regularization loss 통합
point lighting (Dreamfusion), soft shading (Magic3D) (기하학적 결과물 향상)
orientation loss (Dreamfusion)
전경과 배경 분리를 위한 sparsity loss 사용하지 않으며 배경은 랜덤 색상으로 교체
이론적으로 다른 SDS variant와 조합할 수 있음. (SJC, VSD etc)

3.3 Multi-view Dreambooth for 3D Generation
3D Dreambooth application 확장
image fine-tuning loss & paramter preservation loss

$L_{LDM}$ : LDM loss
$\theta_0$ : multi-view diffusion 초기 parameter
$N_{\theta}$ : parameter 수
$\lambda$ : balancing parameter , set 1
3D model을 얻기 위해 diffusion model을 DreamBooth 모델로 교체 및 진행
multi-view DreamBooth 모델 학습 후 3D NeRF 최적화 진행
4. Experiments
32 A100 GPU - 3 days

temporal self-attention still suffers from content drift
Adding new 3D attention leads to severe quality degradation without learning consistency.
inflated 2D self-attention achieves the best consistency among all without losing generation quality.

combining 3D data with a 2D dataset (LAION) for joint training mitigates the problem

our multi-view model can generate images from unseen prompts

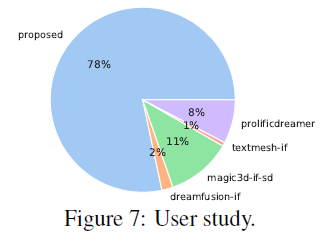






0000
